ARM汇编基础上
Posted 嘻嘻兮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ARM汇编基础上相关的知识,希望对你有一定的参考价值。
ARM是一个精简指令集处理器,其指令集的设计是定长的,也就是其汇编对应的机器码是定长的(2字节或者4字节)。那么对于定长而言,其优点就是更快的被执行,因为这样CPU取指令译码的速度相对x86的CPU会快一些,但是缺点也比较明显,毕竟定长,那么表示其指令有限(指令少),所以一定程度上会软件的复杂度(需要几条指令才能完成一个功能)。
ARM的指令集一开始设计定长都是2字节的,随着时间的发展,会发现指令可能已经不够表达了,所以后面又出现了4字节的指令集。对于2字节的指令集称为thumb指令集,而4字节的称为arm指令集。此时我们可以自由选择,如果需要体积小那么我们可以选择thumb编译,而需要性能更好可以选择arm指令集。
但是对于某些指令而言,比如加法,那么使用2字节和4字节的指令区别其实并不大,所以就出现了thumb2指令集,其指令集算是变长了(要么2字节要么4字节),算是集合了上面两种的指令集的优点,现在的ndk编译器只能编译出thumb2指令集合arm指令集了。
下面来说说ARM处理器的工作状态,也就是说CPU如何按几个字节来取指令译码,毕竟存在多套指令集
1.ARM状态
2.Thumb状态那么如何给CPU指令集指明状态呢?其实在标志寄存器中有一位来表示哪种状态,具体可以看下面的标志寄存器。
下面就可以说到寄存器了,如下图
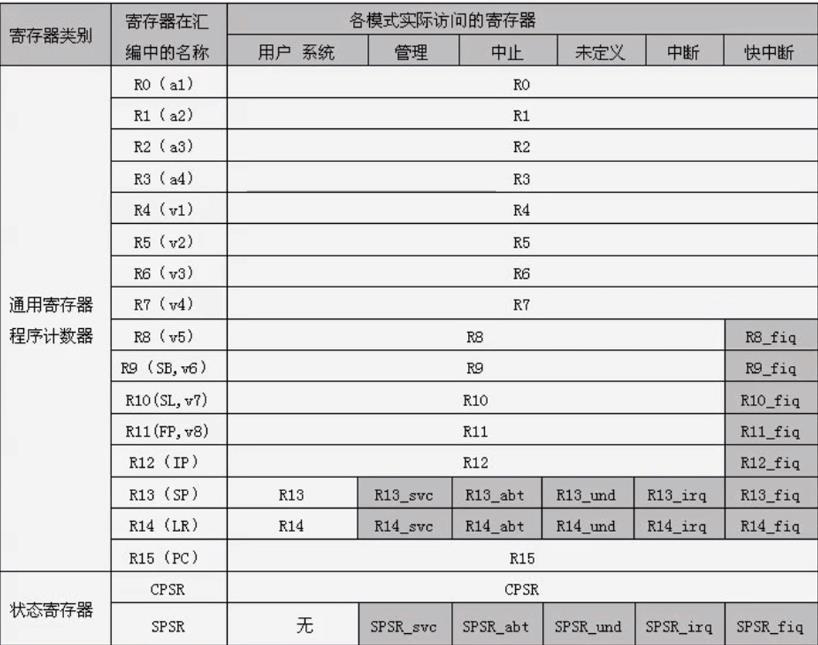
上图表示了不同的模式下对于寄存器的访问,那么什么是CPU的工作模式,简单来说也就是x86下的权限级别划分,也就是多少环的意思,在arm里共有7种模式,其实本质上说还是2种,也就是三环和0环,只是把0环拆分的更加细致了,所以多了这么多的模式出来。
对于ARM的寄存器,目前我们只需关心用户模式,只需记住以下两种,共17个寄存器可用
1.通用寄存器 R0-R15
2.标志寄存器 cpsr对于其他模式的寄存器,又会有其对应的寄存器,也就是上图中颜色比较深的那几个,但是对于寄存器的访问而言是一样的,比如说当进入了管理模式,那么我们使用SPSP寄存器访问的是SPSP_svc寄存器,而到了中止模式,我们还是只需使用SPSP寄存器,但是此时本质上访问的是SPSP_abt寄存器,无需关心真实的寄存器变化和名字。
通过上图也可以发现,不管在哪种模式下,其R0-R7,R15寄存器都是通用的。
下面再来稍微细说一下通用寄存器和程序计数器,在上图的寄存器在汇编中名字可以发现,其后面都有一个括号,表示的是寄存器别名,如下两指令是等价的
mov r15,#0
mov pc,#0一般而言,对于R13,R14,R15这三个寄存器都使用别名来编码,因为这样子可读性更好(有特殊含义),其余都使用R0-R12表示
PC - r15 程序寄存器,类似于eip
LR - r14 链接寄存器,类似于CALL指令,下条指令的地址在r14
SP - r13 堆栈指针r13和r15应该比较好理解,对于r14,在x86里面使用call指令会将返回地址压入堆栈,而这里表示返回地址在LR寄存器。但是该寄存器只有一个,表明当函数内部还有函数调用时,我们首先需要先保存LR寄存器,防止寄存器值被覆盖。
对于函数返回而言,此时就比较简单了,只需如下汇编指令就可返回
mov pc,lr下面就可以来说一下标志寄存器了

N : 当该位为1时表示负数,为0时表示正数
Z : 当该位为1时表示两数相等,为0时表示两数不相等
C : 当该位为1时,若为加法运算表示产生进位,否则该位为0 (减法运算中产生借位则该位置0,否则为1)
V : 使用加法/减法运算时,表示有符号溢出,否则该位为0
I : 当该位为1时,IRQ中断被禁止
F : 当该位为1时,FIQ中断被禁止
T : 当该位为1时,处理器处于Thumb状态下运行;该位为0时,处理器处于ARM状态下运行重点说一下对于C位,加法运算和减法运算其产生的值是不一样的。而对于T位,就是上面有说CPU使用何种工作状态。
最低五位表示CPU处理何种工作模式,也就是用于表示上面说的7种模式(权限),如用户模式则表示 10000。
对于编码而言,一般我们只需关心最高四位和T位即可。
下面就可以开始入手写一下ARM汇编代码,首先我们可以先写一份C代码,然后使用ndk编译出一份汇编代码,观察其框架结构
#include<stdio.h>
int main(int argc,char* argv[])
puts("hello arm");
return 0;
编译生成汇编的命令如下:
armv7a-linux-androideabi22-clang -E Hello.c -o Hello.i
armv7a-linux-androideabi22-clang -S Hello.i -o Hello.s注意这里需要添加一下ndk的环境变量,这里我的目录如下,大家根据目录对应修改添加即可
D:\\Android-NDK-r21\\toolchains\\llvm\\prebuilt\\windows-x86_64\\bin生成的.s文件就是对应的汇编文件,由于这里生成的汇编代码,有很多无用的伪指令(.开头的指令),所以我就精简一下,精简后的汇编代码如下:
.text @代码段
.fpu neon @浮点协处理器 soft表示软件模拟
.globl main @全局符号为main
.p2align 2 @对齐值,表示2^n
.type main,%function @指明main的类型,这里是一个函数
.code 32 @32表示arm指令集,16表示thumb指令集
main:
push r11, lr
mov r11, sp
sub sp, sp, #16
ldr r2, .LCPI0_0
.LPC0_0:
add r2, pc, r2
mov r0, r2
bl puts
movw r1, #0
mov r0, r1
mov sp, r11
pop r11, pc
.p2align 2
.LCPI0_0:
.long .L.str-(.LPC0_0+8) @定义数据
.Lfunc_end0:
.size main, .Lfunc_end0-main @函数的大小
.type .L.str,%object @ @.str
.section .rodata.str1.1,"aMS",%progbits,1 @定义rodata段
.L.str:
.asciz "hello arm" @字符串
.size .L.str, 10
.section ".note.GNU-stack","",%progbits @表示栈不能执行代码
在ARM里面,使用的是@进行注释,中间部分就是main的函数代码了,没有太多的注释,剩余的伪指令基本上都在后面注释了,下面先编译运行,看看结果是否正确,编译运行命令如下,注意需要先启动一个安卓模拟器或者真机
//编译链接生成可执行文件
armv7a-linux-androideabi22-clang -c Hello.s -o Hello.o
armv7a-linux-androideabi22-clang Hello.o -o Hello
//运行可执行文件
adb push Hello /data/local/tmp
adb shell chmod 777 /data/local/tmp/Hello
adb shell /data/local/tmp/Hello下面就解释一下上面的汇编代码,首先我们可以使用.section来定义一个段,在系统中预定了以下一些段、
.text:表示代码段
.data:表示初始化的数据段
.bss:表示未初始化的数据段
.rodata:表示只读数据段再来看对齐值伪指令,在ARM指令集中不可能有1字节的指令集,所以指令最低是2字节,任何段都是2的n次方,上面的汇编代码表示4字节对齐。
.code伪指令,如果是32,那么表示arm指令集,也就是生成的字节码都是4字节的,而16则表示thumb2指令集。这里可以修改为16然后使用IDA反汇编观察一下字节码即可。
再下面就是函数的汇编代码了,首先看首尾部分,这里和x86中汇编函数框架很类似,都是保存环境,提示堆栈的操作
push r11, lr @保存r11和lr寄存器,因为内部有函数调用,lr表示函数的返回地址,所以需要保存
mov r11, sp @保存sp
sub sp, sp, #16 @提升堆栈,立即数前面需要加#
@....
mov sp, r11 @还原堆栈
pop r11, pc @还原环境,这里原先lr保存的值给pc,表示返回需要额外注意的是原先保存的lr值最后是给了pc相当于上面说的返回
mov pc,lr @lr中保存着函数返回地址,给了pc相当于返回再来看中间的这串汇编代码,也就是调用puts函数
ldr r2, .LCPI0_0
.LPC0_0:
add r2, pc, r2
mov r0, r2
bl puts @bl指令表示函数调用对于puts函数而言,需要传递的应该是一个地址值,也就是字符串的首地址,对于ARM汇编中,mov是没有办法操作内存的,只有str/ldr指令用于存储和读取内存。由于一个地址值可能就需要占用4个字节,所以可能无法直接表示,那么我们就需要自己来计算该字符串的地址
pc + offset我们可以使用当前的指令的地址值加上对于的偏移,这里子就能计算出字符串的首地址了,所以LCPI0_0中其实存放的是偏移,然后使用ldr指令来加载偏移值,下一条add指令加上pc就是结果了。
.LCPI0_0:
.long .L.str-(.LPC0_0+8) @定义数据 .L.str-.LPC0_0-8.long表示定义4字节的数据,我们还可以使用.byte和.short来分别来定义单字节和双字节数据。
只是奇怪的是,对于偏移值而言,为什么最后还需要减8呢,这里因为在ARMCPU中,pc指向的不是当前的指令,而是下下条指令,也就是三级流水线。
地址
100: mov r0,pc @r0=108
104: mov r1,r2
108: mov r2,r3假设如上代码,其r0执行完的结果并不是100,而是108,具体的原因可以看下图

所以因为PC指向的是下下条指令,在arm指令中,每条指令占用4字节,所以减去8之后其偏移值+PC就正常了。那么如果对于.code伪指令的值改为16的话,那么这个值就需要修改为4了,这样子才能保证偏移值的正确。
OK,最后就可以说说函数的调用约定了,这里的约定是比较简单的,前四个寄存器使用R0~R3进行传递参数,剩余不够的使用堆栈传递参数,所以你会发现该字符串的地址值最后赋值给了r0。
好了,下面我们自己来添加一个函数,并尝试调用
.text
.fpu neon
.globl main @ -- Begin function main
.p2align 2
.type main,%function
.code 32 @ @main
main:
push r11, lr
mov r11, sp
sub sp, sp, #16
mov r0,#5 @传递参数一
mov r1,#8 @传递参数二
bl MyAdd @调用函数
ldr r2, .LCPI0_0
.LPC0_0:
add r2, pc, r2
movw r3, #0
mov r0, r2 @参数一 参数二在MyAdd的返回值中,正好是r1
bl printf @修改调用printf函数
movw r1, #0
str r0, [sp] @ 4-byte Spill
mov r0, r1
mov sp, r11
pop r11, pc
.p2align 2
.LCPI0_0:
.long .L.str-(.LPC0_0+8)
.Lfunc_end0:
.size main, .Lfunc_end0-main
.type MyAdd,%function
.code 32
MyAdd: @添加的add函数
add r1,r0,r1 @这里我的返回值放在r1
mov pc,lr @返回
.LMyAdd_end:
.size MyAdd,.LMyAdd_end-MyAdd
.type .L.str,%object @ @.str
.section .rodata.str1.1,"aMS",%progbits,1
.L.str:
.asciz "hello arm:%d" @修改字符串
.size .L.str, 13
.section ".note.GNU-stack","",%progbits
上面的代码中,对于Add函数,我就是偷懒了,把返回值放在r1寄存器中,因为在返回后,也没有对r1进行修改,这样子再调用printf函数时会自动取r1作为第二个参数。
执行结果如下:
adb push Hello /data/local/tmp
Hello: 1 file pushed. 0.7 MB/s (6560 bytes in 0.009s)
adb shell chmod 777 /data/local/tmp/Hello
adb shell /data/local/tmp/Hello
hello arm:13最后显示的就是打印的结果了,13是正确的,说明两个函数都被正确调用了。
以上是关于ARM汇编基础上的主要内容,如果未能解决你的问题,请参考以下文章