dom4j解析xmljavaweb三层架构初探
Posted 李春春_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了dom4j解析xmljavaweb三层架构初探相关的知识,希望对你有一定的参考价值。
前言
前面的博客中,我提到了xml的dom、sax、stax解析,还有一种更加主流方便的解析方式——dom4j。
Dom4j、XPath
Dom4j是一个简单、灵活的开放源代码的库。Dom4j是由早期开发JDOM的人分离出来而后独立开发的。与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j的API相对要复杂一些,但它提供了比JDOM更好的灵活性。
Dom4j是一个非常优秀的Java XML API,具有性能优异、功能强大和极易使用的特点。现在很多软件采用的Dom4j,例如Hibernate,包括sun公司自己的JAXM也用了Dom4j。
使用Dom4j开发,需下载dom4j相应的jar文件:dom4j-1.6.1.jar、jaxen-1.1-beta-6.jar等。
代码示例:
book.xml:
<?xml version="1.0" encoding="utf-8"?>
<书架>
<书 name="yyyyyyy">
<售价>209元</售价>
<售价>2元</售价>
<书名>Java就业培训教程</书名>
<作者>张孝祥</作者>
<售价>19元</售价>
</书>
<书>
<书名>javascript网页开发</书名>
<作者>张孝祥</作者>
<售价>28.00元</售价>
</书>
</书架>user.xml:
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user username="aaa" password="123"></user>
<user username="bbb" password="123"></user>
<user username="ccc" password="123"></user>
</users>
package ustc.lichunchun.dom4j;
import java.io.File;
import java.io.FileOutputStream;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
/*
dom4j 增删改查、XPath
*/
public class Demo1
//读取xml文档数据:<书名>Java就业培训教程</书名>
@Test
public void read() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element root = document.getRootElement();
Element bookname = root.element("书").element("书名");
System.out.println(bookname.getText());
//<书 name="yyyyyyy">
@Test
public void readAttr() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element root = document.getRootElement();
String value = root.element("书").attributeValue("name");
System.out.println(value);
//向xml文档中添加<售价>19元</售价>
@Test
public void add() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("19元");
document.getRootElement().element("书").add(price);
//XMLWriter writer = new XMLWriter(new FileWriter("src/book.xml"));
//writer使用的是FileWriter的write()方法,查阅本地的GB2312编码写入文件,读取utf-8编码的document会写入乱码
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);//document是utf-8编码
writer.close();
//向指定位置增加售价结点
@Test
public void add2() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element price = DocumentHelper.createElement("售价");
price.setText("2元");
List list = document.getRootElement().element("书").elements();
list.add(1, price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);//document是utf-8编码
writer.close();
//修改:<售价>109</售价> 为209
@Test
public void update() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element price = (Element) document.getRootElement().element("书").elements("售价").get(1);
price.setText("209元");
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);//document是utf-8编码
writer.close();
//删除:<售价>109</售价>
@Test
public void delete() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element price = (Element) document.getRootElement().element("书").elements("售价").get(0);
price.getParent().remove(price);
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"), format);
writer.write(document);//document是utf-8编码
writer.close();
//通过XPath查找指定书名
@Test
public void findWithXpath() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element e = (Element) document.selectNodes("//书名").get(1);
System.out.println(e.getText());
//通过XPath查找指定xml文件中是否含有某用户信息
@Test
public void findUser() throws Exception
String username = "aaa";
String password = "123";
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/users.xml"));
Element e = (Element) document.selectSingleNode("//user[@username='"+username+"' and @password='"+password+"']");
if(e != null)
System.out.println("让用户登录成功!");
else
System.out.println("用户名和密码不正确!");
1、乱码问题:Dom4j在将文档载入内存时使用的是文档声明中encoding属性声明的编码集进行编码,如果在此时使用的writer的内部编码集与最初载入内存时使用的编码集不同则会出现乱码问题。FileWriter默认使用操作系统本地码表即gb2312编码,并且无法更改。
2、XMLWriter首先会将内存中的docuemnt翻译成UTF-8格式的document,在进行输出,这时有可能出现乱码问题。可以使用OutputFormat 指定XMLWriter转换的编码为其他编码。Writer使用的编码集与文档载入内存时使用的编码集不同导致乱码,使用字节流或自己封装指定编码的字符流即可。
综合示例
javabean+dao+util+xml 解析,进行学生信息增删改查。
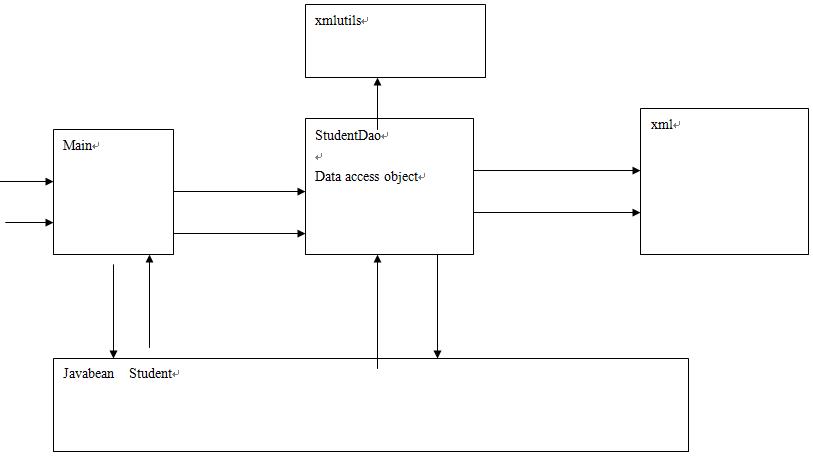
程序结构图:
xml 存储数据,student.xml:
<?xml version="1.0" encoding="utf-8"?>
<exam>
<student examid="222" idcard="111">
<name>张三</name>
<location>合肥</location>
<grade>90</grade>
</student>
<student examid="444" idcard="333">
<name>李四</name>
<location>上海</location>
<grade>96</grade>
</student>
<student examid="32423" idcard="342422">
<name>大王</name>
<location>南京</location>
<grade>43.0</grade>
</student>
</exam>
package ustc.lichunchun.domain;
public class Student
private String idcard;
private String examid;
private String name;
private String location;
private double grade;
public String getIdcard()
return idcard;
public void setIdcard(String idcard)
this.idcard = idcard;
public String getExamid()
return examid;
public void setExamid(String examid)
this.examid = examid;
public String getName()
return name;
public void setName(String name)
this.name = name;
public String getLocation()
return location;
public void setLocation(String location)
this.location = location;
public double getGrade()
return grade;
public void setGrade(double grade)
this.grade = grade;
package ustc.lichunchun.utils;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.xml.sax.SAXException;
public class XmlUtils
public static Document getDocument() throws ParserConfigurationException, SAXException, IOException
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
return builder.parse(new File("src/student.xml"));
public static void write2Xml(Document document) throws TransformerException
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(new File("src/student.xml")));
package ustc.lichunchun.utils;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.dom4j.Document;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
public class XmlUtilsForDom4j
public static Document getDocument() throws Exception
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/student.xml"));
return document;
public static void write2Xml(Document document) throws IOException
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("utf-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/student.xml"), format);
writer.write(document);
writer.close();
package ustc.lichunchun.dao;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import ustc.lichunchun.domain.Student;
import ustc.lichunchun.utils.XmlUtils;
public class StudentDaoByJaxp
public void add(Student student)
try
Document document = XmlUtils.getDocument();
Element student_node = document.createElement("student");
student_node.setAttribute("examid", student.getExamid());
student_node.setAttribute("idcard", student.getIdcard());
Element name = document.createElement("name");
name.setTextContent(student.getName());
Element location = document.createElement("location");
location.setTextContent(student.getLocation());
Element grade = document.createElement("grade");
grade.setTextContent(student.getGrade()+"");
student_node.appendChild(name);
student_node.appendChild(location);
student_node.appendChild(grade);
document.getElementsByTagName("exam").item(0).appendChild(student_node);
XmlUtils.write2Xml(document);
catch(Exception e)
throw new RuntimeException(e);
public Student find(String examid)
try
Document document = XmlUtils.getDocument();
NodeList list = document.getElementsByTagName("student");
for(int i = 0; i < list.getLength(); i++)
Element student = (Element)list.item(i);
String s_examid = student.getAttribute("examid");
if(s_examid.equals(examid))
//一旦找到
Student s = new Student();
s.setExamid(student.getAttribute("examid"));
s.setIdcard(student.getAttribute("idcard"));
s.setName(student.getElementsByTagName("name").item(0).getTextContent());
s.setLocation(student.getElementsByTagName("location").item(0).getTextContent());
s.setGrade(Double.parseDouble(student.getElementsByTagName("grade").item(0).getTextContent()));
return s;
return null;
catch (Exception e)
throw new RuntimeException(e);
public void delete(String name)
try
Document document = XmlUtils.getDocument();
NodeList list = document.getElementsByTagName("name");
for(int i = 0; i < list.getLength(); i++)
Node node = list.item(i);
if(node.getTextContent().equals(name))
node.getParentNode().getParentNode().removeChild(node.getParentNode());
XmlUtils.write2Xml(document);
return;
throw new RuntimeException("对不起,您要删除的学生不存在!!");//异常也是一种返回
catch(Exception e)
throw new RuntimeException(e);
package ustc.lichunchun.dao;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import ustc.lichunchun.domain.Student;
import ustc.lichunchun.utils.XmlUtilsForDom4j;
//dom4j
/*
*
* <student examid="222" idcard="111">
<name>张三</name>
<location>沈阳</location>
<grade>89</grade>
</student>
*/
public class StudentDaoByDom4j
public void add(Student student)
try
Document document = XmlUtilsForDom4j.getDocument();
Element student_node = DocumentHelper.createElement("student");
student_node.addAttribute("examid", student.getExamid());
student_node.addAttribute("idcard", student.getIdcard());
//向指定结点上挂子结点的便捷方式
student_node.addElement("name").setText(student.getName());
student_node.addElement("location").setText(student.getLocation());
student_node.addElement("grade").setText(student.getGrade()+"");
document.getRootElement().add(student_node);
XmlUtilsForDom4j.write2Xml(document);
catch(Exception e)
throw new RuntimeException(e);
public void delete(String name) //张三
try
Document document = XmlUtilsForDom4j.getDocument();
List list = document.selectNodes("//name");
Iterator it = list.iterator();
while(it.hasNext())
Element name_node = (Element) it.next(); //<name>
if(name_node.getText().equals(name))
name_node.getParent().getParent().remove(name_node.getParent());
XmlUtilsForDom4j.write2Xml(document);
return;
throw new RuntimeException("对不起,要删除的学生没有找到!");
catch(Exception e)
throw new RuntimeException(e);
public Student find(String examid) //<student examid=""
try
Document document = XmlUtilsForDom4j.getDocument();
Element node = (Element) document.selectSingleNode("//student[@examid='"+examid+"']");
if(node != null)
Student s = new Student();
s.setExamid(node.attributeValue("examid"));
s.setIdcard(node.attributeValue("idcard"));
s.setName(node.element("name").getText());
s.setLocation(node.element("location").getText());
s.setGrade(Double.parseDouble(node.element("grade").getText()));
return s;
return null;
catch(Exception e)
throw new RuntimeException(e);
package ustc.lichunchun.view;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import ustc.lichunchun.dao.StudentDaoByDom4j;
import ustc.lichunchun.domain.Student;
public class Main
public static void main(String[] args) throws IOException
System.out.println("添加用户:(a) 查询成绩:(b) 删除用户:(c)");
System.out.print("请输入操作类型:");
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
String type = bufr.readLine();
if(type.equalsIgnoreCase("a"))
//添加学生
try
System.out.print("请输入学生姓名:");
String name = bufr.readLine();
System.out.print("请输入学生准考证号:");
String examid = bufr.readLine();
System.out.print("请输入学生身份证号:");
String idcard = bufr.readLine();
System.out.print("请输入学生所在地:");
String location = bufr.readLine();
System.out.print("请输入学生成绩:");
String grade = bufr.readLine();
Student student = new Student();
student.setExamid(examid);
student.setGrade(Double.parseDouble(grade));
student.setIdcard(idcard);
student.setLocation(location);
student.setName(name);
//StudentDaoByJaxp dao = new StudentDaoByJaxp();
StudentDaoByDom4j dao = new StudentDaoByDom4j();
//等后续博客提到JDBC时,这里的上层代码一行都不用改!
//在javaweb三层结构的层与层之间,添加接口,往后直接调用接口的方法,而不必关心底层实现的改变!
dao.add(student);
System.out.println("恭喜!录入成功!!!");
catch(Exception e)
System.out.println("对不起,录入失败!!");
else if(type.equalsIgnoreCase("b"))
//查找学生
System.out.print("请输入学生的准考证号:");
String examid = bufr.readLine();
//StudentDaoByJaxp dao = new StudentDaoByJaxp();
StudentDaoByDom4j dao = new StudentDaoByDom4j();
Student student = dao.find(examid);
if(student == null)
System.out.println("对不起,您要找的学生不存在!!");
else
System.out.println("您要找的学生信息如下:");
System.out.println("姓名:"+student.getName());
System.out.println("身份证:"+student.getIdcard());
System.out.println("准考证:"+student.getExamid());
System.out.println("所在地:"+student.getLocation());
System.out.println("成绩:"+student.getGrade());
else if(type.equalsIgnoreCase("c"))
//删除学生
try
System.out.print("请输入要删除学生的姓名:");
String name = bufr.readLine();
//StudentDaoByJaxp dao = new StudentDaoByJaxp();
StudentDaoByDom4j dao = new StudentDaoByDom4j();
dao.delete(name);
System.out.println("恭喜您,删除成功!!!");
catch(Exception e)
System.out.println(e.getMessage());
else
System.out.println("不支持此类操作!!!");
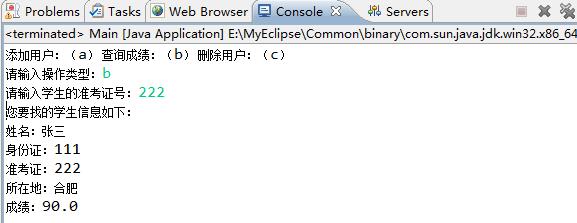
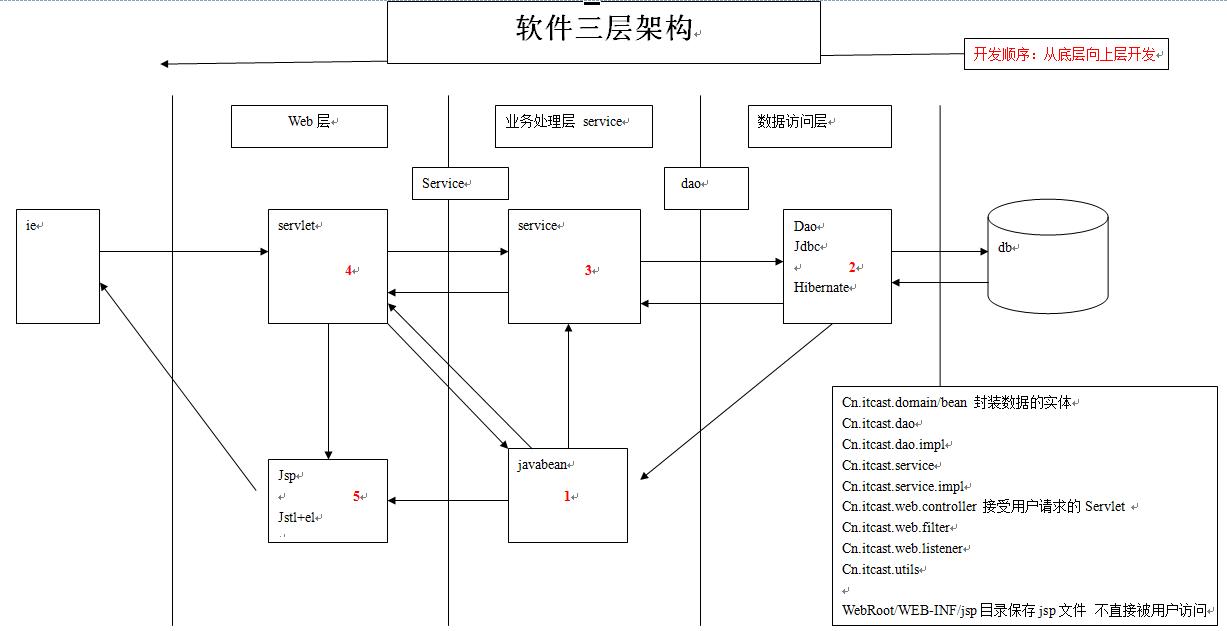
以上是关于dom4j解析xmljavaweb三层架构初探的主要内容,如果未能解决你的问题,请参考以下文章