oracle 19c adg GAP恢复
Posted P10ZHUO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了oracle 19c adg GAP恢复相关的知识,希望对你有一定的参考价值。
oracle 19c adg GAP恢复
继上篇文章,回退成功后。发现我们在回退的过程中,为了不影响备库,把log_archive_dest_state_2设置为了defer。但是后面想想,已经来不及了,因为主库刷新数据字典的过程中,已经会把字典的变化同步到了备库。我们设置defer的时间迟了,应该在刷新数据字典之前,就把log_archive_dest_state_2设置为defer,让备库不会应用数据字典的变化。如果此时发生切换,switchover肯定不行,failover的时候,直接把备库切换为主库,这也不失为一种好的回退方法。
本篇文章不讨论回退方法,由于设置为了defer,恢复时间用了将近8h,主库的归档删除策略是华为的备份软件强制删除,所以导致备库缺少归档,adg同步异常。下面就说下恢复方法。
故障现象
环境信息:
2节点RAC,GI和DB的补丁应用到2020年10月份。数据库版本:19.9.0.0.0
os版本:RHEL 7.6
备库adg同步信息如下:
SQL> set pages 1000 lines 1000
SQL> SELECT al.thrd "Thread", almax "Last Seq Received", lhmax "Last Seq Applied"
FROM (select thread# thrd, MAX(sequence#) almax
FROM v$archived_log
WHERE resetlogs_change#=(SELECT resetlogs_change# FROM v$database) GROUP BY thread#) al,
(SELECT thread# thrd, 2 3 4 5 MAX(sequence#) lhmax
FROM v$log_history
WHERE resetlogs_change#=(SELECT resetlogs_change# FROM v$database) GROUP BY thread#) lh
WHERE al.thrd = lh.thrd; 6 7 8
Thread Last Seq Received Last Seq Applied
---------- ----------------- ----------------
1 32301 32262
2 28725 28700
SQL> col client_pid for a10
SELECT inst_id, thread#, process, pid, status, client_process, client_pid,
sequence#, block#, active_agents, known_agents FROM gv$managed_standby ORDER BY thread#, pid;SQL> 2
INST_ID THREAD# PROCESS PID STATUS CLIENT_P CLIENT_PID SEQUENCE# BLOCK# ACTIVE_AGENTS KNOWN_AGENTS
---------- ---------- --------- ------------------------ ------------ -------- ---------- ---------- ---------- ------------- ------------
1 0 RFS 30765 IDLE UNKNOWN 35906 0 0 0 0
1 0 RFS 30767 IDLE UNKNOWN 142075 0 0 0 0
1 0 RFS 30769 IDLE UNKNOWN 35888 0 0 0 0
1 0 RFS 30774 IDLE UNKNOWN 141997 0 0 0 0
1 0 RFS 30776 IDLE UNKNOWN 142133 0 0 0 0
1 0 RFS 30778 IDLE UNKNOWN 35867 0 0 0 0
1 0 DGRD 31472 ALLOCATED N/A N/A 0 0 0 0
1 0 DGRD 31474 ALLOCATED N/A N/A 0 0 0 0
2 0 DGRD 85340 ALLOCATED N/A N/A 0 0 0 0
2 0 DGRD 85344 ALLOCATED N/A N/A 0 0 0 0
1 1 MRP0 101677 WAIT_FOR_GAP N/A N/A 32263 0 128 128
1 1 RFS 28815 IDLE Archival 141782 0 0 0 0
1 1 RFS 28906 IDLE LGWR 136732 32302 398785 0 0
1 2 RFS 28820 IDLE Archival 35812 0 0 0 0
1 2 RFS 28912 IDLE LGWR 91132 28726 10390 0 0
1 2 ARCH 31470 CLOSING ARCH 31470 28698 81920 0 0
1 2 ARCH 31478 CLOSING ARCH 31478 28700 1 0 0
1 2 ARCH 31480 CLOSING ARCH 31480 28699 18432 0 0
1 2 ARCH 31482 CLOSING ARCH 31482 28701 28672 0 0
2 2 ARCH 85325 CLOSING ARCH 85325 24857 36864 0 0
2 2 ARCH 85377 CLOSING ARCH 85377 24852 22528 0 0
2 2 ARCH 85379 CLOSING ARCH 85379 24855 1 0 0
2 2 ARCH 85381 CLOSING ARCH 85381 24853 26624 0 0
23 rows selected.
SQL> select * from v$archive_gap;
THREAD# LOW_SEQUENCE# HIGH_SEQUENCE# CON_ID
---------- ------------- -------------- ----------
1 32263 32284 1
可见我们现在缺少thread 1的seq 32263-32284之间21个归档日志。
故障分析
参考前面的文章:https://www.modb.pro/db/175815#_405
恢复GAP有两种方法:
一、gap较少,或者归档日志还存在,或者可以从备份集中恢复出来可以直接将缺少的归档scp到standby,在standby手工注册下即可。
二、gap较多,在primary 做基于scn的backup,同时创建一个新的standbycontrolfile,将备份好的backupset ,standby controlfile 拷贝到备库的相应目录下,进行restore、recover的操作即可。
此处的GAP较少,可以采用恢复出删除的归档日志进行恢复。但是前提要由备份,和要能恢复出来。
主要以下两个命令:
RMAN> list archivelog from sequence 32263 until sequence 32284 thread 1;
RMAN> list backup of archivelog from sequence 32263 until sequence 32284 thread 1;
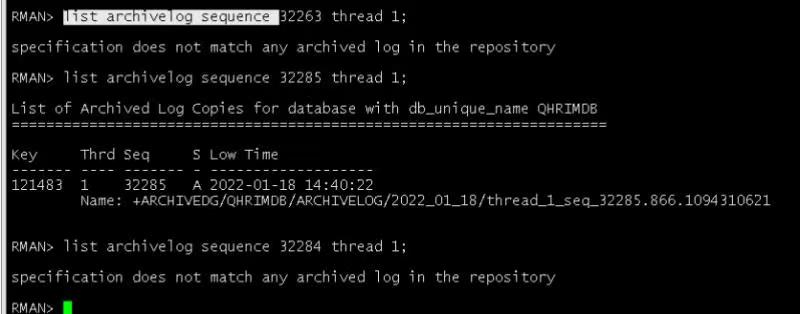
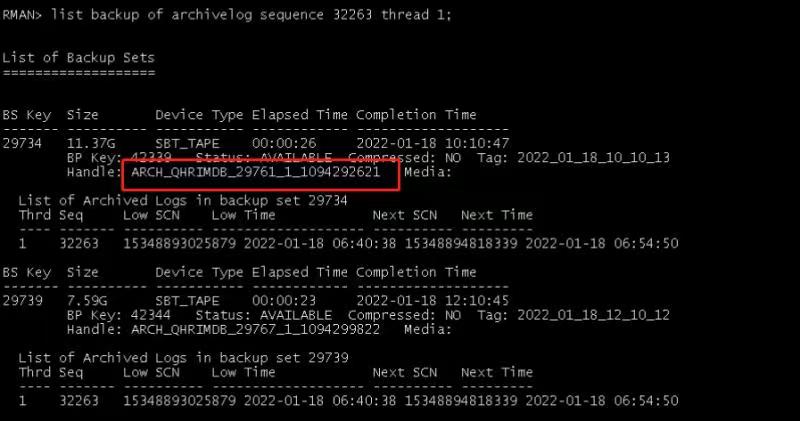
可见归档日志确实被删除,但是这些归档日志都已经被备份了。我们可以尝试从备份集中恢复出这些被删除的归档日志。
先尝试恢复一个:
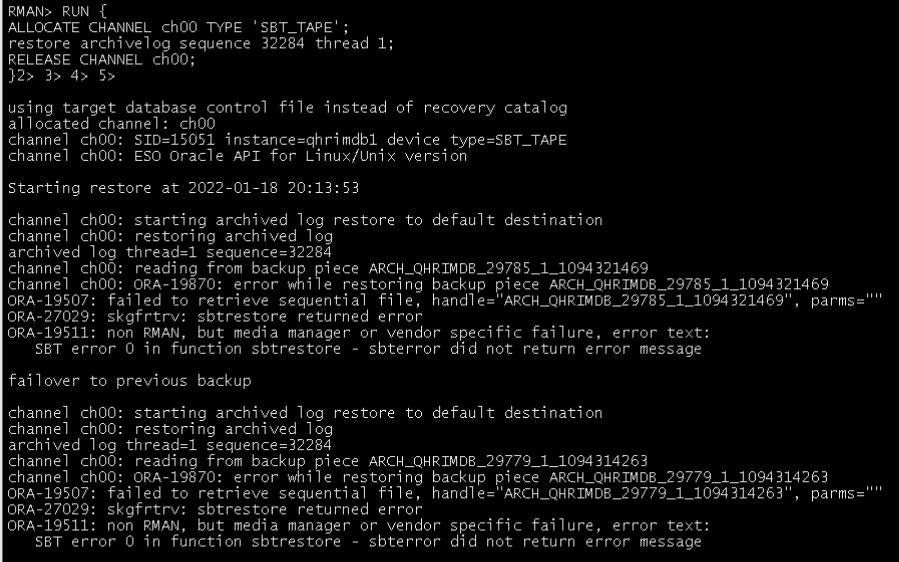
恢复报错。由于没有写parms参数。
经咨询,备份采用的是华为备份软件DPA。华为自己的维护人员也不知道应该怎么恢复,而且只能全量恢复,不能恢复单个归档日志。此处吐槽一下,不知道是现场人员的问题还是DPA本身的问题,对于不能恢复单个归档日志,实在是不应该,这是最常用的场景。如果这里有熟悉DPA的人,也可以和我沟通下,怎么恢复。
类似nbu恢复这种,就可以正常恢复:

所以此处不再考虑恢复删除的归档日志恢复,采用基于scn的增量备份恢复的方案来恢复ADG GAP。
GAP恢复
参考mos:18c Roll Forward Physical Standby Using RMAN Incremental Backup in Single Command (Doc ID 2431311.1)
12c之后恢复ADG的GAP步骤简单了,有新特性了。
Typically, when rolling forward a physical standby database using primary incremental backup, multiple steps are required:
Identify the Start SCN on Standby for performing incremental backup on primary
Perform incremental backup on primary with FROM SCN clause
Move the backup-pieces from primary to standby
Catalog the backup-piece on Standby
Perform recovery on standby using recover database noredo
Refresh standby controlfile again from primary
Starting from 12.1, we could use "RECOVER DATABASE FROM SERVICE"command which will automate a few steps like performing incremental backup on primary, transfer the backup-pieces to standby over network and perform recovery on standby. However, we still had to manually refresh the standby controlfile and manually restore newly-added datafiles. These steps required manual efforts and are error prone especially when standby files are physically located in a path different to that of primary.
Starting with 18.1, we can use a single command to refresh the standby with changes made on primary:
RMAN> RECOVER STANDBY DATABASE FROM SERVICE primary_connect_identifier;
This command will internally keep track of standby file locations, refresh standby controlfile from primary, update the new standby controlfile with standby file names, perform incremental backup on primary, transfer the backup-pieces over network to standby and perform recovery on standby
12.1之前,主要的恢复步骤,参考之前的文章。
12.1之后,需要recover database from service ,然后重新恢复控制文件,恢复新增数据文件。
18.1之后,更简单了,直接一条命令就包括了所有的恢复步骤。
正式开始前需要注意两个地方:
1、确认主库的TNS已配置,这里的< PRIMARY DB SERVICE NAME >即 TNSNAME。
2、If the standby is RAC with more than one instance, make sure only the instance from which recover standby command will be executed is mounted and all other instances are shutdown to avoid RMAN-05157。
必须保证出恢复节点外,剩余节点的实例都是关闭状态。否则报错RMAN-05157.这其实和手动duplicate的时候的要求一致。
RMAN> recover standby database from service priqhrimdb;
Starting recover at 2022-01-18 20:35:02
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of recover command at 01/18/2022 20:35:03
RMAN-05157: The database must not be mounted on any other instance for RECOVER STANDBY DATABASE command.
具体步骤如下:
- 执行增量恢复
- 启动mrp,open数据库
- 修改standby日志和redo log没有转化过来的文件路径
- 启动mrp
- 检查同步状态
- 执行增量恢复
RMAN> recover standby database from service priqhrimdb;
qhrimdb1:/oracle/app/oracle/product/19.0.0/db/network/admin(qhrimdb1)$rman target /
Recovery Manager: Release 19.0.0.0.0 - Production on Tue Jan 18 20:51:36 2022
Version 19.9.0.0.0
Copyright (c) 1982, 2019, Oracle and/or its affiliates. All rights reserved.
connected to target database: QHRIMDB (DBID=1354654563)
RMAN> recover standby database from service priqhrimdb;
Starting recover at 2022-01-18 20:51:43
Oracle instance started
Total System Global Area 387620796704 bytes
Fixed Size 30951712 bytes
Variable Size 112541564928 bytes
Database Buffers 274877906944 bytes
Redo Buffers 170373120 bytes
contents of Memory Script:
restore standby controlfile from service 'priqhrimdb'; --重新恢复控制文件
alter database mount standby database;
executing Memory Script
Starting restore at 2022-01-18 20:52:06
using target database control file instead of recovery catalog
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=3188 instance=qhrimdb1 device type=DISK
channel ORA_DISK_1: starting datafile backup set restore
channel ORA_DISK_1: using network backup set from service priqhrimdb
channel ORA_DISK_1: restoring control file
channel ORA_DISK_1: restore complete, elapsed time: 00:00:04
output file name=+DATADG1/QHRIMDB/CONTROLFILE/control_files01.ctl
Finished restore at 2022-01-18 20:52:12
released channel: ORA_DISK_1
Statement processed
Executing: alter system set standby_file_management=manual
RMAN-05529: warning: DB_FILE_NAME_CONVERT resulted in invalid ASM names; names changed to disk group only.
contents of Memory Script:
set newname for tempfile 1 to
"+DATADG1/QHRIMDBSTD/TEMPFILE/temp.315.1048266439";
set newname for tempfile 2 to
"+DATADG1/QHRIMDBSTD/AAC3F48E60DFEF9CE053243DE60AC007/TEMPFILE/temp.316.1048266441";
set newname for tempfile 3 to
"+DATADG1/QHRIMDBSTD/ABF515494C5840B0E053243DE60ADF28/TEMPFILE/temp.339.1048266865";
.........
contents of Memory Script:
set newname for tempfile 1 to
"+DATADG1/QHRIMDBSTD/TEMPFILE/temp.315.1048266439";
set newname for tempfile 2 to
"+DATADG1/QHRIMDBSTD/AAC3F48E60DFEF9CE053243DE60AC007/TEMPFILE/temp.316.1048266441";
set newname for tempfile 3 to
"+DATADG1/QHRIMDBSTD/ABF515494C5840B0E053243DE60ADF28/TEMPFILE/temp.339.1048266865";
.........
set newname for datafile 483 to
"+DATADG2/QHRIMDBSTD/DATAFILE/undotbs2.396.1094268467";
set newname for datafile 484 to
"+DATADG2/QHRIMDBSTD/DATAFILE/sysaux.397.1094268911";
catalog datafilecopy "+DATADG1/QHRIMDBSTD/DATAFILE/system.287.1048266159",
"+DATADG1/QHRIMDBSTD/AAC3F48E60DFEF9CE053243DE60AC007/DATAFILE/system.278.1048266179",
"+DATADG1/QHRIMDBSTD/DATAFILE/sysaux.267.1048266165",
"+DATADG1/QHRIMDBSTD/AAC3F48E60DFEF9CE053243DE60AC007/DATAFILE/sysaux.281.1048266177",
..........
"+DATADG2/QHRIMDBSTD/B198F463B60BD808E053243DE60AC13B/DATAFILE/tbs_roam_data.395.1093864019",
"+DATADG2/QHRIMDBSTD/DATAFILE/undotbs2.396.1094268467",
"+DATADG2/QHRIMDBSTD/DATAFILE/sysaux.397.1094268911";
switch datafile all; --刷新控制文件中,修改备库控制文件中数据文件路径
executing Memory Script
executing command: SET NEWNAME
executing command: SET NEWNAME
.........
executing command: SET NEWNAME
cataloged datafile copy
datafile copy file name=+DATADG1/QHRIMDBSTD/DATAFILE/system.287.1048266159 RECID=1 STAMP=1094331155
cataloged datafile copy
datafile copy file name=+DATADG1/QHRIMDBSTD/AAC3F48E60DFEF9CE053243DE60AC007/DATAFILE/system.278.1048266179 RECID=2 STAMP=1094331155
cataloged datafile copy
datafile copy file name=+DATADG1/QHRIMDBSTD/DATAFILE/sysaux.267.1048266165 RECID=3 STAMP=1094331155
..........
datafile 1 switched to datafile copy
input datafile copy RECID=1 STAMP=1094331155 file name=+DATADG1/QHRIMDBSTD/DATAFILE/system.287.1048266159
datafile 2 switched to datafile copy
input datafile copy RECID=2 STAMP=1094331155 file name=+DATADG1/QHRIMDBSTD/AAC3F48E60DFEF9CE053243DE60AC007/DATAFILE/system.278.1048266179
datafile 3 switched to datafile copy
input datafile copy RECID=3 STAMP=1094331155 file name=+DATADG1/QHRIMDBSTD/DATAFILE/sysaux.267.1048266165
.........
datafile 484 switched to datafile copy
input datafile copy RECID=418 STAMP=1094331169 file name=+DATADG2/QHRIMDBSTD/DATAFILE/sysaux.397.1094268911
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_5.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_5.258.1048266211'
Oracle error from target database:
ORA-19528: redo logs being cleared may need access to files
RMAN-05535: warning: All redo log files were not defined properly.
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_6.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_6.259.1048266215'
Oracle error from target database:
ORA-19528: redo logs being cleared may need access to files
RMAN-05535: warning: All redo log files were not defined properly.
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_7.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_7.271.1048266219'
Oracle error from target database:
ORA-19528: redo logs being cleared may need access to files
RMAN-05535: warning: All redo log files were not defined properly.
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_8.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_8.296.1048266223'
Oracle error from target database:
ORA-19528: redo logs being cleared may need access to files
RMAN-05535: warning: All redo log files were not defined properly.
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_9.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_9.295.1048266227'
Oracle error from target database:
ORA-19528: redo logs being cleared may need access to files
RMAN-05535: warning: All redo log files were not defined properly.
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_10.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_10.294.1048266233'
Oracle error from target database:
ORA-19528: redo logs being cleared may need access to files
RMAN-05535: warning: All redo log files were not defined properly.
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_11.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_11.293.1048266237'
Oracle error from target database:
ORA-19528: redo logs being cleared may need access to files
RMAN-05535: warning: All redo log files were not defined properly.
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_12.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_12.270.1048266241'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_13.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_13.291.1048266245'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_14.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_14.290.1048266249'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_15.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_15.286.1048266255'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_16.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_16.284.1048266259'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_17.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_17.279.1048266263'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_18.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_18.275.1048266267'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_19.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_19.274.1048266271'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_20.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_20.273.1048266277'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_21.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_21.269.1048266281'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_22.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_22.268.1048266285'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_23.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_23.265.1048266289'
Executing: alter database rename file '+DATADG1/MUST_RENAME_THIS_LOGFILE_24.4294967295.4294967295' to '+DATADG1/QHRIMDBSTD/ONLINELOG/group_24.264.1048266293'
contents of Memory Script:
recover database from service 'priqhrimdb'; --直接在线进行增量备份和恢复。
executing Memory Script
Starting recover at 2022-01-18 20:57:06
allocated channel: ORA_DISK_1
channel ORA_DISK_1: SID=1594 instance=qhrimdb1 device type=DISK
channel ORA_DISK_1: starting incremental datafile backup set restore
channel ORA_DISK_1: using network backup set from service priqhrimdb
destination for restore of datafile 00001: +DATADG1/QHRIMDBSTD/DATAFILE/system.287.1048266159
channel ORA_DISK_1: restore complete, elapsed time: 00:00:04
channel ORA_DISK_1: starting incremental datafile backup set restore
channel ORA_DISK_1: using network backup set from service priqhrimdb
destination for restore of datafile 00002: +DATADG1/QHRIMDBSTD/AAC3F48E60DFEF9CE053243DE60AC007/DATAFILE/system.278.1048266179
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
channel ORA_DISK_1: starting incremental datafile backup set restore
channel ORA_DISK_1: using network backup set from service priqhrimdb
destination for restore of datafile 00003: +DATADG1/QHRIMDBSTD/DATAFILE/sysaux.267.1048266165
channel ORA_DISK_1: restore complete, elapsed time: 00:00:01
..............
channel ORA_DISK_1: restore complete, elapsed time: 00:00:15
channel ORA_DISK_1: starting incremental datafile backup set restore
channel ORA_DISK_1: using network backup set from service priqhrimdb
destination for restore of datafile 00484: +DATADG2/QHRIMDBSTD/DATAFILE/sysaux.397.1094268911
channel ORA_DISK_1: restore complete, elapsed time: 00:00:15
starting media recovery
archived log for thread 1 with sequence 32307 is already on disk as file +ARCHIVEDG/QHRIMDBSTD/ARCHIVELOG/2022_01_18/thread_1_seq_32307.1018.1094332275
archived log for thread 1 with sequence 32308 is already on disk as file +ARCHIVEDG/QHRIMDBSTD/ARCHIVELOG/2022_01_18/thread_1_seq_32308.1084.1094334077
archived log for thread 1 with sequence 32309 is already on disk as file +ARCHIVEDG/QHRIMDBSTD/ARCHIVELOG/2022_01_18/thread_1_seq_32309.1047.1094335877
archived log 以上是关于oracle 19c adg GAP恢复的主要内容,如果未能解决你的问题,请参考以下文章