机器学习实战——训练模型
Posted 哈喽喔德
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习实战——训练模型相关的知识,希望对你有一定的参考价值。
本章从线性回模型开始介绍两种不同的训练模型的方法:
- 通过“闭式”方程,直接计算出最拟合训练集的模型参数(也就是使训练集上的成本函数最小化的模型参数)
- 使用迭代优化的方法,即梯度下降,逐渐调整模型参数直至训练集上的成本函数调至最低,最终趋同于第一张放啊计算出来的模型参数。
然后讨论多项式回归,参数比线性模式更多,更容易造成对训练数据过拟合,将通过学习曲线分辨这种情况的发生。
最后学习两种经常用于分类任务的模型:Logistic回归和Softmax回归。
4.1 线性回归
线性模式就是对输入特征加权求和,再加上一个偏置项的常数,以此进行预测。
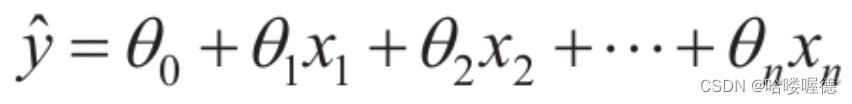
在此等式中:
- y是预测值
- n是特征数量
- Xi是第i个特征值
- θj是第j个模型参数
也可以用向量形式更简洁的表示:
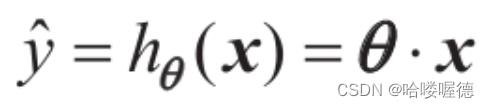
在此等式中:
- θ是模型的参数向量,其中包含偏差项θ0和特征权重θ1至θn
- X是实例的特征向量,包含从x0到xn,x0始终等于1
- θx是向量θ和x的点积,它当然等于θ0x0+θ1x1+θ2x2+…+θnxn。
- hθ是假设函数,使用模型参数θ
这就是线性回归模型,训练模型就是设置模型参数直到模型最拟合训练集的过程。回归模型最常见的性能指标是均方根误差RMSE,因此在训练线性回归模型时,需要找到最小化RMSE的θ。通常在实际中是使MSE最小,自然RMSE也最小。线性模型的MSE成本函数如下:

标准方程
为了得到使成本函数最小的θ值,有一个闭式解方法——也就是一个直接得出结果的数学方程,即标准方程:

在这个方程中:
- θ是使得成本函数最小的参数值
- y是包含y1到ym的目标值向量
我们可以通过以下的代码测试这个方程:
import numpy as np
import matplotlib.pyplot as plt
# 随机生成线性数据集
X = 2*np.random.rand(100,1)
y = 4+3*X +np.random.rand(100,1)
# 绘制随机数据集
plt.plot(X, y, "b.")
plt.xlabel("$x_1$")
plt.ylabel("$y$", rotation=0)
plt.axis([0, 2, 0, 15])
plt.show()
# 使用标准方程计算截距和系数值向量
X_b = np.c_[np.ones((100,1)), X]
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
print(theta_best)
# 使用上述值进行预测
X_new = np.array([[0],[2]])
X_new_b = np.c_[np.ones((2,1)), X_new]
y_predict = X_new_b.dot(theta_best)
print(y_predict)
# 绘制预测结果
plt.plot(X_new, y_predict, "r-")
plt.plot(X, y, "b.")
plt.axis([0, 2, 0, 15])
plt.show()
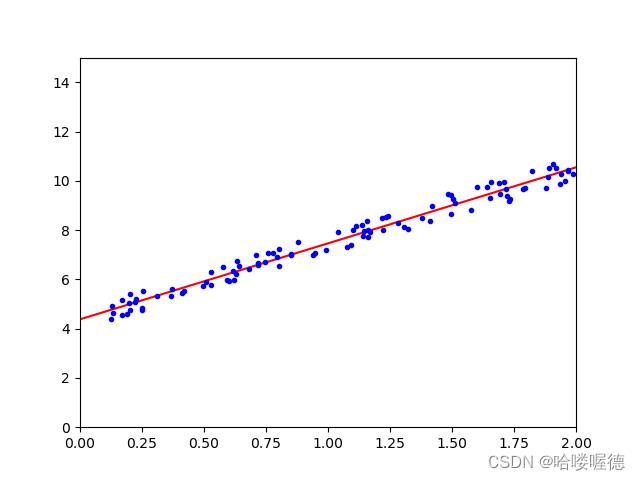
如果使用Sklearn执行线性回归则很简单:
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X, y)
print(lin_reg.intercept_, lin_reg.coef_)
4.2 梯度下降
梯度下降是一种非常通用的优化算法,能够为大范围的问题找到最优解。梯度下降的中心思想就是迭代调整参数从而使成本函数最小化。
梯度下降的做法是:通过测量参数向量θ相关的误差函数的局部梯度,并不断沿着降低梯度的方向调整,直到梯度降为0,到达最小值。首先使用随机的一个θ值,然后逐步改进,每次踏出一步,每次都尝试降低一点成本函数,直到算法收敛出一个最小值。

梯度下降中一个重要参数是每一步的步长,这取决与超参数学习率,如果学习率太低,算法需要经过大量迭代才能收敛,将耗费很长时间。如果学习率太高,可能会直接越过山谷到达另一边,甚至比之前的七点还高,导致算法发散,值越来越大。

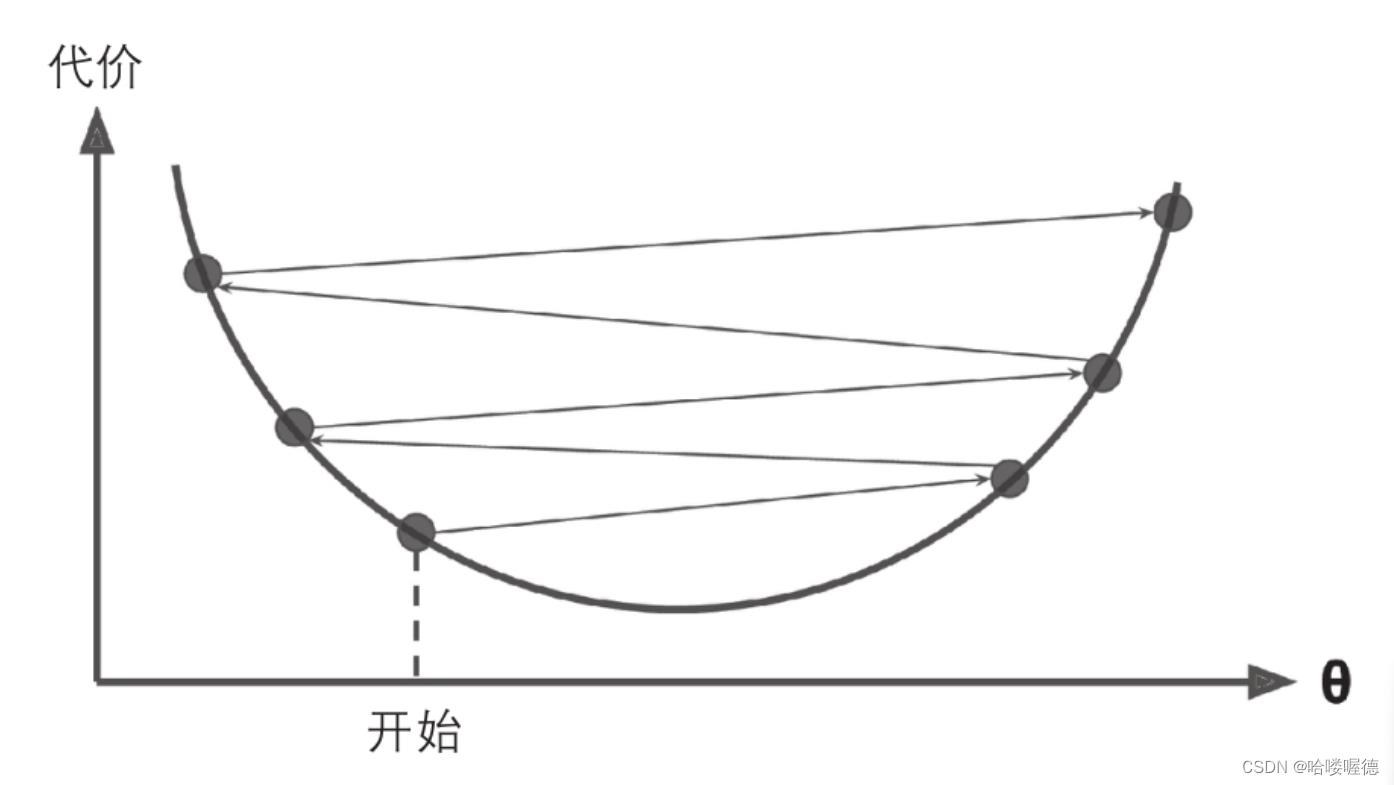
最后并不是所有的成本函数都只有一个最小值,不规则的函数会导致很难收敛到最小值。如果随机初始化,算法从左边起步,那么会收敛到一个局部最小值,而不是全局最小值。如果算法从右边起步,那么需要经过很长时间才能越过整片高原,如果停下太早,将永远达不到全局最小值。
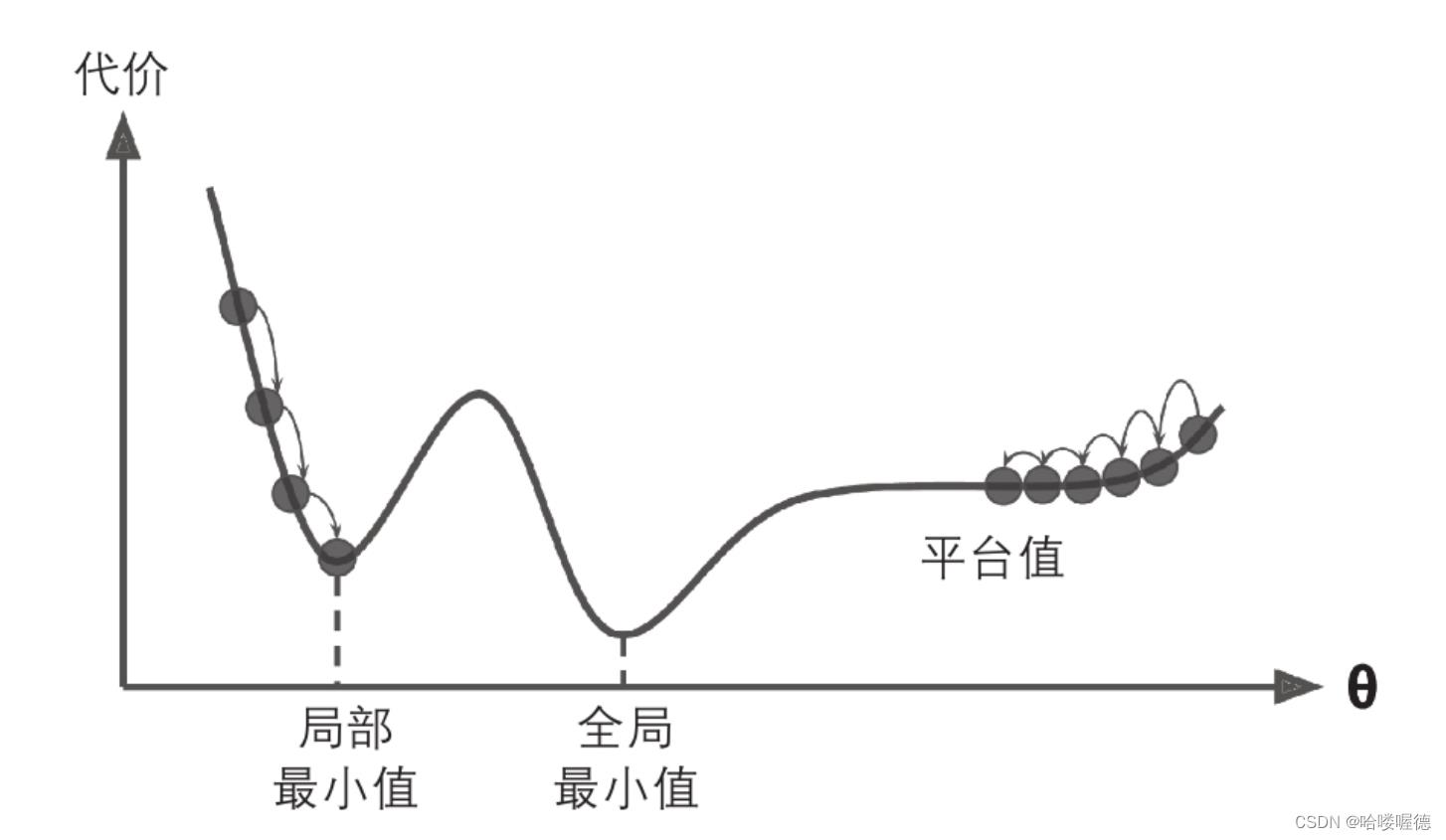
幸运的是线性回归模型的MSE成本函数就是一个普通的凹函数,即使是乱走也能趋近全局最小值。
应用梯度下降时,需要保证所有特征值的大小比例都差不多,否则收敛的实践会长很多。
批量梯度下降
要实现梯度下降,需要计算每个参数对于成本函数的梯度影响。换言之计算的是每一种参数的偏导数。

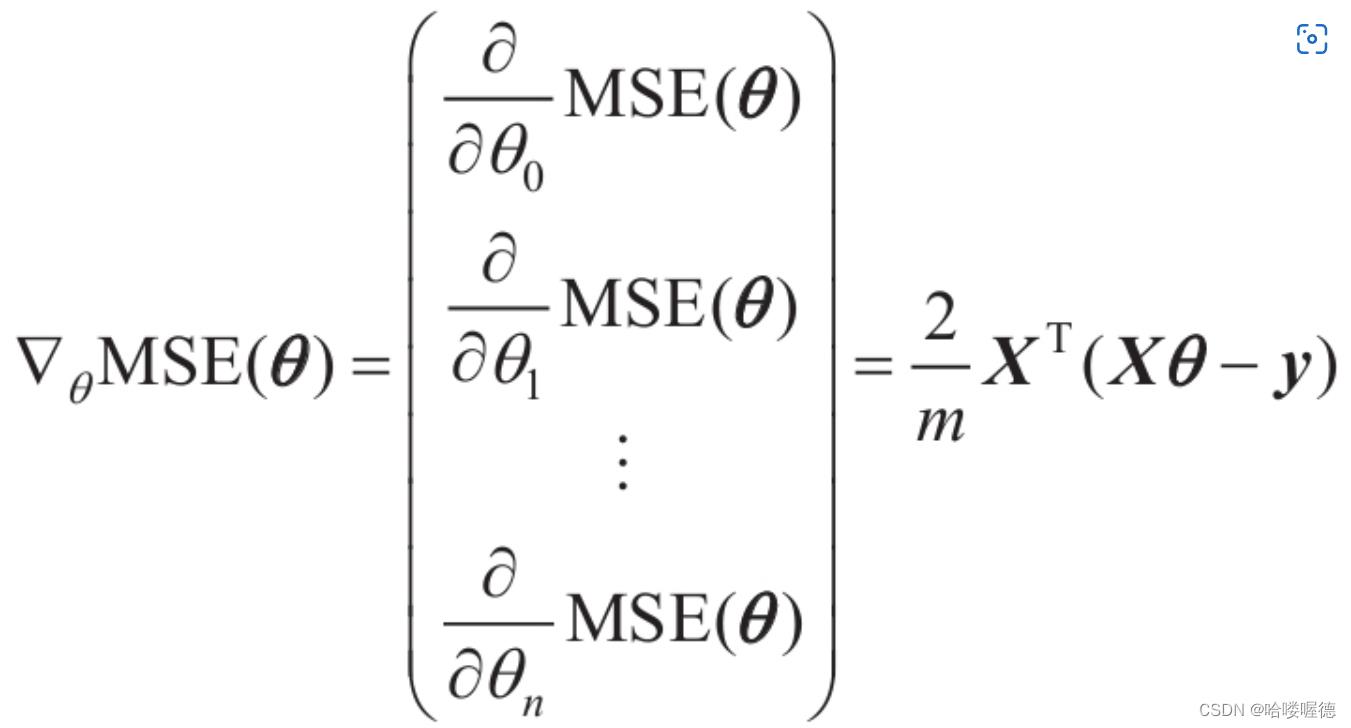
计算梯度下降的每一步时,都是基于完整的训练集X的。这就是为什么该算法会被称为批量梯度下降:每一步都是用整批训练数据。因此面对非常庞大的数据集时,算法会变得极慢。但是梯度下降算法随特征数量拓展的表现较好,如果训练的模型拥有几十万个特征,使用梯度下降比使用标准方程或者SVD要快得多。
一旦有了梯度向量,哪个点向上,就朝反方向下坡,也就是从θ中减去▽θMSE(θ)。这时候学习率η乘以梯度向量确定下坡步长的大小。该算法的公式和快速实现如下:

eta = 0.1
n_iterations = 1000
m = 100
theta = np.random.rand(2,1)
for iteration in range(n_iterations):
gradients = 2/m*X_b.T.dot(X_b.dot(theta)-y)
theta = theta-eta*gradients
print(theta)
下面是学习率态度和学习率合适以及学习率太高的三种情况:

要找到合适的学习率可以使用网格搜索。但是可能需要限制迭代次数,这样网格搜索可以淘汰掉那些收敛耗时太长的模型。
随机梯度下降
批量梯度下降的主要问题是它要用整个训练集来计算每一步的梯度,所以训练集很大时,算法会特别慢。与之相反的极端是随机梯度下降,每一步在训练集中随机选择一个实例,并且仅基于该单个实例来计算梯度。每次迭代的数据少,算法自然也快得多。
另外由于算法的随即特性,成本函数一直在上上下下,从整体看最终会接近最小值,但是到了最小值,依旧会持续反弹,停下来的参数是足够好的,但不是最好的。当成本函数变得非常不规则时,随机梯度下降还会帮助算法跳出局部最小值,所以相比批量梯度下降,它对找到全局最小值更有优势。
随机梯度下降的好处在于可以逃离局部最优,但缺点是永远定位不出最小值。要解决这个困境,有一个办法是逐步降低学习率。开始的步长比较大,然后越来越小,让算法尽量靠近全局最小值。确定每个迭代学习率的函数叫做学习率调度。下面实现了一个简单的学习率调度实现随机梯度下降:
n_epochs = 50
t0, t1 = 5,50
def learning_schedule(t):
return t0/(t+t1)
theta = np.random.rand(2,1)
for epoch in range(n_epochs):
for i in range(m):
random_index = np.random.randint(m)
xi = X_b[random_index:random_index+1]
yi = y[random_index:random_index+1]
gradients = 2*xi.T.dot(xi.dot(theta)-yi)
eta = learning_schedule(epoch*m+i)
theta = theta-eta*gradients
print(theta)
使用随机梯度下降时,需要保证训练实例独立且均匀分布,以确保平均而言的将参数蜡像全局最优值。确保这一点的一种简单方法是在训练过程中对实例进行随机混洗。要使用带有sklearn的随机梯度下降执行线性回归,可以使用SGDRegressor类,该类默认优化评分误差成本函数。
from sklearn.linear_model import SGDRegressor
sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1) # 最多运行1000轮次或损失下降小于0.001为止,以0.1的学习率开始
sgd_reg.fit(X, y.ravel())
print(sgd_reg.intercept_, sgd_reg.coef_)
小批量梯度下降
在每一步中,不是根据完整的或者仅一个实例的训练集来计算梯度,小批量梯度下降优于随机梯度下降的主要优点是,可以通过矩阵操作的硬件优化来提供性能,特别是在使用GPU时。
与随机梯度下降相比,这种算法在参数空间上的进展更稳定,尤其是在相当大的小批次中。结果,小批次梯度下降最终将比随机下降走得更接近最小值,但仍然很难拜托局部最小值。
下面是我们学习到的线性回归算法的比较:

4.3 多项式回归
如果数据比直线更复杂,可以使用线性模型来拟合非线性数据。一个简单的方法是将每个特征的幂次方添加为一个新特征,然后在此跨站特征及上训练一个线性模型。这种技术被称为多项式回归。例如下面基于一个简单的二次方程式生成一些非线性数据:
m = 100
X = 6*np.random.rand(m,1)-3
y = 0.5*X**2+X+2+np.random.rand(m,1)
plt.plot(X, y, "b.")
plt.xlabel("$x_1$", fontsize=18)
plt.ylabel("$y$", rotation=0, fontsize=18)
plt.axis([-3, 3, 0, 10])
plt.show()

显然一条直线永远也无法正确拟合此数据。因此,我们可以使用Sklearn的PolynomiaFeatures类来转换训练数据,将训练集中的每个特征的平方添加为新特征。
from sklearn.preprocessing import PolynomialFeatures
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
print(X[0], "\\n", X_poly[0])
现在X_poly包含了原始的X特征和该特征的平方,可以将LinearRegression模型拟合到此扩展训练数据中:
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_poly, y)
print(lin_reg.intercept_, lin_reg.coef_)
当存在多个特征时,多项式回归能找到特征之间的关系(这是普通线性回归模型无法做到的),PolynomiaFeatures还可以将特征的所有组合添加到给定的多项式阶数。
4.4 学习曲线
高阶多项式回归与普通线性回归相比,拟合数据可能会更好,但也同样更容易造成过拟合。判断模型是否过拟合和欠拟合在交叉验证中提到过:如果模型在训练数据上表现良好,但根据交叉验证的指标泛化较差,说明过拟合;如果两者表现均不理想,则说明欠拟合。
其实还有一种方式是观察学习曲线:这个曲线绘制的是模型在训练集和验证集上关于训练集大小的性能函数。要生成这个曲线,只需要在不同大小的训练子集上多次训练模型即可。下面这段代码给训练集下定义了一个函数,绘制模型的学习曲线:
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def plot_learning_curves(model, X, y):
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
train_errors, val_errors = [],[]
for m in range(1, len(X_train)):
model.fit(X_train[:m], y_train[:m])
y_train_predict = model.predict(X_train[:m])
y_val_predict = model.predict(X_val)
train_errors.append(mean_squared_error(y_train[:m], y_train_predict))
val_errors.append(mean_squared_error(y_val, y_val_predict))
plt.plot(np.sqrt(train_errors), "r+", linewidth=2, label="train")
plt.plot(np.sqrt(val_errors), "b-", linewidth=3, label="val")
lin_reg = LinearRegression()
plot_learning_curves(lin_reg, X, y)
plt.show()

当训练集中只有一个或两个实例时,模型可以很好的拟合,这也就是曲线从0开始的原因。但是,随着将新实例添加到训练集中,模型就不可能完美的拟合训练数据,这既因为数据有噪声,又因为它根本不是线性的。因此误差会一直上升,直至平稳状态。这两条学习曲线是典型的欠拟合模型,两条曲线都达到了平稳状态,它们很接近而且很高。
下面是相同数据上的10阶多项式模型的学习曲线:
from sklearn.pipeline import Pipeline
polynomial_regression = Pipeline([
("polu_features", PolynomialFeatures(degree=10, include_bias=False)),
("lin_reg", LinearRegression()),
])
plot_learning_curves(polynomial_regression, X, y)
plt.axis([0, 80, 0, 3])
plt.show()

这点曲线跟上面的曲线有两个非常重要的区别:
- 与线性回归模型相比,训练数据上的误差要低得多
- 曲线之间存在间隙,这是过拟合的标志
改善过拟合模型的一种方法是向其提供更多的训练数据,直到验证误差达到训练误差为止。
4.5 正则化线性模型
减少过拟合的一个好方法是对模型及逆行正则化(即约束模型):它拥有的自由度越少,则拟合数据的难度越大。正则化多项式模型的一种简单方法是减少多项式的次数。对于线性模型,正则化通常是通过约束模型的权重来实现的。下面有三种方式实现了限制权重的方法。
岭回归
岭回归是线性回归的正则化版本,这迫使学习算法不仅拟合数据,而且还使模型权重尽可能小。注意仅在训练期间将正则化项添加到成本函数中。训练完模型后,要使用非正则化的性能度量来评估模型的性能。
训练过程中使用的成本函数与用于测试的性能指标不同很常见,其中有一个原因是:好的训练成本函数应该具有对优化友好的导数,而用于测试的性能指标应尽可能接近最终目标。
超参数a控制要对模型进行正则化的程度。如果a=0,则岭回归仅是线性回归;如果a非常大,则所有权重最终都非常接近于零,结果是一条经过数据均值的平线。岭回归成本函数如下:
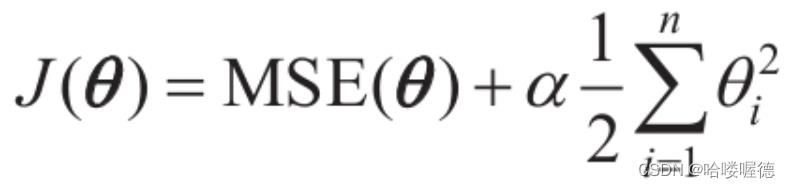
在执行岭回归之前放缩数据很重要,因为它对输入特征的缩放敏感。
下图展示了不同的a值对某些线性数据进行训练的几种岭模型。左侧使用的是普通岭模型,导致了线性预测。右侧先使用PolynomialFeatures扩展数据,然后使用StandardScaler进行缩放,最后将岭模型应用于结果特征:这是带有岭正则化的多项式回归。请注意,a的增加会导致更平滑的预测,从而减少了模型的方差,但增加了偏差。

与线性回归一样,可以通过计算闭合形式的方程或执行梯度下降来执行岭回归。以下是用Sklearn和闭式解来执行岭回归的方法:
from sklearn.linear_model import Ridge
ridge_reg = Ridge(alpha=1, solver="cholesky")
ridge_reg.fit(X, y)
print(ridge_reg.predict([[1.5]]))
sgd_reg = SGDRegressor(penalty="l2")
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict([[1.5]]))
超参数penalty设置的是使用正则项的类型。设为“l2”表示希望SGD在成本函数中添加一个正则项,等于权重向量的l2范数的平方的一半,即岭回归。
Lasso回归
线性回归的另一种正则化叫做最小绝对收缩和选择算子回归,简称Lasso回归。与岭回归一样,它也是向成本函数添加一个正则项,但是它增加的是权重向量的l1范数,而不是l2范数的平方的一半。Lasso回归成本函数如下:
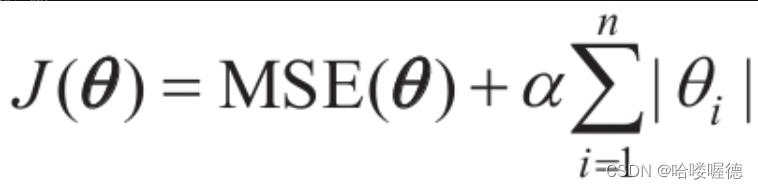
Lasso回归的一个重要特点是它倾向于完全消除掉最不重要特征的权重(也就是将它们设置为0)。Lasso回归会自动执行特征选择并输出一个稀疏模型。Lasso有两个主要区别:
- 随着参数接近全局最优值,梯度会变小,梯度下降会减慢,有助于收敛。
- 当增加a时,最佳参数越来越接近原点,但是从未被完全消除。
为了避免Lasso在梯度下降时最终在最优解附近反弹,你需要逐渐降低训练期间的学习率(它仍然会在最优解附近反弹,但是步长会越来越小,因此会收敛)。
Lasso成本函数在theta_i=0处不可微,但是如果使用子梯度向量g代替任何theta_i=0,则梯度下降仍然可以正常工作。下式显示了可用于带有Lasso成本函数的梯度下降的子梯度向量方程。

下面是使用Lasso类的sklearn示例:
from sklearn.linear_model import Lasso
las_reg = Lasso(alpha=0.1)
las_reg.fit(X, y)
print(las_reg.predict([[1.5]]))
弹性网络
弹性网络是介于岭回归和Lasso回归之间的中间地带。正则项是岭和Lasso正则项的简单混合,可以控制混合比例r。当r=0时,弹性网络等于岭回归;当r=1时,弹性网络等效于Lasso回归。弹性网络成本函数如下:

对于这几种线性回归的使用场景,通常来说,有正则化都比没有更可取,所以大多数情况下要避免使用纯线性回归。岭回归是一个不错的选择,但是实际用到的特征较少,那么更倾向于使用Lasso和弹性网络,因为他们将无用特征的权重降为0。一般来说,弹性网络优于Lasso回归,以为特征数量超过训练实例数量,又或者说几个特征强相关时,Lasso回归的表现可能非常不稳定。
下面是基于sklearn弹性网络的示例,l1_ration对应于混合比r:
from sklearn.linear_model import ElasticNet
elastic_reg = ElasticNet(alpha=1, l1_ratio=0.5)
elastic_reg.fit(X, y)
print(elastic_reg.predict([[1.5]]))
提前停止
对于梯度下降这类迭代学习的算法,还有一个与众不同的正则化方法,就是在验证误差达到最小值时停止训练,该方法叫做提前停止法。
和下图展示了用批量梯度下降的高阶多项式回归模型,经过迭代后,训练集上的RMSE不断下降,验证机集上的RMSE也下降,但是到达最低点后升高,说明进入了过拟合。通过提前停止法,一旦验证误差达到最小值就立即停止训练。
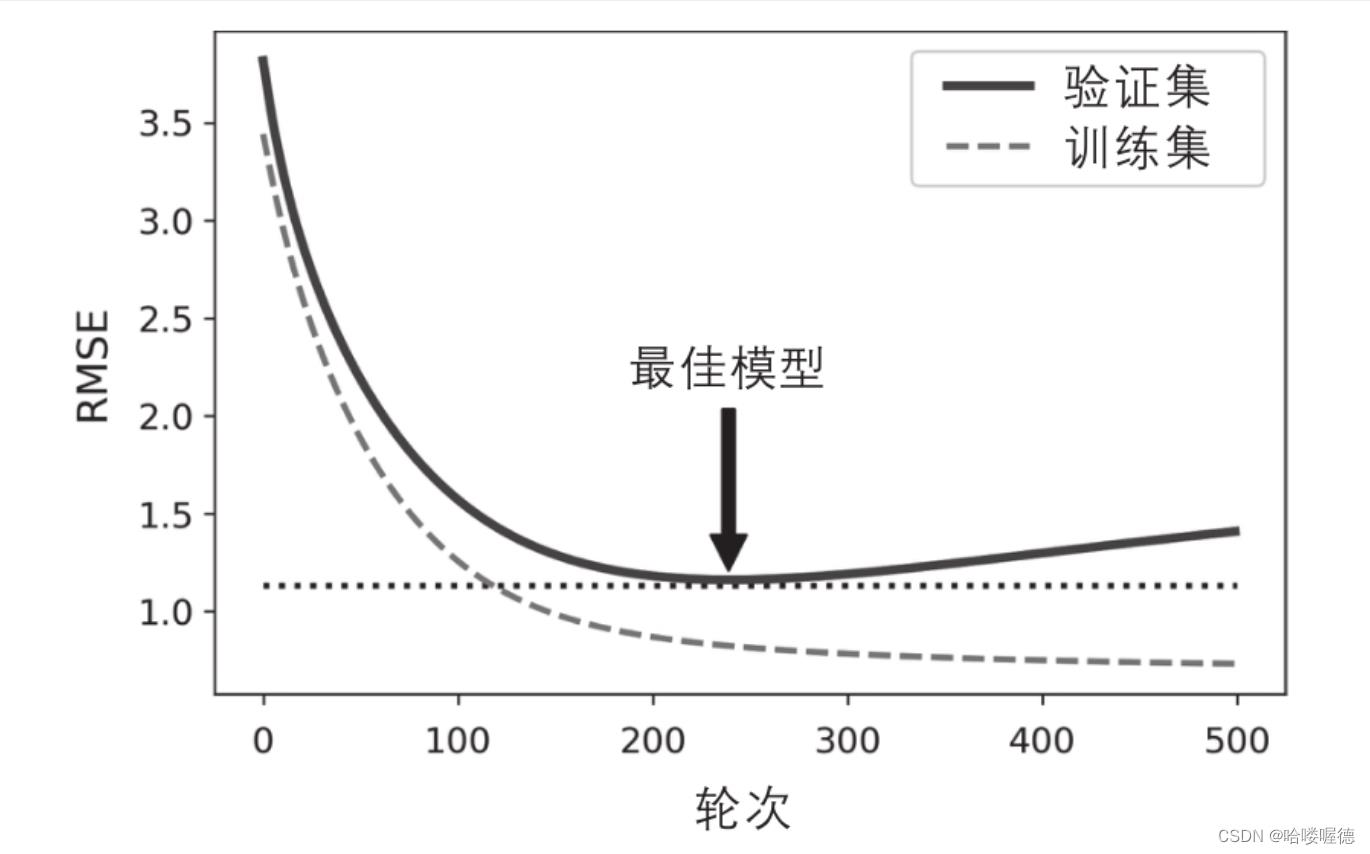
使用随机和小批量梯度下降时,曲线不是那么平滑,可能很难知道是否达到了最小值。一种解决方法啊是仅在验证错误超过最小值一段时间后停止,然后回滚模型参数到验证误差最小的位置。
from sklearn.base import clone
from sklearn.preprocessing import StandardScaler
poly_scaler = Pipeline([
("poly_features", PolynomialFeatures(degree=90, include_bias=False)),
("std_scaler", StandardScaler())
])
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
X_train_poly_scaled = poly_scaler.fit_transform(X_train)
X_val_poly_scaled = poly_scaler.transform(X_val)
sgd_reg = SGDRegressor(max_iter=1, tol=np.infty, warm_start=True, penalty=None, learning_rate="constant", eta0=0.0005)
minimum_val_error = float("inf")
best_epoch = None
best_model = None
for epoch in range(1000):
sgd_reg.fit(X_train_poly_scaled, y_train)
y_val_predit = sgd_reg.predict(X_val_poly_scaled)
val_error = mean_squared_error(y_val, y_val_predit)
if val_error<minimum_val_error:
minimum_val_error = val_error
best_epoch = epoch
best_model = clone(sgd_reg)
4.6 逻辑回归
估计概率
与线性回归模型一样,逻辑回归模型也是计算输入特征的加权和(加上偏置项),但是不同于线性回归的直接输出结果,它输出的是结果的数理逻辑值。逻辑回归模型的估计概率公式如下(向量形式):

逻辑记为σ,输出一个介于0~1的数字,一旦逻辑回归模型估算出实例x属于正类的概率,就可以根据0.5的概率中点做出分类预测。逻辑函数及其图像如下:

注意,当t<0时,σ(t)<0.5;当t≥0时,σ(t)≥0.5。所以如果xTθ是正类,逻辑回归模型预测结果是1,如果是负类,则预测为0。
分数t通常称为logit,定义为logit§=log(p/(1–p))的logit函数与logistic函数相反。确实,如果你计算估计概率p的对数,则会发现结果为t。对数也称为对数奇数,因为它是正类别的估计概率与负类别的估计概率之比的对数。
训练和成本函数
训练的目的就是i设置参数向量θ,使模型对正类实例做出高概率估算(y=1),对负类实例做出低概率估算(y=0)。单个训练实例的成本函数如下:
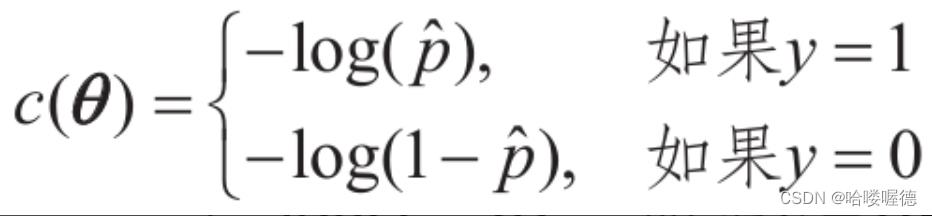
这个成本函数是有道理的,因为当t接近于0时,-log(t)会变得非常大,所以如果模型估算一个正类实例的概率接近于0,成本将会变得很高。同理估算出一个负类实例的概率接近1,成本也会变得非常高。那么反过来,当t接近于1的时候,-log(t)接近于0,所以对一个负类实例估算出的概率接近于0,对一个正类实例估算出的概率接近于1,而成本则都接近于0。
整个训练集的成本函数是所有训练实例的平均成本。可以用一个称为对数损失的单一表达式来表示:
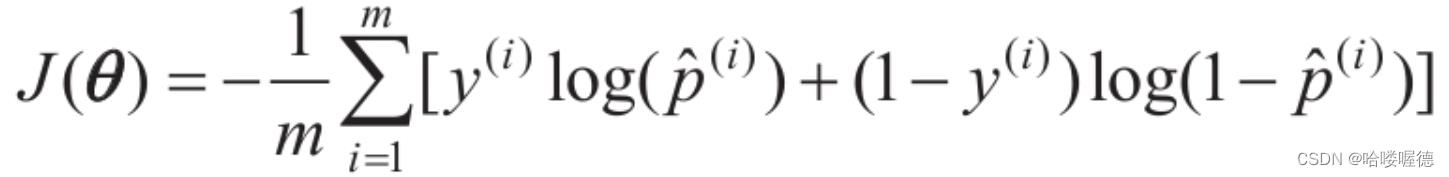
坏消息是,这个函数没有已知的闭式方程(不存在一个标准方程的等价方程)来计算出最小化成本函数的θ值。而好消息是这是个凸函数,所以通过梯度下降(或是其他任意优化算法)保证能够找出全局最小值(只要学习率不是太高,你又能长时间等待)。下式给出了成本函数关于第j个模型参数θj的偏导数方程:
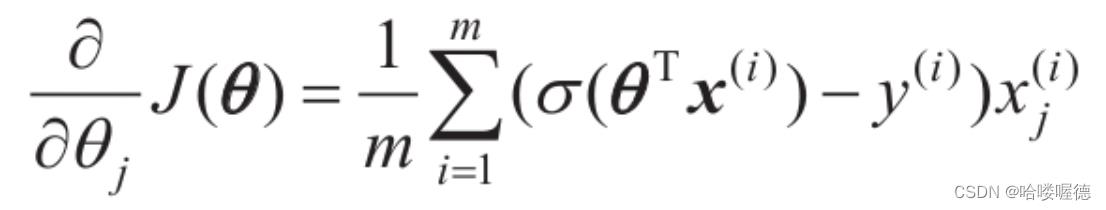
对于每个实例,它都会计算预测误差并将其乘以第j个特征值,然后计算所有训练实例的平均值。一旦你有了包含所有偏导数的梯度向量就可以使用梯度下降算法了。对于随机梯度下降,一次使用一个实例;对于小批量梯度下降,一次使用一个小批量。
决策边界
这里使用著名的鸢尾花数据集说明逻辑回归。数据集共有150朵鸢尾花,分别来自三个不同品种(山鸢尾、变色鸢尾和维吉尼亚鸢尾),数据里包含花的萼片以及花瓣的长度和宽度。接下来基于花瓣宽度这一个特征,创建一个分类器来检测维吉尼亚鸢尾花。
import numpy as np
from sklearn import datasets
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
# 加载数据集
iris = datasets.load_iris()
print(list(iris.keys()))
# 准备花瓣宽度和结果
X = iris["data"][:,3:] # 花瓣宽度
y = (iris["target"]==2).astype(np.int)
# 模型训练
log_reg = LogisticRegression()
log_reg.fit(X, y)
# 观察宽度在0~3cm的模型估算概率
X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
y_proba = log_reg.predict_proba(X_new)
decision_boundary = X_new[y_proba[:, 1] >= 0.5][0]
# 绘制维吉尼亚鸢尾花的预测曲线外,加上其余两种类型的分布,标注决策边界
plt.figure(figsize=(8, 3))
plt.plot(X[y==0], y[y==0], "bs")
plt.plot(X[y==1], y[y==1], "g^")
plt.plot([decision_boundary, decision_boundary], [-1, 2], "k:", linewidth=2)
plt.plot(X_new, y_proba[:, 1], "g-", linewidth=2, label