libsvm java版本使用心得(转)
Posted 自助者天助!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了libsvm java版本使用心得(转)相关的知识,希望对你有一定的参考价值。
http://blog.csdn.net/u010340854/article/details/19159883
https://github.com/cjlin1/libsvm
项目中要用到svm分类器,自己实现的话太费时间,于是寻找开源实现,找到了libsvm。
Java版本是一个jar包,引入到工程中即可使用。
需要注意的是,java版本充满了c++风格(类名小写,命名使用下划线_分隔等等),使用者需要稍微适应一下。
核心类是svm类,最常用的几个方法如下(都是static方法):
svm.svm_load_model(String),望文生义即可知是加载已训练好的svm模型,参数是模型文件名。
svm.svm_save_model(String,svm_model),按指定的名称保存模型。
svm.svm_train(svm_problem,svm_parameter),训练模型,该方法有两个参数svm_problem,保存了训练数据,包括数据数,特征数组,类别数组。参数svm_parameter用户设置svm的一些参数,例如svm_type设置svm类型,kernel_type设置核函数类型等。训练时需要注意的是,如果你的训练数据比较多,训练时间可能很长。
svm.svm_predict(svm_model,svm_node[])和svm.svm_p
redict_probability(svm_model,svm_node[],double[]),都用于预测类别,不同的是后一个方法同时包含了预测类别的概率。
下面给出完整的demo:
- public class Test_svm_predict {
- public static void main(String[] args) {
- svm_problem sp = new svm_problem();
- svm_node[][] x = new svm_node[4][2];
- for (int i = 0; i < 4; i++) {
- for (int j = 0; j < 2; j++) {
- x[i][j] = new svm_node();
- }
- }
- x[0][0].index = 1;
- x[0][0].value = 0;
- x[0][1].index = 2;
- x[0][1].value = 0;
- x[1][0].index = 1;
- x[1][0].value = 1;
- x[1][1].index = 2;
- x[1][1].value = 1;
- x[2][0].index = 1;
- x[2][0].value = 0;
- x[2][1].index = 2;
- x[2][1].value = 1;
- x[3][0].index = 1;
- x[3][0].value = 1;
- x[3][1].value = 0;
- x[3][1].index = 2;
- double[] labels = new double[]{-1,-1,1,1};
- sp.x = x;
- sp.y = labels;
- sp.l = 4;
- svm_parameter prm = new svm_parameter();
- prm.svm_type = svm_parameter.C_SVC;
- prm.kernel_type = svm_parameter.RBF;
- prm.C = 1000;
- prm.eps = 0.0000001;
- prm.gamma = 10;
- prm.probability = 1;
- prm.cache_size=1024;
- /*
- * svm_check_parameter
- * 参数可行返回null,否则返回错误信息
- */
- System.out.println("Param Check " + (svm.svm_check_parameter(sp, prm)==null));
- svm_model model = svm.svm_train(sp, prm); //训练分类
- try {
- svm.svm_save_model("svm_model_file", model);
- } catch (IOException e) {
- e.printStackTrace();
- }
- try {
- svm.svm_load_model("svm_model_file");
- } catch (IOException e) {
- e.printStackTrace();
- }
- svm_node[] test = new svm_node[]{new svm_node(), new svm_node()};
- test[0].index = 1;
- test[0].value = 0;
- test[1].index = 2;
- test[1].value = 0;
- double[] l = new double[2];
- double result_prob = svm.svm_predict_probability(model, test,l); //测试1,带预测概率的分类测试
- double result_normal = svm.svm_predict(model, test); //测试2 不带概率的分类测试
- System.out.println("Result with prob " + result_prob);
- System.out.println("Result normal " + result_normal);
- System.out.println("Probability " + l[0] + "\t" + l[1]);
- }
- }
http://www.oschina.net/code/snippet_1246663_35454
1. [代码][Java]代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
import java.io.BufferedReader;import java.io.File;import java.io.FileReader;import java.util.ArrayList;import java.util.List;import libsvm.svm;import libsvm.svm_model;import libsvm.svm_node;import libsvm.svm_parameter;import libsvm.svm_problem;public class SVM { public static void main(String[] args) { // 定义训练集点a{10.0, 10.0} 和 点b{-10.0, -10.0},对应lable为{1.0, -1.0} List<Double> label = new ArrayList<Double>(); List<svm_node[]> nodeSet = new ArrayList<svm_node[]>(); getData(nodeSet, label, "file/train.txt"); int dataRange=nodeSet.get(0).length; svm_node[][] datas = new svm_node[nodeSet.size()][dataRange]; // 训练集的向量表 for (int i = 0; i < datas.length; i++) { for (int j = 0; j < dataRange; j++) { datas[i][j] = nodeSet.get(i)[j]; } } double[] lables = new double[label.size()]; // a,b 对应的lable for (int i = 0; i < lables.length; i++) { lables[i] = label.get(i); } // 定义svm_problem对象 svm_problem problem = new svm_problem(); problem.l = nodeSet.size(); // 向量个数 problem.x = datas; // 训练集向量表 problem.y = lables; // 对应的lable数组 // 定义svm_parameter对象 svm_parameter param = new svm_parameter(); param.svm_type = svm_parameter.EPSILON_SVR; param.kernel_type = svm_parameter.LINEAR; param.cache_size = 100; param.eps = 0.00001; param.C = 1.9; // 训练SVM分类模型 System.out.println(svm.svm_check_parameter(problem, param)); // 如果参数没有问题,则svm.svm_check_parameter()函数返回null,否则返回error描述。 svm_model model = svm.svm_train(problem, param); // svm.svm_train()训练出SVM分类模型 // 获取测试数据 List<Double> testlabel = new ArrayList<Double>(); List<svm_node[]> testnodeSet = new ArrayList<svm_node[]>(); getData(testnodeSet, testlabel, "file/test.txt"); svm_node[][] testdatas = new svm_node[testnodeSet.size()][dataRange]; // 训练集的向量表 for (int i = 0; i < testdatas.length; i++) { for (int j = 0; j < dataRange; j++) { testdatas[i][j] = testnodeSet.get(i)[j]; } } double[] testlables = new double[testlabel.size()]; // a,b 对应的lable for (int i = 0; i < testlables.length; i++) { testlables[i] = testlabel.get(i); } // 预测测试数据的lable double err = 0.0; for (int i = 0; i < testdatas.length; i++) { double truevalue = testlables[i]; System.out.print(truevalue + " "); double predictValue = svm.svm_predict(model, testdatas[i]); System.out.println(predictValue); err += Math.abs(predictValue - truevalue); } System.out.println("err=" + err / datas.length); } public static void getData(List<svm_node[]> nodeSet, List<Double> label, String filename) { try { FileReader fr = new FileReader(new File(filename)); BufferedReader br = new BufferedReader(fr); String line = null; while ((line = br.readLine()) != null) { String[] datas = line.split(","); svm_node[] vector = new svm_node[datas.length - 1]; for (int i = 0; i < datas.length - 1; i++) { svm_node node = new svm_node(); node.index = i + 1; node.value = Double.parseDouble(datas[i]); vector[i] = node; } nodeSet.add(vector); double lablevalue = Double.parseDouble(datas[datas.length - 1]); label.add(lablevalue); } } catch (Exception e) { e.printStackTrace(); } }} |
2. [代码]训练数据,最后一列为目标值
|
1
2
3
4
5
6
7
8
9
10
11
12
|
17.6,17.7,17.7,17.7,17.817.7,17.7,17.7,17.8,17.817.7,17.7,17.8,17.8,17.917.7,17.8,17.8,17.9,1817.8,17.8,17.9,18,18.117.8,17.9,18,18.1,18.217.9,18,18.1,18.2,18.418,18.1,18.2,18.4,18.618.1,18.2,18.4,18.6,18.718.2,18.4,18.6,18.7,18.918.4,18.6,18.7,18.9,19.118.6,18.7,18.9,19.1,19.3 |
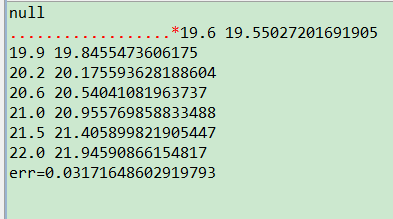
以上是关于libsvm java版本使用心得(转)的主要内容,如果未能解决你的问题,请参考以下文章