Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Posted Facico
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval相关的知识,希望对你有一定的参考价值。
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
密集检索 (DR) 的有效性通常需要与稀疏检索相结合
-
主要瓶颈在训练机制,训练中使用的负面实例不能代表不相关文档,如下图所示

-
本文介绍最邻近负对比估计(ANCE):从语料库的最邻近(ANN)索引构造负样本的计件制,该索引与学习过程并行更新以选择更真实的负样本(这种方式从根本上解决了DR训练和测试中数据分布间的差异)
- **简单的说就是用已经有的DR模型,来刷negative sample(**很多工作告诉你数据中加入hard negative sample对结果的提升是非常有效的)
实验中,ANCE提升了BERT-Siamese DR 模型到超过所有计算密集检索系数的baseline。效果和用点积的sparse-retrieval-and-BERT-reranking相匹配,并提速将近100倍。
方法
负样本有两种
- 1、容易判别的
- 2、难判别的,学习这种对于对比学习的帮助更大
在对比学习的思想中,我们希望使用一些方法检索这些难判别的负样本来增强模型的效果
ANN检索
一个标准的DR(dense retrieval)结构会使用孪生或dual-encoder结构,如下

- 这个编码器在最后一层的[CLS]用一个LN映射,这个权重是q和d共享的
DR使用ANN(Approximate nearest neighbor)搜索能有好的效果
 -
-
D R ( q , ⋅ ) DR(q,\\cdot) DR(q,⋅)指的是由DR对q检索来的文档,这些文档来自模型 A N N f ( q , d ) ANN_f(q,d) ANNf(q,d)得来的index
这样的方法有几个特性:
- 1、可学习性:DR中的representation得到充分的学习
- 2、高效性:DR中,文档的representation可以预先计算。此外,询问只用在线编码,并用ANN检索就能得到很多好的结果
DR中representation的学习
loss如下

常规的方法,对
D
−
D^-
D−的采样如下

在DR中,由于最优的负样本在重排序中不同于这些样本,所以还会随机采样一些样本加入,如下
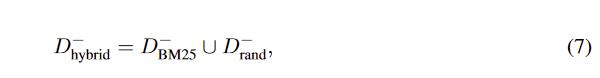
由于大多数文档与查询无关,所以随机采样的也不太可能命中相关的负样本
ANCE(Approximate Nearest Neighbor Noise Contrastive Estimation)
在构建算法的时候,要考虑如何对齐训练和测试时的数据分布,即我们如何异步地学习它

ANCE使用了标准的DR模型和损失函数

唯一不同的是训练时的负样本
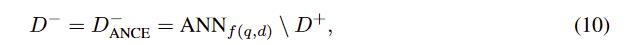
- ANN搜索出的index使用学习到的representation模型f(),这使得推理的时候和训练的时候相同,消除了这之间的数据分布差异
异步训练
因为训练是随机的,encoder f会每步都更新,要更新ANCE的负样本( D A N C E − D_ANCE^- DANCE−),要以下两步
- 1、inference:用新的encoder来更新所有文档的representation
- 2、index:用更新后的representation来重构ANN index
重构ANN index可以使用一些library,但是这样在推理的时候成本高昂,需要对他们re-encode。
- 所以这里的ANCE,只在每k个checkpoint后重构ANN index,即
- 1、取出最近的checkpoint f k f_k fk
- 2、使用 f k f_k fk推理整个语料库,此时的负样本是 D f k − 1 − D_f_k-1^- Dfk−1−,来自 A N N f k − 1 ANN_f_k-1 ANNfk−1
- 3、重构ANN index( A N N f k ANN_f_k ANNfk),得到 D f k − D_f_k^- Dfk−
每个checkpoint中有m个batch,m为可调的超参;m=1时可以同步更新,但是太慢;m=∞时则不更新
实验
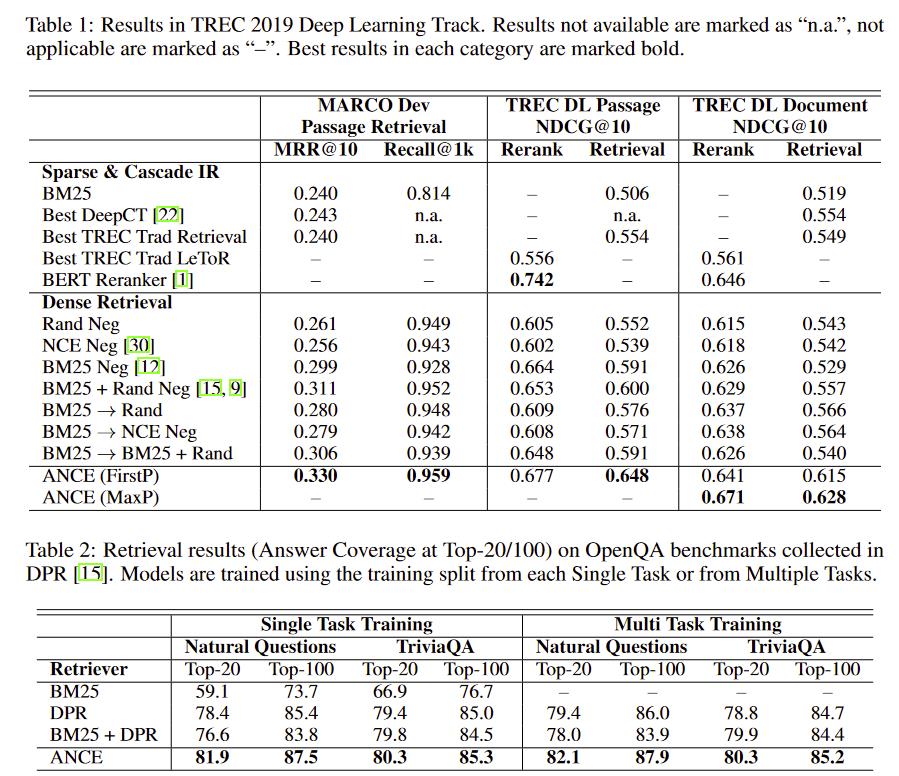
有所提升
效率
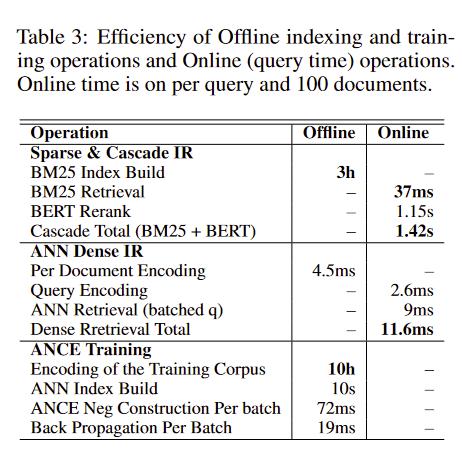
- ANCE在线只用11.6ms,提升百倍
- 文档编码可以离线完成,每个文档平均4.5ms
训练测试一致性

有较高的一致性
以上是关于Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval的主要内容,如果未能解决你的问题,请参考以下文章