Netflix System Design- Backend Architecture
Posted 禅与计算机程序设计艺术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netflix System Design- Backend Architecture相关的知识,希望对你有一定的参考价值。
In the battle for the Game of Attention, content is the two-edged sword and user experience is the horse that leads it to battle.
The streaming wars are in full blast with Netflix positioned for continual dominance, armed with over 50,000 individual titles, 200million subscribers in 180+ countries, even more impressive is the underlying technology powering this growth. In this series, my goal is to scratch more than the surface of how Netflix operates, digging deeper into the technicalities of the end-to-end processes involved in delivering content at scale. In the maiden edition of this series, I focus on the Netflix content onboarding system and open connect.
This diagram shows an overview of the system we will be discussing in this article.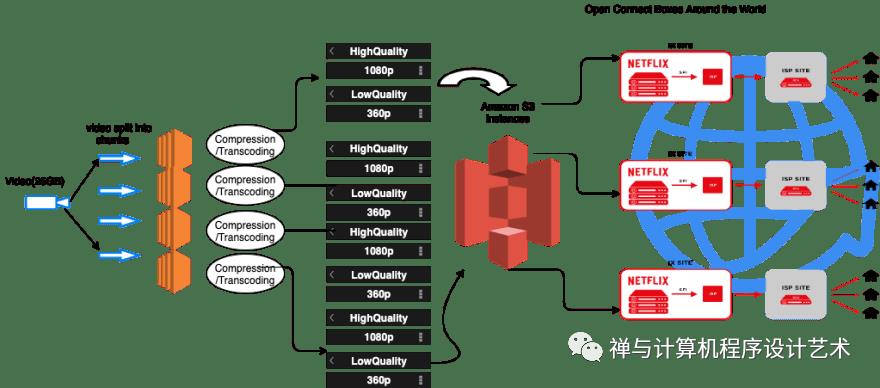
Content Content Content.
Netflix has a combined library of over 50,000 titles, supporting over 2200 devices, each device with its resolution and network speed. For them to be able to serve that many devices at different Network speeds they need to have the original video in different formats. Netflix receives the video from the production houses in the best possible format. The thing is the videos from the production houses are large, very large. For a commercial blu ray 2hr movie, you're looking at 15-25Gb. Serving this to users in that format will consume data and bandwidth, So Netflix performs a series of preprocessing on the original videos to convert them into different file formats. These preprocessing are referred to as Encoding and Transcoding.
Encoding is the process of compressing video and audio files to be compatible with a single target device. Transcoding, on the other hand, allows for already encoded data to be converted to another encoding format.(MP4,WLM,MOV,MPEG-4) This process is particularly useful when users use multiple target devices, such as different mobile phones and web browsers, that do not all support the same native formats or have limited storage capacity.
The reasons for this preprocessing are fairly simple.
Reduce file size.
Reduce buffering for streaming video.
Change resolution or aspect ratio.
Change audio format or quality.
Convert obsolete files to modern formats.
Make a video compatible with a certain device (computer, tablet, smartphone, smartTV, legacy devices).
Make a video compatible with certain software or service.
Compressing a 25Gb movie will take a lot of time, to solve this problem. Netflix breaks the original video into different smaller chunks and using parallel workers in AWS EC2, it performs encoding and transcoding on these chunks converting them into different formats (MP4, MOV, etc) across different resolutions(4k, 1080p, and more).
Netflix also creates multiple replicas of the same video chunk to cater to different network speeds. About 1300 replicas of a video chunk.
Example
-High Quality ------4K,1080p,720p,360p
-Medium Quality ------4K,1080p,720p,360p
-Low Quality ------4K,1080p,720p,360p
Netflix stores all these processed video data on Amazon S3.Which is a highly scalable and available storage platform for storing static data. Each video file is stored in chunks of scenes.
Netflix uses AWS for nearly all its computing and storage needs, including databases, analytics, recommendation engines, video transcoding, and more—hundreds of functions that in total use more than 100,000 server instances on AWS.
https://aws.amazon.com/solutions/case-studies/netflix
By default, most chunks are 10 seconds of video. Each time you skip to different parts of a movie you are querying Netflix's Playback API for different video chunks. You usually have one chunk actively playing, one chunk ready to play when the current chunk is done, and one chunk downloaded. This is done to deliver a seamless watch experience to the user and maximize the best possible speed at that moment.
The speed at which these chunks arrive determines the bit rate(bit rate refers to the number of bits used per second) of the following chunks.
If the first one takes longer than the chunk’s playback duration, it grabs the next lower bitrate chunk for the following one. If it comes faster, it will go for a higher resolution chunk if one is available. That's why sometimes your video resolution can be grainy at first and then adjust to a better definition.
Netflix has users in over 200 countries. If a user in Nigeria wants to watch a movie on an amazon instance hosted in America. The internet service providers will need to travel to America to access those servers which will take time and bandwidth. In an era where fractional delays in serving content can lead to declines in revenue, it is paramount that users get access to the content fast. Netflix solved this problem by creating mini servers inside ISPs and IXP(internet exchange points) known as open connect. These boxes are capable of storing 280 terabytes of data. After the videos have been compressed and transcoded on Amazon S3 they are then transferred to these open connect boxes during an off-peak period (Let's say 4 am). When the user requests for a video instead of hitting Netflix servers directly in the US. It hits the open connect boxes. This ensures less bandwidth, faster playtime, and ultimately a better user experience. Movies can also be localized depending on the region. You could store different movies on the open connect appliances in Nigeria and Brazil. About 90% of Netflix content is served this way.
Open Connect
A CDN is a geographically distributed group of services that work together to provide fast delivery of internet content. Open Connect is Netflix’s custom global content delivery network (CDN).
Everything that happens after you hit play on a video is handled by Open Connect.
Open Connect stores Netflix video in different locations throughout the world. When you press play the video streams from Open Connect, into your device.
Netflix has been in partnership with Internet Service Providers (ISPs) and Internet Exchange Points (IXs or IXPs) around the world to deploy specialized devices called Open Connect Appliances (OCAs) inside their network.

Open Connect Design Image from Netflix These servers periodically report health metrics optimal routes they learned from IXP/ISP networks and what videos they store on their SSD disks to Open Connect Control Plane services on AWS.
When new video files have been transcoded successfully and stored on AWS S3, the control plane services on AWS will transfer these files to OCAs servers on IXP sites. These OCAs servers will apply cache fill to transfer these files to OCAs servers on ISP's sites under their sub-networks.
When an OCA server has successfully stored the video files, it will be able to start the peer fill to copy these files to other OCAs servers within the same site if needed.
Between 2 different sites which can see each other's IP address, the OCAs can apply the tier fill process instead of a regular cache fill.
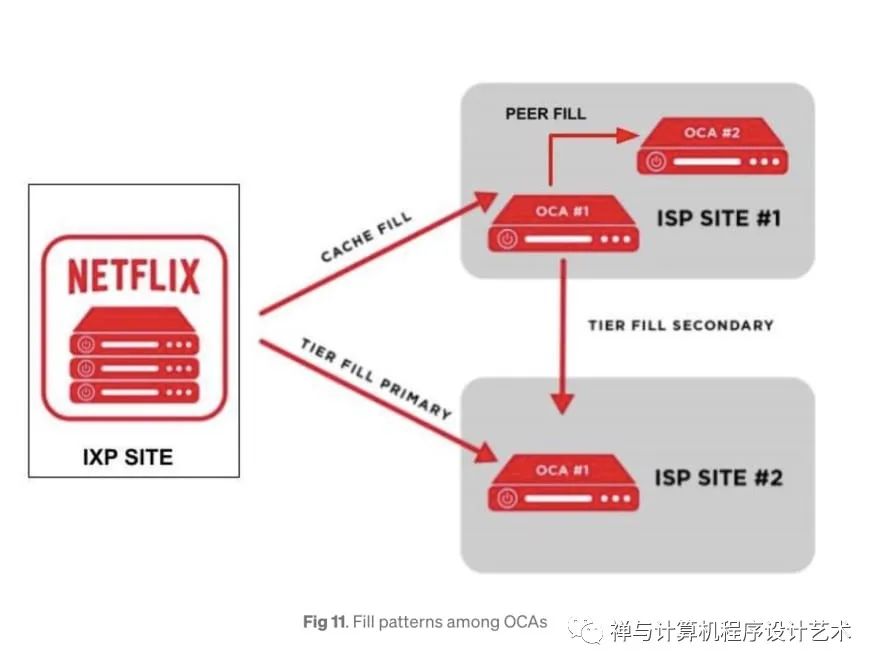
Open Connect Transfering content from Netflix
Conclusion
In summary:
Netflix performs compression and transcoding of the original video file.
The file is split into chunks using parallel workers in AWS for faster processing.
Each chunk is subdivided across several resolutions and internet speeds.
These chunks are stored on Amazon S3.
During the off-peak period. The files are transferred to open connect boxes, which is Netflix's custom content delivery network spread out across the world.
These boxes are capable of communicating and sharing content between themselves.
In the next part of the series, I will be explaining Netflix's core backend architecture.
Netflix accounts for about 15% of the world's internet bandwidth traffic. Serving over 6 billion hours of content per month, globally, to nearly every country in the world. Building a robust, highly scalable, reliable, and efficient backend system is no small engineering feat but the ambitious team at Netflix has proven that problems exist to be solved.
This article provides an analysis of the Netflix system architecture as researched from online sources. Section 1 will provide a simplified overview of the Netflix system. Section 2 is an overview of the backend architecture and section 3 provides a detailed look at the individual system components.
1. Overview
Netflix operates in two clouds Amazon Web Services and Open Connect(Netflix content delivery network).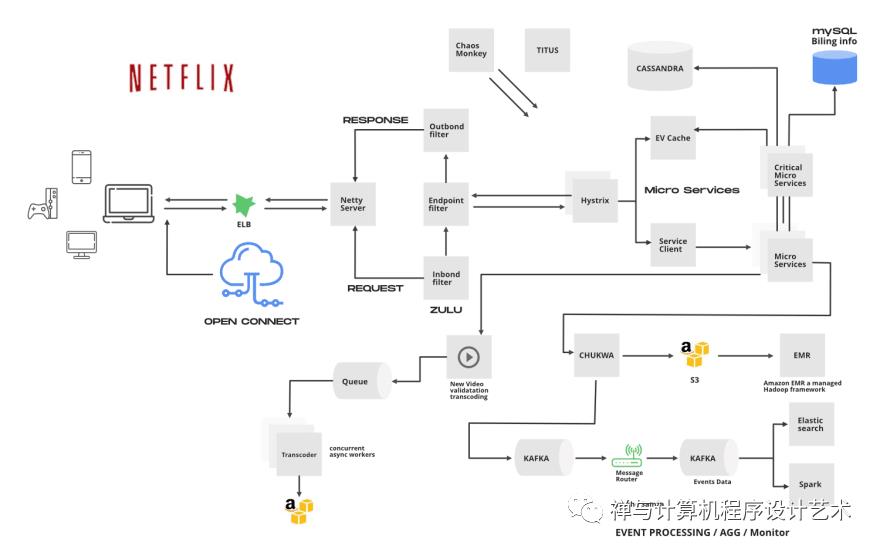
The overall Netflix system consists of three main parts.
Open Connect Appliances(OCA) - Open Connect is Netflix’s custom global content delivery network(CDN). These OCAs servers are placed inside internet service providers (ISPs) and internet exchange locations (IXPs) networks around the world to deliver Netflix content to users.
Client - A client is any device from which you play the video from Netflix. This consists of all the applications that interface with the Netflix servers.
Netflix supports a lot of different devices including smart TV, android, ios platforms, gaming consoles, etc. All these apps are written using platform-specific code. Netflix web app is written using reactJS which was influenced by several factors some of which include startup speed, runtime performance, and modularity.
Backend - This includes databases, servers, logging frameworks, application monitoring, recommendation engine, background services, etc... When the user loads the Netflix app all requests are handled by the backend server in AWS Eg: Login, recommendations, the home page, users history, billing, customer support. Some of these backend services include (AWS EC2 instances, AWS S3, AWS DynamoDB, Cassandra, Hadoop, Kafka, etc).
2. Backend Architecture
Netflix is one of the major drivers of microservices architecture. Every component of their system is a collection of loosely coupled services collaborating. The microservice architecture enables the rapid, frequent and reliable delivery of large, complex applications. The figure below is an overview of the backend architecture.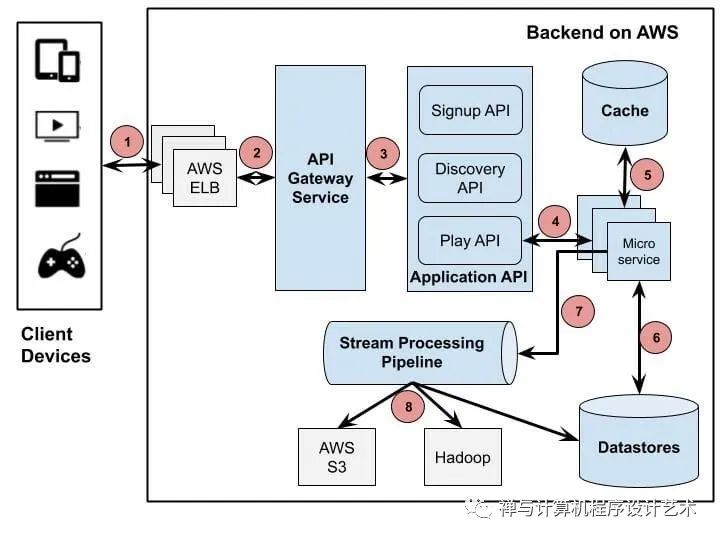
The Client sends a Play request to a Backend running on AWS. Netflix uses Amazon's Elastic Load Balancer (ELB) service to route traffic to its services.
AWS ELB will forward that request to the API Gateway Service. Netflix uses Zuul as its API gateway, which is built to allow dynamic routing, traffic monitoring, and security, resilience to failures at the edge of the cloud deployment.
Application API component is the core business logic behind Netflix operations. There are several types of API corresponding to different user activities such as Signup API, Discovery/Recommendation API for retrieving video recommendation. In this scenario, the forwarded request from API Gateway Service is handled by Play API.
Play API will call a microservice or a sequence of microservices to fulfill the request.
Microservices are mostly stateless small programs, there can be thousands of these services communicating with each other.
Microservices can save or get data from a data store during this process.
Microservices can send events for tracking user activities or other data to the Stream Processing Pipeline for either real-time processing of personalized recommendations or batch processing of business intelligence tasks.
The data coming out of the Stream Processing Pipeline can be persistent to other data stores such as AWS S3, Hadoop HDFS, Cassandra, etc.
3. Backend Components
Open Connect
Everything that happens after you hit play on a video is handled by Open Connect. This system is responsible for streaming video to your device. The following diagram illustrates how the playback process works.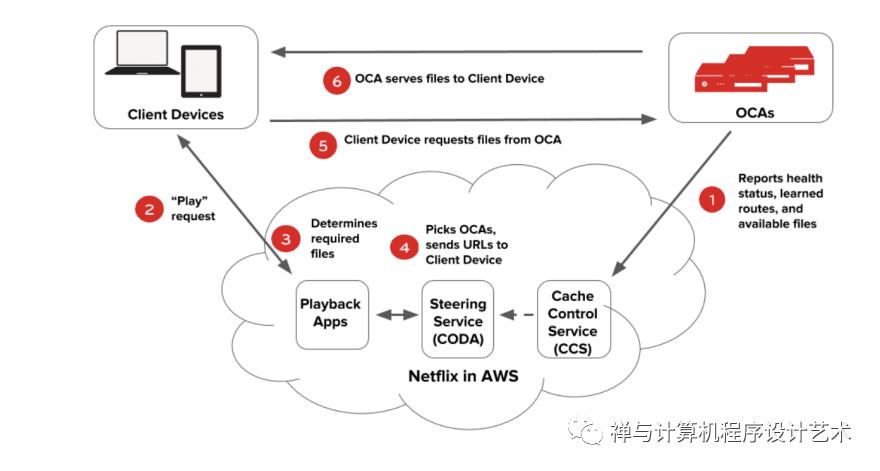
OCAs ping AWS instances to report their health, the routes they have learned, and the files they have on them.
A user on a client device requests playback of a title (TV show or movie) from the Netflix application in AWS.
The Netflix playback service checks for the user's authorization, permission, and licensing, then chooses which files to serve the client taking into account the current network speed and client resolution.
The steering service picks the OCA that the files should be served from, generates URLs for these OCAs, and hands it back to the playback service.
The playback service hands over the URLs of the OCA to the client, The client requests for the video files from that OCA.
Zuul2-API GATEWAY
Netflix uses Amazon's Elastic Load Balancer (ELB) service to route traffic to services. ELB’s are set up such that load is balanced across zones first, then instances.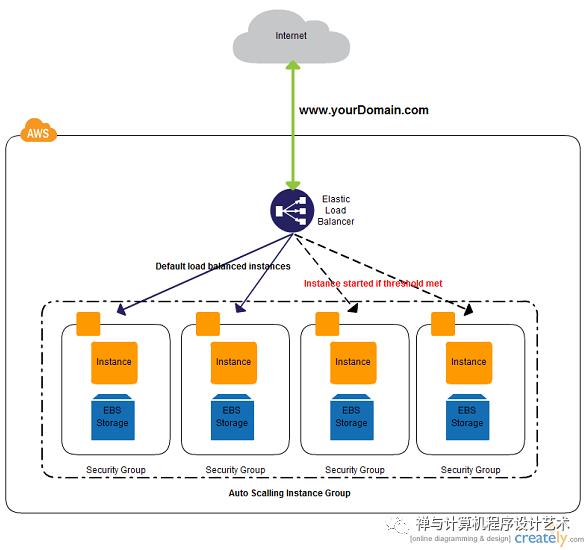
This load balancer routes request to the API gateway service; Netflix uses Zuul as its API gateway, It handles all the requests and performs the dynamic routing of microservice applications. It works as a front door for all the requests.
For Example, /api/products is mapped to the product service, and /api/user is mapped to the user service. The Zuul Server dynamically routes the requests to the respective backend applications. Zuul provides a range of different types of filters that allows them to quickly and nimbly apply functionality to the edge service.
The Cloud Gateway team at Netflix runs and operates more than 80 clusters of Zuul 2, sending traffic to about 100 (and growing) backend service clusters which amount to more than 1 million requests per second.
open-sourcing-zuul-2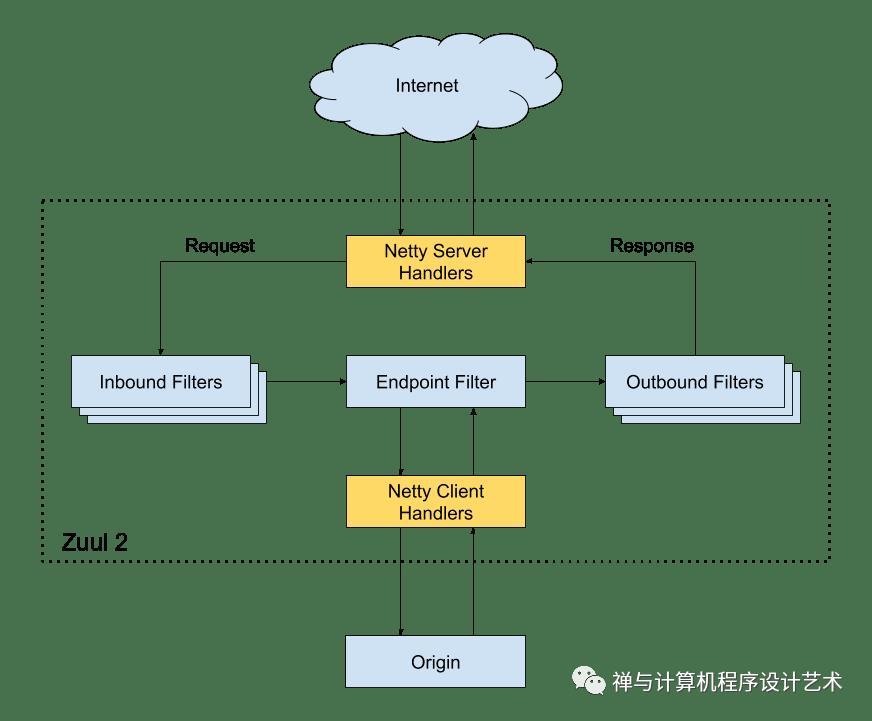
The Netty handlers on the front and back of the filters are mainly responsible for handling the network protocol, web server, connection management, and proxying work. With those inner workings abstracted away, the filters do all of the heavy liftings.
The inbound filters run before proxying the request and can be used for authentication, routing, or decorating the request.
The endpoint filters can either be used to return a static response or proxy the request to the backend service.
The outbound filters run after a response has been returned and can be used for things like metrics, or adding/removing custom headers.
The Zuul 2 Api gateway forwards the request to the appropriate Application API.
Application API
Currently, the Application APIs are defined under three categories: Signup API -for non-member requests such as sign-up, billing, free trial, etc., Discovery API-for search, recommendation requests, and Play API- for streaming, view licensing requests, etc. When a user clicks signup, for example, Zuul will route the request to the Signup API.
If you consider an example of an already subscribed user. Supposing the user clicks on play for the latest episode of peaky blinders, the request will be routed to the playback API. The API in turn calls several microservices under the hood. Some of these calls can be made in parallel because they don’t depend on each other. Others have to be sequenced in a specific order. The API contains all the logic to sequence and parallelize the calls as necessary. The device, in turn, doesn’t need to know anything about the orchestration that goes on under the hood when the customer clicks “play”.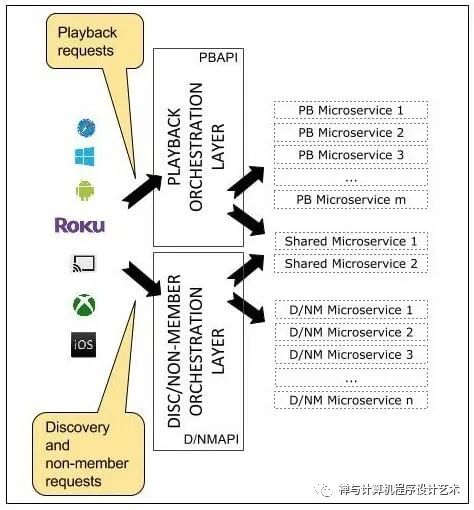
Signup requests map to signup backend services, Playback requests, with some exceptions, map only to playback backend services, and similarly discovery APIs map to discovery services.
Hystrix- Distributed API Services Management
Hystrix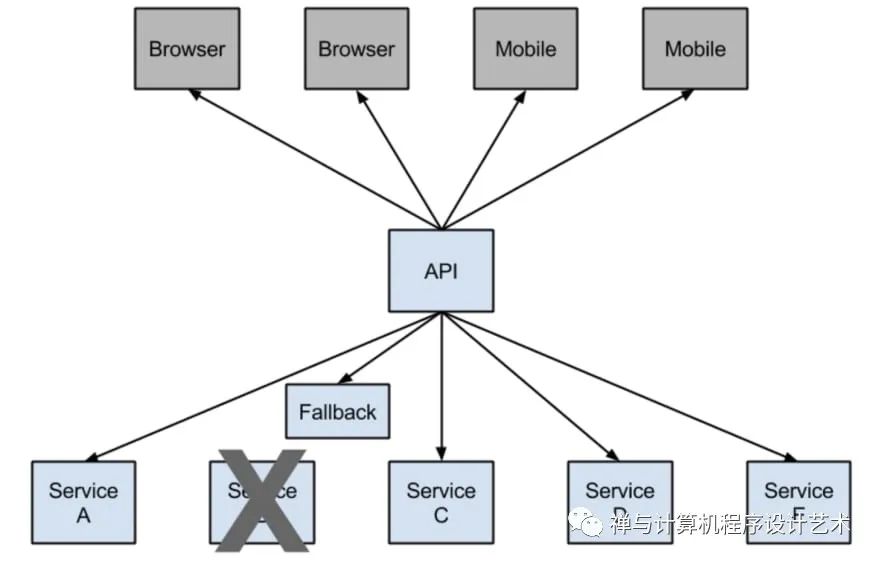
In any distributed environment (with a lot of dependencies), inevitably some of the many service dependencies fail. It can be unmanageable to monitor the health and state of all the services as more and more services will be stood up and some services may be taken down or simply break down. Hystrix comes with help by providing a user-friendly dashboard. Hystrix library is used to control the interaction between these distributed services by adding some latency tolerance and fault tolerance logic.
Consider this example from Netflix, they have a microservice that provides a tailored list of movies back to the user. If the service fails, they reroute the traffic to circumvent the failure to another vanilla microservice that simply returns the top 10 movies that are family-friendly. So they have this safe failover that they can go to and that is the classic example of first circuit breaking.
Note:
Netflix Hystrix is no longer in active development and is currently in maintenance mode. Some internal projects are currently being built with resilience4j
https://github.com/resilience4j/resilience4j
Titus- Container Management
Titus
Titus is a container management platform that provides scalable and reliable container execution and cloud-native integration with Amazon AWS.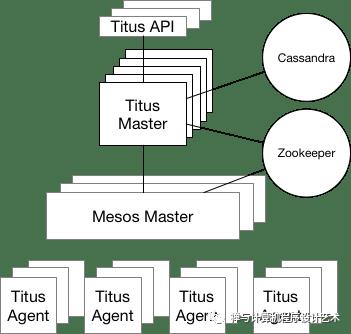
It is a framework on top of Apache Mesos, a cluster management system that brokers available resources across a fleet of machines.
Titus is run in production at Netflix, managing thousands of AWS EC2 instances and launching hundreds of thousands of containers daily for both batch and service workloads. Just think of it as the Netflix version of Kubernetes.
Titus runs about 3 million containers per week.
Datastores
EVCache
A cache's primary purpose is to increase data retrieval performance by reducing the need to access the underlying slower storage layer. Trading off capacity for speed, a cache typically stores a subset of data transiently.
EVCache
Two uses cases for caching is to:
Provides fast access to frequently stored data.
Provides fast access to computed(memoized) data. Netflix's microservices rely on caches for fast, reliable access to multiple types of data like a member’s viewing history, ratings, and personalized recommendations.
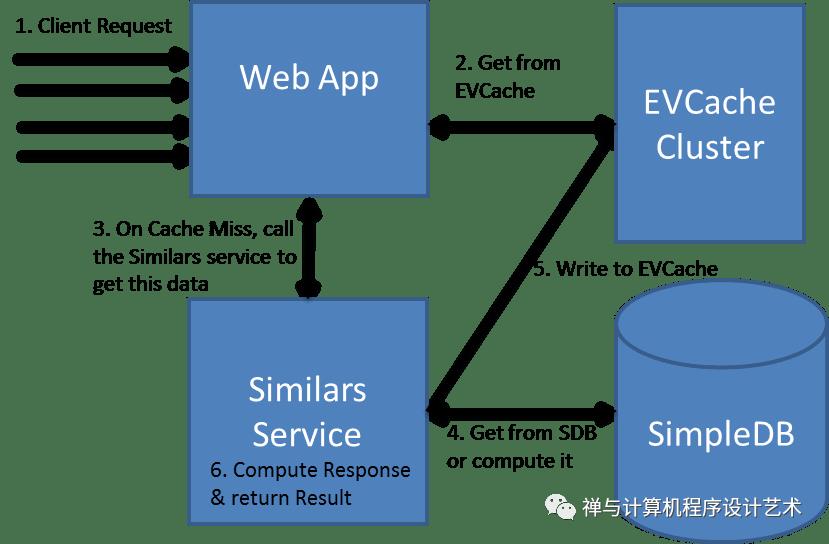
EVCache Diagram
EVCache is a memcached & spymemcached based caching solution that is mainly used for AWS EC2 infrastructure for caching frequently used data.
EVCache is an abbreviation for:
Ephemeral - The data stored is for a short duration as specified by its TTL (Time To Live).
Volatile - The data can disappear any time (Evicted).
Cache - An in-memory key-value store.
SSDs for Caching
Traditionally caching is done on the RAM. Storing large amounts of data on RAM is expensive. Hence Netflix decided to move some caching data to SSD.
Modern disk technologies based on SSD are providing fast access to data but at a much lower cost when compared to RAM. The cost to store 1 TB of data on SSD is much lower than storing the same amount using RAM.
Evolution of application Data Caching
mysql
Netflix uses AWS EC2 instances of MYSQL for its Billing infrastructure. Billing infrastructure is responsible for managing the billing state of Netflix members. This includes keeping track of open/paid billing periods, the amount of credit on the member’s account, managing the payment status of the member, initiating charge requests, and what date the member has paid through.
The payment processor needed the ACID capabilities of an RDBMS to process charge transactions.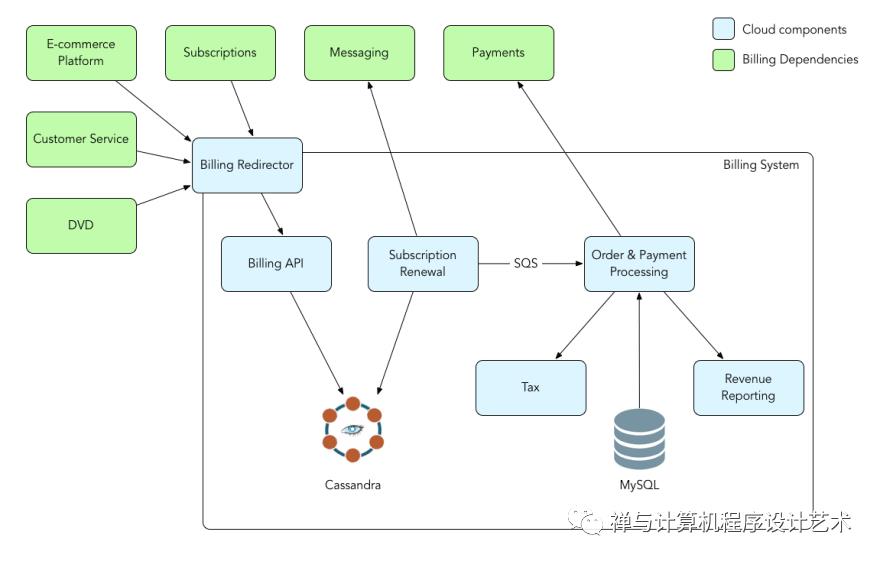
Apache Cassandra
Cassandra is a free and open-source distributed wide column store NoSQL database designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure.
Netflix uses Cassandra for its scalability, lack of single points of failure, and cross-regional deployments. ” In effect, a single global Cassandra cluster can simultaneously service applications and asynchronously replicate data across multiple geographic locations.
Netflix stores all kinds of data across their Cassandra DB instances. All user collected event metrics are stored on Cassandra.
As user data began to increase there needed to be a more efficient way to manage data storage. Netflix Redesigned data storage architecture with two main goals in mind:
Smaller Storage Footprint.
Consistent Read/Write Performance as viewing per member grows.
The solution to the large data problem was to compress the old rows. Data were divided into two types:
Live Viewing History (LiveVH): Small number of recent viewing records with frequent updates. The data is stored in uncompressed form.
Compressed Viewing History (CompressedVH): A large number of older viewing records with rare updates. The data is compressed to reduce the storage footprint. Compressed viewing history is stored in a single column per row key.
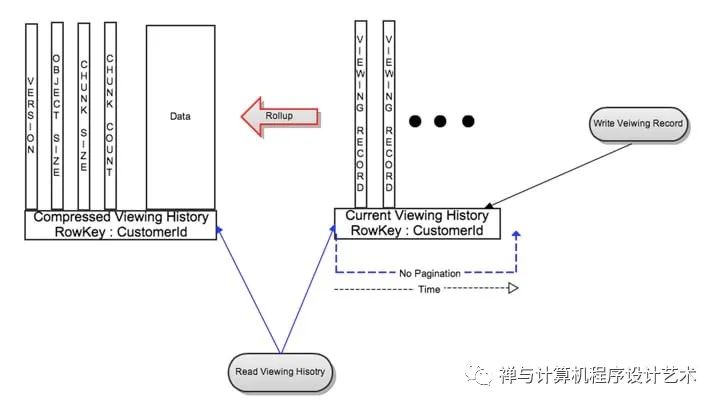
Compressed Viewing History
Stream Processing Pipeline
Did you know that Netflix personalizes movie artwork just for you?. You might be surprised to learn the image shown for each video is selected specifically for you. Not everyone sees the same image.
Netflix tries to select the artwork highlighting the most relevant aspect of a video to you based on the data they have learned about you on your viewing history and interests.
Stream Processing Data Pipeline has become Netflix’s data backbone of business analytics and personalized recommendation tasks. It is responsible for producing, collecting, processing, aggregating, and moving all microservice events to other data processors in near real-time.
Streaming data is data that is generated continuously by thousands of data sources, which typically send in the data records simultaneously, and in small sizes (order of Kilobytes). Streaming data includes a wide variety of data such as log files generated by customers using your mobile or web applications, e-commerce purchases, in-game player activity, information from social networks, financial trading floors, or geospatial services, and telemetry from connected devices or instrumentation in data centers.
AWS- What is streaming Data?
This data needs to be processed sequentially and incrementally on a record-by-record basis or over sliding time windows and used for a wide variety of analytics including correlations, aggregations, filtering, and sampling.
Information derived from such analysis gives companies visibility into many aspects of their business and customer activity such as –service usage (for metering/billing), server activity, website clicks, and geo-location of devices, people, and physical goods –and enables them to respond promptly to emerging situations. For example, businesses can track changes in public sentiment on their brands and products by continuously analyzing social media streams, and respond in a timely fashion as the necessity arises.
The stream processing platform processes trillions of events and petabytes of data per day.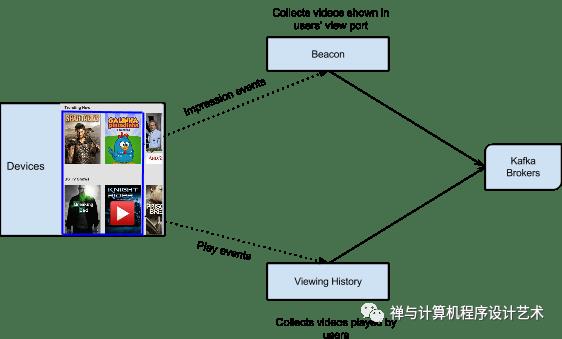
Viewing History Service captures all the videos that are played by members. Beacon is another service that captures all impression events and user activities within Netflix, All the data collected by the Viewing History and Beacon services are sent to Kafka.
Apache Kafka- Analyzing Streaming Data
Kafka is open-source software that provides a framework for storing, reading, and analyzing streaming data.
Netflix embraces Apache Kafka® as the de-facto standard for its eventing, messaging, and stream processing needs. Kafka acts as a bridge for all point-to-point and Netflix Studio wide communications.
How Kafka is used by Netflix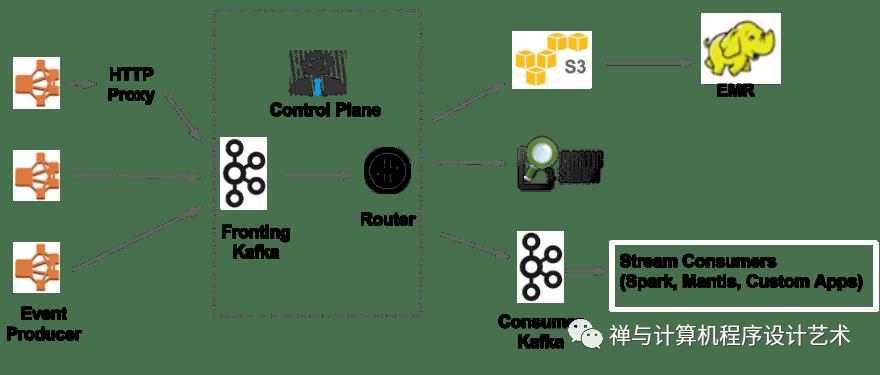
Apache Chukwe- Analyzing Streaming Data
Apache Chukwe is an open-source data collection system for collecting logs or events from a distributed system. It is built on top of HDFS and Map-reduce framework. It comes with Hadoop’s scalability and robustness features. It includes a lot of powerful and flexible toolkits to display, monitor, and analyze data. Chukwe collects the events from different parts of the system; From Chukwe you can do monitoring, analysis or you can use the dashboard to view the events. Chukwe writes the event in the Hadoop file sequence format (S3).
Apache Spark - Analyzing Streaming Data
Netflix uses Apache Spark and Machine learning for Movie recommendation. Apache Spark is an open-source unified analytics engine for large-scale data processing.
On a live user request, the aggregated play popularity(How many times is a video played) and take rate(Fraction of play events over impression events for a given video) data along with other explicit signals such as members’ viewing history and past ratings are used to compute a personalized content for the user. The following figure shows the end-to-end infrastructure for building user movie recommendations.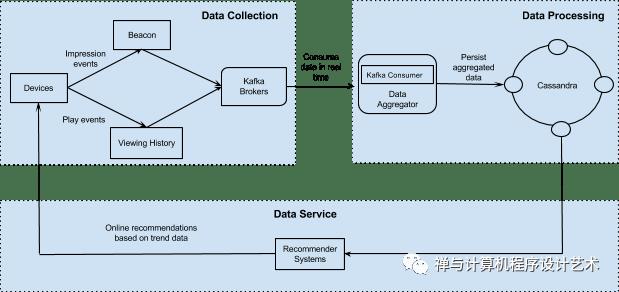
Elastic Search - Error Logging and Monitoring
Netflix uses elastic search for data visualization, customer support, and for error detection in the system.
Elasticsearch is a search engine based on the Lucene library. It provides a distributed, multitenant-capable full-text search engine with an HTTP web interface and schema-free JSON documents.
With elastic search, they can easily monitor the state of the system and troubleshoot error logs and failures.
Conclusion
This article has provided a detailed analysis of the Netflix Backend architecture. You can refer to these references for more information.
Follow me here and across my social media for more content like this Linkedin. Twitter
REFERENCES
Titus
Open Sourcing Zuul
Open Connect
How Netflix Backend Operates
A Design Analysis Of Cloud-Based Microservices Architecture At Netflix
Netflix System Design
Hystrix What is it and Why is it Used
Engineering Tradeoffs and the Netflix API Re-architecture
Application Data Caching Using ssds
Evolution Of Application Data Caching From Ram To ssd
Netflix Billing Migration To Aws
Optimizing The Netflix Api
What's Trending On Netflix
Evolution Of The Netflix Data Pipeline
Zuul API Gateway
CAP_theorem
What Happens When You Press Play
Scaling Time Series Data Storage Part1
Netflix-High-Level-System-Architecture
How-Kafka-is-used-by-Netflix
Netflix Consumes 15% of the World's Internet Bandwidth
以上是关于Netflix System Design- Backend Architecture的主要内容,如果未能解决你的问题,请参考以下文章