容器CPU隔离的底层实现机制
Posted popsuper1982
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了容器CPU隔离的底层实现机制相关的知识,希望对你有一定的参考价值。
在真正的生产实践过程中,对于CPU的隔离要求比容器的默认策略要严格的多,因而需要对于Linux内核底层机制有所理解,才能很好的做CPU隔离,甚至在离线业务混合部署隔离等策略。
本文不打算讲述Cgroup的使用层原理,因为这类文章已经比较多了,而是希望从更深层的原理去解析。
一、系统的初始化与Cgroup的初始化
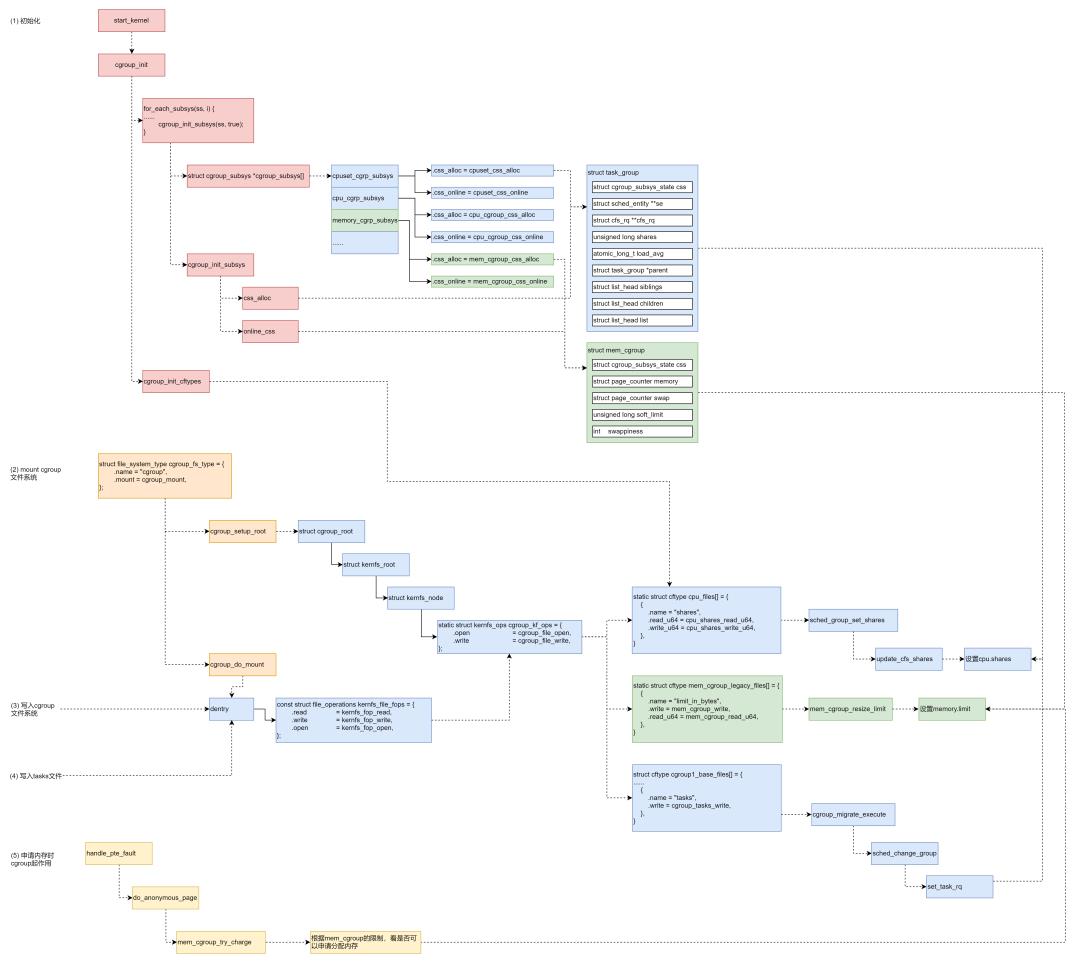
cgroup的机制起作用要从Linux系统的初始化开始。
内核是如何初始化的呢?
内核的启动从入口函数start_kernel()开始。在init/main.c文件中,start_kernel相当于内核的main函数。打开这个函数,你会发现,里面是各种各样初始化函数XXXX_init。
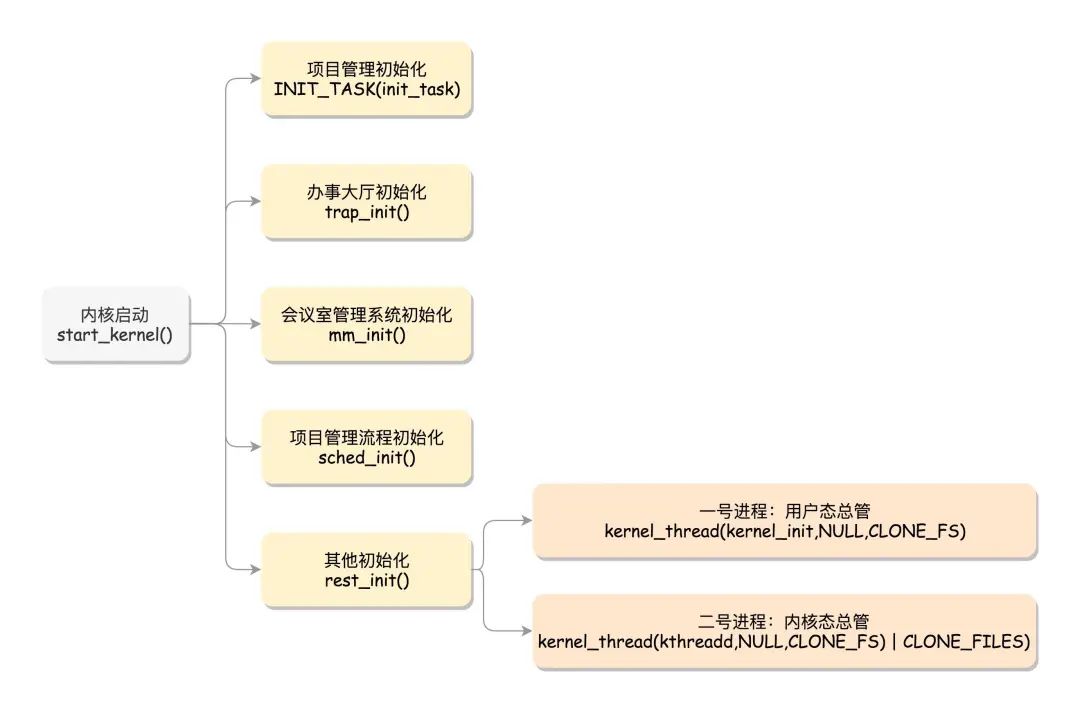
在操作系统里面,先要有个创始进程init_task,它的定义是struct task_struct init_task = INIT_TASK(init_task)。它是系统创建的第一个进程,我们称为0号进程。这是唯一一个没有通过fork或者kernel_thread产生的进程,是进程列表的第一个。
rest_init的第一大工作是,用kernel_thread(kernel_init, NULL, CLONE_FS)创建第二个进程,这个是1号进程。1号进程对于操作系统来讲,有“划时代”的意义。因为它将运行一个用户进程。
rest_init第二大事情就是第三个进程,就是2号进程kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES),这里的函数kthreadd,负责所有内核态的线程的调度和管理,是内核态所有线程运行的祖先。
在系统初始化的时候,cgroup也会进行初始化,在start_kernel中,cgroup_init_early和cgroup_init都会被调用进行各个Cgroup子系统的初始化。
其实是初始化一些Cgroup相关的内核数据结构,例如对于CPU来讲,有下面的数据结构。
cpuset_cgrp_subsys
struct cgroup_subsys cpuset_cgrp_subsys =
.css_alloc = cpuset_css_alloc,
.css_online = cpuset_css_online,
.css_offline = cpuset_css_offline,
.css_free = cpuset_css_free,
.can_attach = cpuset_can_attach,
.cancel_attach = cpuset_cancel_attach,
.attach = cpuset_attach,
.post_attach = cpuset_post_attach,
.bind = cpuset_bind,
.fork = cpuset_fork,
.legacy_cftypes = files,
.early_init = true,
;
cpu_cgrp_subsys
struct cgroup_subsys cpu_cgrp_subsys =
.css_alloc = cpu_cgroup_css_alloc,
.css_online = cpu_cgroup_css_online,
.css_released = cpu_cgroup_css_released,
.css_free = cpu_cgroup_css_free,
.fork = cpu_cgroup_fork,
.can_attach = cpu_cgroup_can_attach,
.attach = cpu_cgroup_attach,
.legacy_cftypes = cpu_files,
.early_init = true,
;
cgroup_init_subsys会对各个cgroup_subsys做初始化,cgroup_init_subsys里面会做两件事情,一个是调用cgroup_subsys的css_alloc函数创建一个cgroup_subsys_state;另外就是调用online_css,也即调用cgroup_subsys的css_online函数,激活这个cgroup。
对于CPU来讲,css_alloc函数就是cpu_cgroup_css_alloc。这里面会调用 sched_create_group创建一个struct task_group。
struct task_group
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
struct cfs_rq **cfs_rq;
unsigned long shares;
#ifdef CONFIG_SMP
atomic_long_t load_avg ____cacheline_aligned;
#endif
#endif
struct rcu_head rcu;
struct list_head list;
struct task_group *parent;
struct list_head siblings;
struct list_head children;
struct cfs_bandwidth cfs_bandwidth;
;
在task_group结构中,有一个成员是sched_entity,也说明CPU的隔离和调度是强相关的。
二、CPU和进程的调度机制
在Linux里面,进程大概可以分成两种。
一种称为实时进程,也就是需要尽快执行返回结果的那种。这就好比我们是一家公司,接到的客户项目需求就会有很多种。有些客户的项目需求比较急,比如一定要在一两个月内完成的这种,客户会加急加钱,那这种客户的优先级就会比较高。
另一种是普通进程,大部分的进程其实都是这种。这就好比,大部分客户的项目都是普通的需求,可以按照正常流程完成,优先级就没实时进程这么高,但是人家肯定也有确定的交付日期。
那很显然,对于这两种进程,我们的调度策略肯定是不同的。
进程在Linux内核中被task_struct结构进行管理,在task_struct中,有一个成员变量,我们叫调度策略。
unsigned int policy;
它有以下几个定义:
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6
在task_struct里面,还有这样的成员变量:
const struct sched_class *sched_class;
调度策略的执行逻辑,就封装在这里面,它是真正干活的那个。
sched_class有几种实现:
stop_sched_class优先级最高的任务会使用这种策略,会中断所有其他线程,且不会被其他任务打断;
dl_sched_class就对应上面的deadline调度策略;
rt_sched_class就对应RR算法或者FIFO算法的调度策略,具体调度策略由进程的task_struct->policy指定;
fair_sched_class就是普通进程的调度策略;
idle_sched_class就是空闲进程的调度策略。
普通进程使用的调度策略是fair_sched_class,CFS全称Completely Fair Scheduling,叫完全公平调度。
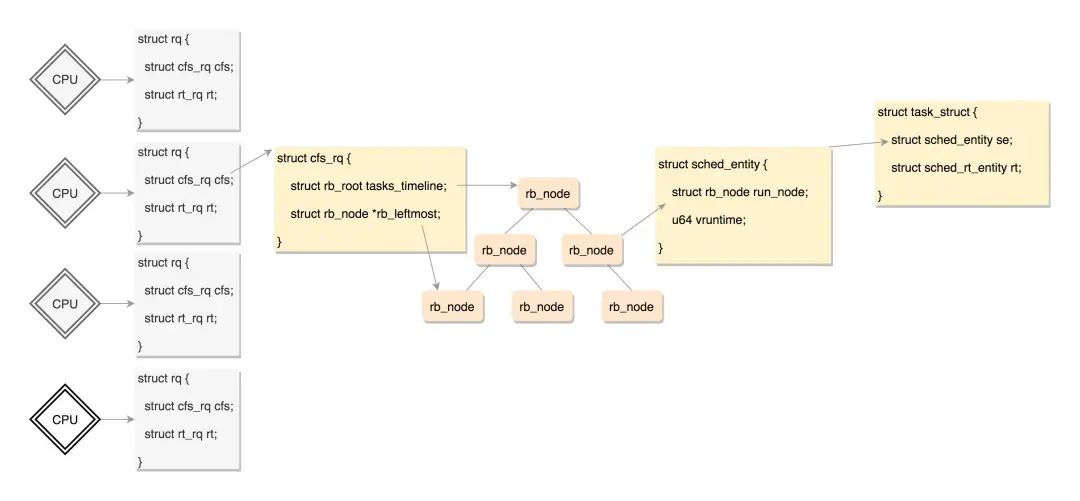
在每个CPU上都有一个队列rq,这个队列里面包含多个子队列,例如rt_rq和cfs_rq,不同的队列有不同的实现方式,cfs_rq就是用红黑树实现的。
当某个CPU需要找下一个任务执行的时候,会按照优先级依次调用调度类,不同的调度类操作不同的队列。当然rt_sched_class先被调用,它会在rt_rq上找下一个任务,只有找不到的时候,才轮到fair_sched_class被调用,它会在cfs_rq上找下一个任务。这样保证了实时任务的优先级永远大于普通任务。
sched_class定义的与调度有关的函数。
enqueue_task向就绪队列中添加一个进程,当某个进程进入可运行状态时,调用这个函数;
dequeue_task 将一个进程从就绪队列中删除;
pick_next_task 选择接下来要运行的进程;
put_prev_task 用另一个进程代替当前运行的进程;
set_curr_task 用于修改调度策略;
task_tick 每次周期性时钟到的时候,这个函数被调用,可能触发调度。
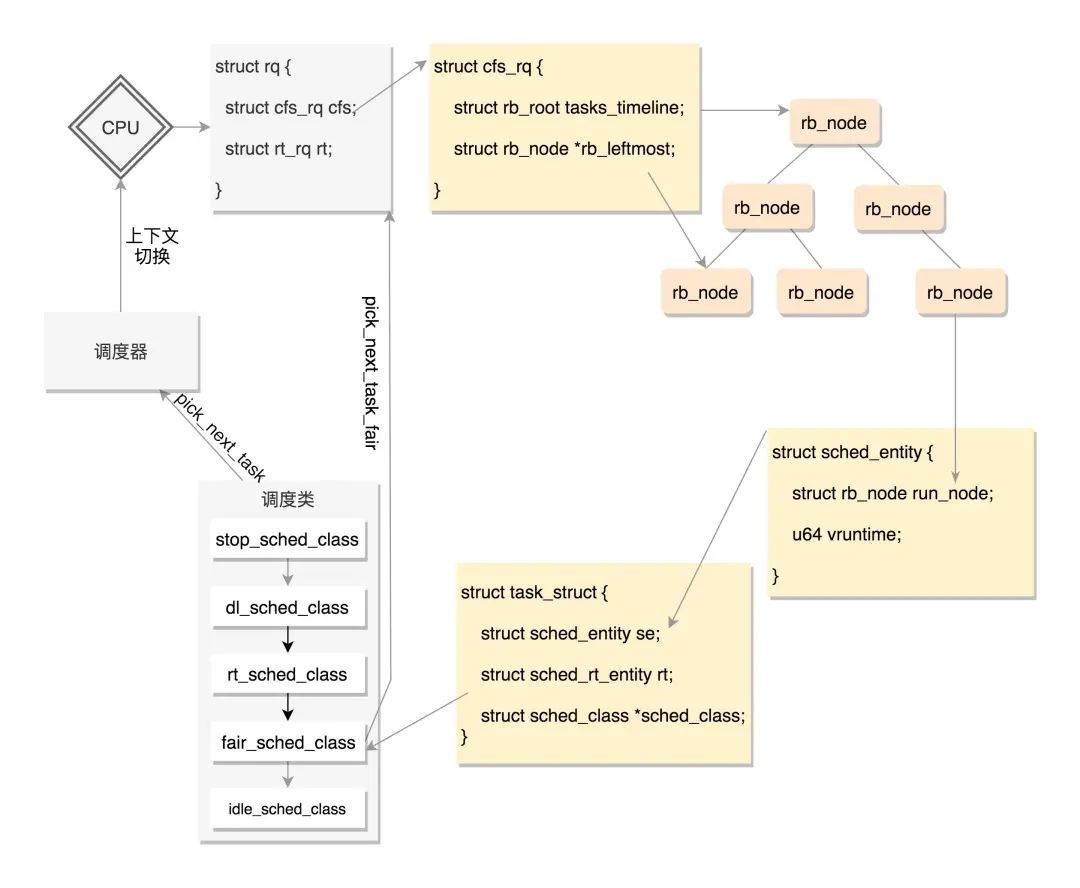
在内核初始化的时候,css_online函数会激活cgroup。这里面,对于每一个CPU,取出每个CPU的运行队列rq,也取出task_group的sched_entity,然后通过attach_entity_cfs_rq将sched_entity添加到运行队列中。
这样调度的时候,cgroup就能起作用了。
三、将Cgroup暴露到cgroupfs进行管理
在Linux里面,一切皆文件。因而cgroup的配置也是通过类似文件系统的机制来的。
我们先来看一下Linux文件系统的机制。
想要操作文件系统,第一件事情就是挂载文件系统。
内核是不是支持某种类型的文件系统,需要我们进行注册才能知道。例如ext4文件系统,就需要通过register_filesystem进行注册,传入的参数是ext4_fs_type,表示注册的是ext4类型的文件系统。这里面最重要的一个成员变量就是ext4_mount。
register_filesystem(&ext4_fs_type);
static struct file_system_type ext4_fs_type =
.owner = THIS_MODULE,
.name = "ext4",
.mount = ext4_mount,
.kill_sb = kill_block_super,
.fs_flags = FS_REQUIRES_DEV,
;
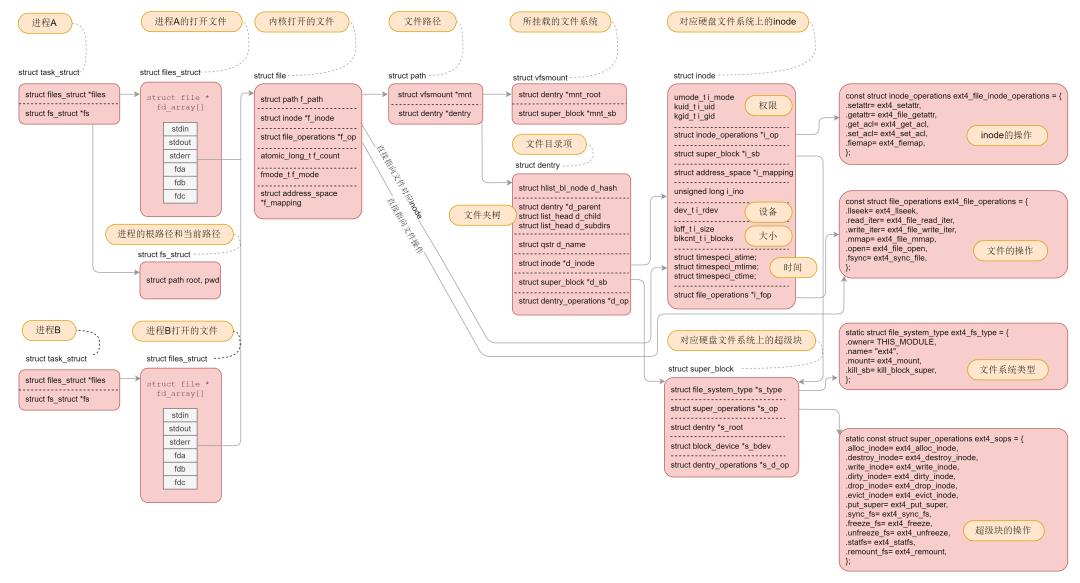
mount之后,接下来就是打开一个文件。对于每一个进程,打开的文件都有一个文件描述符,在files_struct里面会有文件描述符数组。每个一个文件描述符是这个数组的下标,里面的内容指向一个file结构,表示打开的文件。这个结构里面有这个文件对应的inode,最重要的是这个文件对应的操作file_operation。如果操作这个文件,就看这个file_operation里面的定义了。
对于每一个打开的文件,都有一个dentry对应,虽然叫作directory entry,但是不仅仅表示文件夹,也表示文件。它最重要的作用就是指向这个文件对应的inode。
如果说file结构是一个文件打开以后才创建的,dentry是放在一个dentry cache里面的,文件关闭了,他依然存在,因而他可以更长期地维护内存中的文件的表示和硬盘上文件的表示之间的关系。
inode结构就表示硬盘上的inode,包括块设备号等。
几乎每一种结构都有自己对应的operation结构。
cgroup是一种特殊的文件系统。它的定义如下:
struct file_system_type cgroup_fs_type =
.name = "cgroup",
.mount = cgroup_mount,
.kill_sb = cgroup_kill_sb,
.fs_flags = FS_USERNS_MOUNT,
;
当我们mount这个cgroup文件系统的时候,会调用cgroup_mount
就像在普通文件系统上,每一个文件都对应一个inode,在cgroup文件系统上,每个文件都对应一个struct kernfs_node结构。将文件的操作函数设置为kf_ops,指向cgroup_kf_ops。
static struct kernfs_ops cgroup_kf_ops =
.atomic_write_len = PAGE_SIZE,
.open = cgroup_file_open,
.release = cgroup_file_release,
.write = cgroup_file_write,
.seq_start = cgroup_seqfile_start,
.seq_next = cgroup_seqfile_next,
.seq_stop = cgroup_seqfile_stop,
.seq_show = cgroup_seqfile_show,
接下来,在cgroup_mount中,要做的一件事情是cgroup_do_mount,调用kernfs_mount真的去mount这个文件系统,返回一个普通的文件系统都认识的dentry。这种特殊的文件系统对应的文件操作函数为kernfs_file_fops。
const struct file_operations kernfs_file_fops =
.read = kernfs_fop_read,
.write = kernfs_fop_write,
.llseek = generic_file_llseek,
.mmap = kernfs_fop_mmap,
.open = kernfs_fop_open,
.release = kernfs_fop_release,
.poll = kernfs_fop_poll,
.fsync = noop_fsync,
;
当我们要写入一个CGroup文件来设置参数的时候,根据文件系统的操作,kernfs_fop_write会被调用,在这里面会调用kernfs_ops的write函数,根据上面的定义为cgroup_file_write,在这里会调用cftype的write函数。对于CPU的write函数,有以下的定义。
static struct cftype cpu_files[] =
#ifdef CONFIG_FAIR_GROUP_SCHED
.name = "shares",
.read_u64 = cpu_shares_read_u64,
.write_u64 = cpu_shares_write_u64,
,
#endif
#ifdef CONFIG_CFS_BANDWIDTH
.name = "cfs_quota_us",
.read_s64 = cpu_cfs_quota_read_s64,
.write_s64 = cpu_cfs_quota_write_s64,
,
.name = "cfs_period_us",
.read_u64 = cpu_cfs_period_read_u64,
.write_u64 = cpu_cfs_period_write_u64,
,
如果设置的是cpu.shares,则调用cpu_shares_write_u64。在这里面,task_group的shares变量更新了,并且更新了CPU队列上的调度实体。
四、将进程号放入Cgroup进行管理
但是这个时候别忘了,我们还没有将CPU的文件夹下面的tasks文件写入进程号呢。写入一个进程号到tasks文件里面,按照cgroup1_base_files里面的定义,我们应该调用cgroup_tasks_write。
这里将这个进程和一个cgroup关联起来,也即将这个进程迁移到这个cgroup下面。
static void sched_change_group(struct task_struct *tsk, int type)
struct task_group *tg;
tg = container_of(task_css_check(tsk, cpu_cgrp_id, true),
struct task_group, css);
tg = autogroup_task_group(tsk, tg);
tsk->sched_task_group = tg;
#ifdef CONFIG_FAIR_GROUP_SCHED
if (tsk->sched_class->task_change_group)
tsk->sched_class->task_change_group(tsk, type);
else
#endif
set_task_rq(tsk, task_cpu(tsk));
在sched_change_group中设置这个进程以这个task_group的方式参与调度,从而使得上面的cpu.shares起作用。
五、总结
对于内核中cgroup的工作机制在这里总结一下。
第一步:系统初始化的时候,初始化cgroup的各个子系统的操作函数,分配各个子系统的数据结构。
第二步:mount cgroup文件系统,创建文件系统的树形结构,以及操作函数。
第三步:写入cgroup文件,设置CPU的相关参数,这个时候文件系统的操作函数会调用到cgroup子系统的操作函数,从而将参数设置到cgroup子系统的数据结构中。
第四步:写入tasks文件,将进程交给某个cgroup进行管理,因为tasks文件也是一个cgroup文件,统一会调用文件系统的操作函数进而调用cgroup子系统的操作函数,将cgroup子系统的数据结构和进程关联起来。
第五步:对于CPU来讲,会修改scheduled entity,放入相应的队列里面去,从而下次调度的时候就起作用了。
想理解Linux内核的更多机制吗,欢迎订阅《趣谈Linux操作系统》专栏
【立省¥40 | 仅限今日】
拼团 + 口令「happy2021」立省 ¥40,到手仅 ¥89!
原价 ¥129,口令今晚 24:00失效!

以上是关于容器CPU隔离的底层实现机制的主要内容,如果未能解决你的问题,请参考以下文章