Azure Data PlatformAzure SQLDW与ADLS的整合
Posted 發糞塗牆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Azure Data PlatformAzure SQLDW与ADLS的整合相关的知识,希望对你有一定的参考价值。
本文属于【Azure Data Platform】系列。
接上文:【Azure Data Platform】Azure Data Lake(1)——简介
前言
在Azure上面,已经没有了data warehouse这种称呼,不过我还是偏向于使用SQL DW作为 Azure Synapse Analytics 的叫法。毕竟SQL DW还是行业称呼,没有用过Azure Synapse的人可能不熟悉它是什么东西。
其实 Azure Synapse Analytics 代表着在Data lake上的大数据与传统数据仓库的整合。
随着原始数据的指数级增长,需要一个存储这类数据的场所,传统存储已经无法高效低成本地满足需求,所以出现了数据湖。要知道传统的存储,PB级别的费用是数以百万的。因此,在过去几年中,许多大型组织已经建立了庞大的数据湖,但很难将其链接到现有的企业数据仓库中。
在许多情况下,IT 系统花费大量时间将传统数据仓库数据通过ETL移动到数据湖中,以便对数据进行进一步的使用。
现在借助 Azure Synapses Analytics,你可以组合来自 Azure Data Lake 或 BLOB Storage 的庞大数据集,并能够利用Azure Synapse Analytics (SQL DW) 的 MPP 体系结构高效处理数据。
为了实现这种目的,需要引入一些新的技术和架构。
首先是数据存储方面,借助Azure Blob storage或Data Lake Gen2(这里就不讨论Gen1了)。相对于直接存储在DW里面,可以节省大概17%~70%的成本。
然后是数据处理,先不谈SQL DW的MPP架构,Azure通过Spark,HDInsight,并且借助诸如R,Python,Scala语言等,对大数据进行高效分析处理。比起传统的SQL 分析功能更加丰富,速度也更快。当然钱也更多。比如使用Databricks。
过去的ETL过程,需要数据移动,而今时今日的大数据处理,已经逐步转向ELT,更多的是对数据的直接处理,尽可能减少数据的移动。也就是说你可以在ADLS上进行编程。
Azure SQL DW与ADLS
Azure SQL DW可以通过外部表(external table)直接访问ADLS上的数据文件(某些符合标准的文件中的数据也可以),在数据库中对其进行数据查询,处理。其性能当然不可能跟完全在SQL DW中的实体表相提并论,但是对于超大型的数据集比如PB级别的数据,这种方法可以避免很多抽取时间和存储费用。
很难描述某些提升对整个性能有多大的帮助。过去,需要创建文件的加载过程,这些过程会将非常大的数据集加载到SQL DW中以进行进一步处理。这是一个耗时耗资源的过程。很多时候会遇到诸如文件损坏,数据类型问题,接收数据文件延迟等问题。这导致了大量的开发和生产支持工作来维护SQL DW的输入。此外,由于需要存储,因此存储成本增加了一倍以上。
但是,使用 Azure SQL DW,这些问题已大大缓解,因为数据文件已经驻留在 Azure BLOB storage或ADLS中。一旦文件存储到这些存储上,它们就可以被查询,而无需加载数据。与不断将原始数据文件加载到SQL DW中的旧SQL DW策略相比,这是一个巨大的优势。同时,无需将此数据移回数据湖供数据科学家使用。使用Databricks也可以直接访问SQL DW中的数据。
如果你觉得需要存储在数据库中,那么SQL DW的MPP架构和列式存储也可以进一度提高大数据的操作速度。特别是列存储索引,从SQL Server 2012就开始引入,通过高度压缩对应的列,减少数据加载到缓存的时间和空间,从而大幅度降低处理速度,通常可以快10~100倍。
外部表跟传统表的区别
外部表(external table)就像个指针,或者一条桥,打通SQL DW和ADLS/BLOB。并且它还是一个数据结构,定义了数据最终呈现的样子。从定义中,还体现出数据源,文件格式这样的信息。之所以称为外部表是因为它并不实际存储数据在SQL DW中,通过PolyBase这个技术来访问SQL DW之外的数据。
要创建外部表,需要以下6步,步骤来自于官方文档配置外部表:
- 创建数据库主密钥(如果尚不存在)。 这是加密凭据密钥所必需的。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
- 为受 Kerberos 保护的 Hadoop 群集创建数据库范围凭据。
-- IDENTITY: the Kerberos user name.
-- SECRET: the Kerberos password
CREATE DATABASE SCOPED CREDENTIAL HadoopUser1
WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';
- 使用 CREATE EXTERNAL DATA SOURCE 创建外部数据源。
-- LOCATION (Required) : Hadoop Name Node IP address and port.
-- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation.
-- CREDENTIAL (Optional): the database scoped credential, created above.
CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH (
TYPE = HADOOP,
LOCATION ='hdfs://10.xxx.xx.xxx:xxxx',
RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx',
CREDENTIAL = HadoopUser1
);
- 使用 CREATE EXTERNAL FILE FORMAT 创建外部文件格式。
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET).
CREATE EXTERNAL FILE FORMAT TextFileFormat WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|',
USE_TYPE_DEFAULT = TRUE))
- 使用 CREATE EXTERNAL TABLE 创建指向存储在 Hadoop 中的数据的外部表。 在此示例中,外部数据包含汽车传感器数据。
-- LOCATION: path to file or directory that contains the data (relative to HDFS root).
CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] (
[SensorKey] int NOT NULL,
[CustomerKey] int NOT NULL,
[GeographyKey] int NULL,
[Speed] float NOT NULL,
[YearMeasured] int NOT NULL
)
WITH (LOCATION='/Demo/',
DATA_SOURCE = MyHadoopCluster,
FILE_FORMAT = TextFileFormat
);
- 在外部表上创建统计信息。
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
理想的ADLS 上的文件格式
注意这里说的是理想的,很多时候我们很难有选择的余地,不过再某些情况下,比如项目内部需要自定义数据归档(从SQL DW导出数据到ADLS)时,则可以做一些选择。
PolyBase 原生支持 CSV 未压缩文件(或使用 GZIP 压缩)、Hive RCFile、Hive ORC 和 Parquet 文件。但是如果可能,则尽量使用 Parquet 。因为Parquet文件是在Hadoop生态系统中设计的,以实现快速的性能和检索。而Blob跟ADLS 都基于Hadoop生态,这些文件可以更快地载入SQL DW,有时候速度比其他文件高 13 倍。如果列更少的话,提高幅度更明显。
Parquet 文件以压缩列式格式存储数据,所以对于列数不多的情况时最理想的格式。
数据应该存放在数据湖?还是在SQL DW?还是都存放?
对于这类选择性的问题,我的观点一般都是选择合适的功能满足合适的需求,而不是偏向于只选择一个。一个复杂的系统往往有很多组件、部分,所以使用最合适的工具应对各个细节需求才是最合适的。
使用数据仓库
我们可以通过传统的SQL和关系数据库理论来处理规范化的数据。同时借助外部表来实现对外部文件的操作,虽然性能并不能与传统表相提并论。但是在频率不高的情况下,反而性价比更高。
使用数据湖
无论Blob还是ADLS Gen2。 它们都是“存储”服务,没有很强的计算能力,特别是对于更新和删除操作。
下表是从网上收集的,列出来一些技术的适用场景:

在后来还出现了Serverless SQL Pool, Delta lake 等可用的技术,不过由于篇幅有限不打算扩充,后续有机会再继续介绍。
可能是两全其美的方案
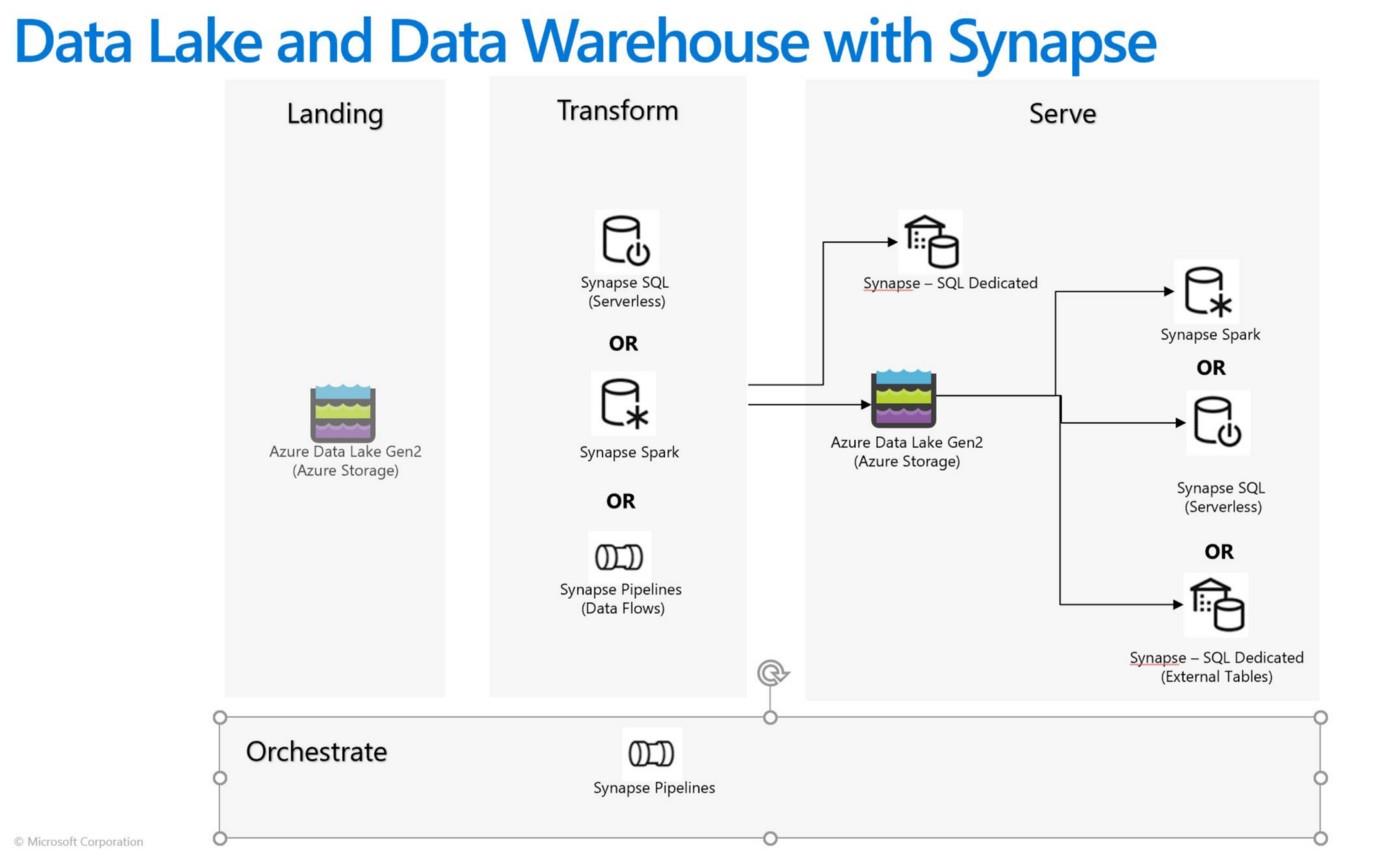
首先Data Lake 用于在快速读取,适合对超大型数据集,具有成本效益,它能够以较低的成本进行实验和临时分析。但转换后的结果需要加载到关系引擎(如 Synapse SQL 专用池)以实现低延迟和更高并发要求,如报表。
而使用关系引擎对较小的数据集进行数据服务。下图是从微软网站收集的图片,可以作为参考。
以上是关于Azure Data PlatformAzure SQLDW与ADLS的整合的主要内容,如果未能解决你的问题,请参考以下文章