JVM C1 编译优化:空检查擦除
Posted raintungli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM C1 编译优化:空检查擦除相关的知识,希望对你有一定的参考价值。
1. 什么是空检查
在Java里经常会判断一个对象是否为空,如果为空的对象访问方法,字段会抛出空指针异常,而空指针异常为运行异常,如果不抓取这个异常,有的时候会导致程序异常,为了解决这个问题,我们通常会在代码里显式的去判断该对象是否为空,进行为空的逻辑处理,这种做法逻辑虽然明确,但是由于空的逻辑并不是经常碰到,这样会导致有多余的逻辑分支判断。
2. 隐式空检查 implicit exception
我们先来看一个代码:
public static int nullCheck(String value)
if(value == null)
return -1;
else
return value.length();
我们进行运行编译获取编译后的汇编
0x00007f23c922f107: mov 0xc(%rsi),%eax ; implicit exception: code begin: 0x00007f23c922f107; code end: 0x00007f23c922f10a; code end: 0x00007f23c922f0e0; implicit exception: dispatches to 0x00007f23c922f1a1
0x00007f23c922f10a: push %r10
0x00007f23c922f10c: cmp 0x15deda15(%rip),%r12 # 0x00007f23df01cb28我们并没有看到有逻辑分支对value.length中的value进行空指针判断,我们在旁边的注释中看到了构建了Implicit Exception的跳转地址 implicit exception: dispatches to 0x00007f23c922f1a1
mov 0xc(%rsi),%eax这个指令并不是一个跳转指令,但为何在旁边的代码注释中却标明了Implicit Exception呢?这是因为在Java编译的过程中会生成一段ImplicitNullCheckStub代码,用来处理遇到Null的场景。
;; ImplicitNullCheckStub slow case
0x00007f23c922f1a1: callq 0x00007f23c9166460 ; OopMapoff=198
;*invokevirtual length
; - NullCheck::hotMethod@7 (line 33)
; runtime_call
0x00007f23c922f1a6: mov %rsp,-0x28(%rsp)
0x00007f23c922f1ab: sub $0x80,%rsp
0x00007f23c922f1b2: mov %rax,0x78(%rsp)
0x00007f23c922f1b7: mov %rcx,0x70(%rsp)
0x00007f23c922f1bc: mov %rdx,0x68(%rsp)
0x00007f23c922f1c1: mov %rbx,0x60(%rsp)
0x00007f23c922f1c6: mov %rbp,0x50(%rsp)
0x00007f23c922f1cb: mov %rsi,0x48(%rsp)
0x00007f23c922f1d0: mov %rdi,0x40(%rsp)
0x00007f23c922f1d5: mov %r8,0x38(%rsp)
0x00007f23c922f1da: mov %r9,0x30(%rsp)
0x00007f23c922f1df: mov %r10,0x28(%rsp)
0x00007f23c922f1e4: mov %r11,0x20(%rsp)
0x00007f23c922f1e9: mov %r12,0x18(%rsp)
0x00007f23c922f1ee: mov %r13,0x10(%rsp)
0x00007f23c922f1f3: mov %r14,0x8(%rsp)
0x00007f23c922f1f8: mov %r15,(%rsp)
0x00007f23c922f1fc: movabs $0x7f23de9c944b,%rdi ; external_word
0x00007f23c922f206: movabs $0x7f23c922f1a6,%rsi ; internal_word
0x00007f23c922f210: mov %rsp,%rdx
0x00007f23c922f213: and $0xfffffffffffffff0,%rsp
0x00007f23c922f217: callq 0x00007f23de53c7a0 ; runtime_call
0x00007f23c922f21c: hlt
那什么时候会触发ImplicitNullCheckStub的调用呢?因为Mov指令当碰到无效地址的时候,在Linux系统中会产生一个发生signalled exception(在这种情况下是SIGSEGV),这时候会转到信号处理函数,如果应用有自定义的该信号处理函数,就执行该信号处理函数。JVM在linux下注册了JVM_handle_linux_signal函数
else if (sig == SIGSEGV &&
!MacroAssembler::needs_explicit_null_check((intptr_t)info->si_addr))
// Determination of interpreter/vtable stub/compiled code null exception
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
在continuation_for_implicit_exception函数里,通过当前异常地址获取target_pc = nm->continuation_for_implicit_exception(pc);地址,把地址内容保存到信号处理函数的context中
if (stub != NULL)
// save all thread context in case we need to restore it
if (thread != NULL) thread->set_saved_exception_pc(pc);
uc->uc_mcontext.gregs[REG_PC] = (greg_t)stub;
return true;
由linux的信号处理来跳转到指定的stub中,也就是ImplicitNullCheckStub
在这里我们看到JVM并没有显示的增加指令分支对Null进行检查,而是通过异常信号处理机制来处理,跳转到ImplicitNullCheckStub里单独处理这里是有性能的损耗,为何JVM里会考虑使用异常信号处理机制,是因为考虑到大部分的场景不为空,提高执行效率的一种方式。
3. C1的Null Eliminator
C1的Null Eliminator 于C2不太一样, C1 的Null Eliminator 解决的是重复check null的问题。
整体思路:
- 显式的调用Nullcheck的时候,需要将显式的NullCheck擦除,改成ImplicitNullCheck
- 对同一个参数使用不需要每次都引入null检查,只要在第一次检查后,后续就可以将null检查给插除了。
算法:数据流分析
OUT[entry] = ∅;
for (each basic block B\\entry)
IN[B] = U P a predecessor of B OUT[P];
if (changes to IN occur))
OUT[B] = genB U (IN[B]);
C1是使用SSA的表达方式,我们会发现没有了传统流分析算法里的Kill函数,在SSA里的use-define链路里如果一个参数如果进行redfine过后,参数的命名会变化,在使用的时候就已经使用新的参数名字,这样就天生具备了kill的能力。
我们先来看一个SSA的例子:
. 18 0 a13 null_check(a3)
. 1 0 a16 a3._12 ([) value
. 4 0 i17 a16.length
. 21 0 i19 ireturn i17Null Eliminator 分析的是value,在上面的第一行首先现有Null_Check,这是在调用函数的时候,IR层添加了null_check,根据算法我们会显示的去除null_check a3 并设置为implicit null检查,而对第二句语句 a16 使用了a3 并且又跟在a13语句后面,故而可以直接使用第一个语句的implicit null check,而把第一个语句null check 彻底的擦除,假如后续的语句继续使用a3的化,那么该语句的implicit null check 就可以直接擦除了。
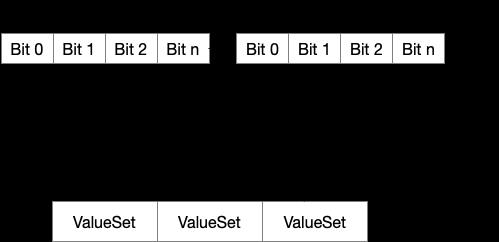
算法其实和常见的流分析一样,设置一个ValueSet,对每个参数的下标以bit位置来保存,同时每一个Block都会保存一个ValueSet
算法实现细节:
- Null Eliminator 是一个前向分析
- 分析流从不同的BB块流向的时候,每个Block都会Uion 上一个Block块ValueSet
- 如果发现变化,就会对Block里的指令进行遍历分析
- 分析指令里的Value参数
- 该参数已经在bitset里被设置过,就代表已经做过Null check
- 如果前面的指令做的是显式的null check,那么插除的就是显示的null check,补上Implicit null check
- 如果前面的指令做的是Implicit null check,那么该null check将会被Eliminator
3.1 Null Check Eliminator
void handle_AccessField (AccessField* x);
void handle_ArrayLength (ArrayLength* x);
void handle_LoadIndexed (LoadIndexed* x);
void handle_StoreIndexed (StoreIndexed* x);
void handle_NullCheck (NullCheck* x);
void handle_Invoke (Invoke* x);
void handle_NewInstance (NewInstance* x);
void handle_NewArray (NewArray* x);
void handle_AccessMonitor (AccessMonitor* x);
void handle_Intrinsic (Intrinsic* x);
void handle_ExceptionObject (ExceptionObject* x);
void handle_Phi (Phi* x);
void handle_ProfileCall (ProfileCall* x);
void handle_ProfileReturnType (ProfileReturnType* x);在上面函数里定义的我们可以看到访问field, array, 显示的null check, 调用, 初始化对象,异常对象,以及phi函数
我们为这里单独的讨论一下phi函数:关于Phi函数是什么,在这里我们就不介绍了:先来看一段IR
B2 (V) [22, 31] pred: B10 B1
Locals:
0 a3
1 a18 [ a4 a10]
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
. 23 0 i19 a18._12 (I) x
. 27 0 a20 null_check(a3)
. 1 0 a23 a3._12 ([) value
. 4 0 i24 a23.length
30 0 i26 i19 + i24
. 31 0 i27 ireturn i26我们可以看到a18 phi参数里面决定的是a4 a10。分析Phi函数需要分析a4, a10,如果a4, a10都已经进行空检查过,那么该a18也就可以进行null Eliminator
3.2 C2 Null 优化
C2的null优化和C1的优化是不一样的,C2的Null优化会优化Block,通过Profile可以推断分支是否会被执行,如果不会被执行,分支将会被剪支。但如果发现剪支错误,会进行反优化,重新回到解释。
但是C1是不会的,C1的优化并不会剪支,当程序碰到大量的Null的时候,会执行implicit的分支,从而大大降低效率,这里需要人工的去判断,究竟是Null多 还是非Null多,如果Null多的化,还是建议代码里添加null 的检查,避免效率的大大降低。
以上是关于JVM C1 编译优化:空检查擦除的主要内容,如果未能解决你的问题,请参考以下文章