log4j是如何拖慢你的系统的
Posted 夜宿山寺
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了log4j是如何拖慢你的系统的相关的知识,希望对你有一定的参考价值。
log4j 引起的线上事故
1 问题起因
这个是在生产环境中发生的问题,第一次事故因为别人把大量的请求打来过来,猜测是机器扛不住,后来量少后发现问题不存在了,大致把问题定位是因为量的问题,也就准备后续的扩容,大概过了几个月,线上又发生了一次事故,事故的特征排查之后的特征就是打印log的速度非常慢,而且nginx处理速度也慢,同一个请求两个条日志之间间隔了好几秒, 经过运维排查后,是因为nginx worker数量不够,导致整体思路都被带到了nginx优化,包括worker的增加,直到第三次压力测试才完整的找出问题所在
2 问题排查过程
2.1 排查tomcat
线上项目机器配置是64核 128G,压力测试之后发觉集群tomcat总体qps大概到1200左右开始扛不住,也就大概单机600qps,起初找了一下网上很多人说Tomcat性能不行,很多人也是Tomcat600qps左右,怀疑tomcat扛不住,为了验证Tomcat,对另外一个查询了数据库的项目进行压测,纯查询数据库的qps达到了2000qps,Tomcat性能不高的这个可以否定了
2.2 排查log4j
因为两个log之间的输出时间经常超过好几秒,所以开始排查log4j,对log4j采用buffer进行输出,增加buffer大小,进行压力测试,buffer增加到了8M,发现并没有什么实际的效果,于是开始怀疑同步性能低
2.3 采用异步输出
怀疑是因为同步输出和普通磁盘,导致的问题,然后采用异步进行输出日志,发现qps开始无上限,为了保证跟线上环境一致,所以单独出一台pre环境进行测试,qps达到了6000,并且整个平均响应时间没有太大波动,然后停止了测试,担心把线上codis打垮,也是这个时候确认了是同步异步之间的性能问题。
2.4 因无法输出log的文件名和具体的代码行找出真正原因
采用异步之后,已经觉得基本解决了,也定位到是因为异步和同步之间的性能差距,于是发现log中多了几个问号,继续倒腾这个问题,查看源码后发现AsyncAppender中有一个locationInfo信息,默认是false,然后进行配置<param name="locationInfo" value="true"/>,解决了%l这个参数失效的问题,然后继续压测,这个时候发现,单机qps到了600多左右性能无法提升,这个时候才最终发现影响性能的问题是在于%l这个参数打印的数据问题,通过官网才真正确认了确是是这个参数的问题http://logging.apache.org/log4j/2.x/performance.html#asyncLoggingWithLocation,大概描述如下
“`
Some layouts can show the class, method and line number in the application where the logging call was made. In Log4j 2, examples of such layout options are HTML locationInfo, or one of the patterns %C or $class, %F or %file, %l or %location, %L or %line, %M or %method. In order to provide caller location information, the logging library will take a snapshot of the stack, and walk the stack trace to find the location information.
The graph below shows the performance impact of capturing caller location information when logging asynchronously from a single thread. Our tests show that capturing caller location has a similar impact across all logging libraries, and slows down asynchronous logging by about 30-100x.
“`
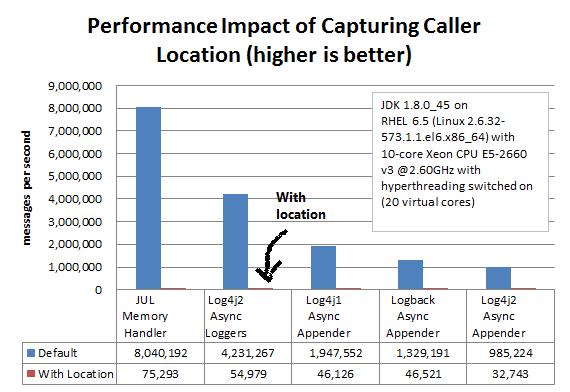
大概也就是说这些参数的使用会导致性能的急剧下降C or $class, %F or %file, %l or %location, %L or %line, %M or %method, 大概下降30-100倍左右,这才找到真正的原因
3 探讨Log4j的同步异步实现机制
3.1 同步实现机制
正常开发使用中,基本上都是使用的DailyRollingFileAppender,进行日志的输出
protected
void subAppend(LoggingEvent event)
this.qw.write(this.layout.format(event));
//.....
if(shouldFlush(event))
this.qw.flush();
protected boolean shouldFlush(final LoggingEvent event)
return immediateFlush;
public
synchronized
void setFile(String fileName, boolean append, boolean bufferedIO, int bufferSize)
throws IOException
//省略...
Writer fw = createWriter(ostream);
//如果有buffer就使用BufferedWriter
if(bufferedIO)
fw = new BufferedWriter(fw, bufferSize);
this.setQWForFiles(fw);
this.fileName = fileName;
this.fileAppend = append;
this.bufferedIO = bufferedIO;
this.bufferSize = bufferSize;
writeHeader();
LogLog.debug("setFile ended");
整体逻辑如下:
如果配置了没有配置buffer就立即flush,如果配置了等到buffer满的时候自动flush。flush能够很好的利用磁盘的性能,所以生产环境建议打开flush,但是有一个不方便的点,如果配置过大会导致不能立即看到日志
3.2 异步实现机制
/**
* Event buffer, also used as monitor to protect itself and
* discardMap from simulatenous modifications.
*/
private final List buffer = new ArrayList();
public void append(final LoggingEvent event)
//省略.....
synchronized (buffer)
while (true)
int previousSize = buffer.size();
if (previousSize < bufferSize)
buffer.add(event);
if (previousSize == 0)
buffer.notifyAll();
break;
boolean discard = true;
if (blocking
&& !Thread.interrupted()
&& Thread.currentThread() != dispatcher)
try
buffer.wait();
discard = false;
catch (InterruptedException e)
//
// reset interrupt status so
// calling code can see interrupt on
// their next wait or sleep.
Thread.currentThread().interrupt();
if (discard)
String loggerName = event.getLoggerName();
DiscardSummary summary = (DiscardSummary) discardMap.get(loggerName);
if (summary == null)
summary = new DiscardSummary(event);
discardMap.put(loggerName, summary);
else
summary.add(event);
break;
整体流程如下:
完整流程整体比同步机制会复杂一些,如果使用异步最好仔细了解实现机制后再进行使用,否则容易因日志造成了bug,然后无法排查
3.3 同步和异步对比和注意事项
同步来说感觉网上很多人的说法都是存在误区的,经常会说"采用异步方式并不一定能提高性能(主要是如何配置好缓存大小)而线程间的同步开销则是非常大的!因此在使用本地文件记录日志时不建议使用异步方式",其实从实现逻辑上来说是不正确的,从理论上来说同步只是比异步的可用性更高一些,只能保证数据落到磁盘。加上buffer能让同步更快一些,就根据源码来看,写日志这个过程是加锁的,其实都是同步的,并不存在网上说得同步开销非常大,无论同步异步这个过程都是必须的。
从上面异步的实现过程来说,肯定是比同步更快的,而且异步方式还能使用混合模式来使用,其实正常也是必须通过混合模式来使用,因为需要使用到同步方式里面的日志格式化。完美的使用方式肯定是异步基础上使用同步来落磁盘,就这个来说其实log4j1和logback性能差异上,并不会太大
4 log4j1、logback、log4j2性能对比
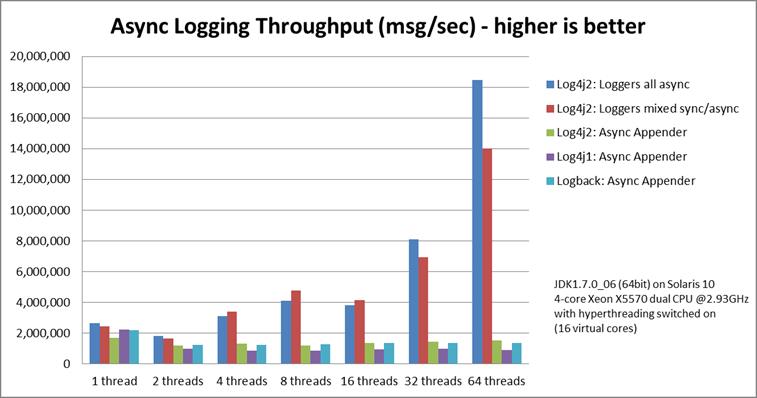
就从logback的实现方式,来说其实跟log4j1并不大,因为logback比较新,所以运用了一些java的并发库,包括使用了ArrayBlockingQueue,而log4j只是使用了ArrayList,然后用synchronized,其他地方可能做了一些相对的优化而已。
但是从根本架构上面是一样的,包括线程模型,一旦架构不变带来的性能变化就不会有太大的差别,但是从图里面可以看到,log4j2在线程数变多的情况下,性能有了质的飞跃,线程模型采用了(LMAX Disruptor)[https://github.com/LMAX-Exchange/disruptor],采用这种无锁模型来避免了线程间同步的开销,理论上来说这种框架就是为多线程产生的,不过没有仔细研究过,具体性能待考证
5 总结
关于日志来说其实从业务上来说,最好是不要影响到业务的性能,所以在使用过程中最好谨慎一些,不要从网上随便粘贴一些配置上来就使用,很可能有些情况感觉起来是优化处理,实际上却变成了拖慢系统的根本原因。
总结了下大概有下面几个点需要考虑:
- 是否采用同步或者异步,同步使用场景理论上来说应该是对日志强度依赖,不允许丢失的情况。
- 如果使用同步,则需要考虑buffer的大小,其实正常8k已经足够
- 如果采用异步,则需要考虑,异步写队列的情况,异步写队列的时候会存在两种情况,一种是写满了是否等待或者丢失。
以上是关于log4j是如何拖慢你的系统的的主要内容,如果未能解决你的问题,请参考以下文章