Core ML简介及实时目标检测及Caffe TensorFlow coremltools模型转换
Posted 这个名字到底好不好
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Core ML简介及实时目标检测及Caffe TensorFlow coremltools模型转换相关的知识,希望对你有一定的参考价值。
Core ML简介及实时目标检测,Caffe、Tensorflow与Core ML模型转换、Vision库的使用
转载请注明出处 http://blog.csdn.net/u014205968/article/details/79220659
本篇文章首先会简要介绍ios 11推出的Core ML机器学习框架,接着会以实际的已经训练好的Caffe、Tensorflow模型为例,讲解coremltools转换工具的使用,以及如何在iOS端运行相关模型。
当今是人工智能元年,随着深度学习的火热,人工智能又一次出现在大众视野中,对于客户端开发人员来说,我们也应当踏入这个领域有所了解,将机器学习与传统App结合,开发出更“懂”用户的应用。Google的Tensorflow早已支持在android上运行,苹果在iOS8推出的Metal可以用于访问GPU,使用Metal就可以实现机器学习的本地化运行,但学习成本太高,在iOS11中推出的Core ML使得机器学习本地化运行变得更加方便。
可以预见的是,本地化模型必然是发展趋势,对于实时性较高的应用,如:目标检测、自然场景文本识别与定位、实时翻译等,如果通过网络传输到后台分析,网络延迟就足够让用户放弃这个App了,比如微信的扫一扫中有翻译的功能,需要通过后台分析结果,所以识别的速度很慢,实用性不强,有道词典完全实现了离线识别和翻译的功能。本地化模型也是对用户隐私的很好保护。
作者水平有限,对于传统机器学习方法了解不多,对于深度学习只在图像识别、目标检测、自然场景文本定位与识别相关领域有所涉猎,所以本文的侧重点在于本地化运行深度学习模型,局限于实时图片识别,本文栗子包括:VGG16、Resnet、AlexNet,以及一些在Caffe Model Zoo上公开的好玩的模型。对于语音语义相关领域没有研究,因此,本文的栗子均为图像检测、目标识别相关。
本文也不会讲解深度学习的相关内容,作者还没有能力将相关内容讲的很透彻,想要深入到各个模型网络中,直接看论文是最好的选择。
Core ML简介
参考官方文档 CoreML简介
通过Core ML我们可以将已经训练好的机器学习模型集成到App中。

一个训练好的模型是指,将机器学习算法应用到一组训练数据集中得出的结果。该模型根据新的输入数据进行结果的预测,举个例子,根据某地区历史房价进行训练的模型,当给定卧室和卫生间的数量就可以预测房子的价格。
Core ML是特定领域框架和功能的基础。Core ML支持使用Vision进行图片分析,Foundation提供了自然语言处理(比如,使用NSLinguisticTagger类),GameplayKit提供了评估学习的决策树,Core ML本身是建立在上层的低级原语(primitives),基于如:Accelerate、BNNS以及Metal和Performance Shaders等。

Core ML对设备性能进行了优化,优化了内存和功耗。运行在本地设备上既保护了用户的隐私,又可以在没有网络连接时保证应用的功能完整并能够对请求做出响应。
机器学习模型在计算时,计算量往往都很大,单纯依靠CPU计算很难满足计算需求,通过上图不难发现,整个架构中Accelerate、BNNS、Metal和Performance Shaders位于最底层,Core ML直接使用DSP、GPU等硬件加速计算和渲染,上层用户不再需要直接操作硬件调用相关C函数,这也是Core ML进行优化的一部分。在Core ML之上,提供了Vision库用于图像分析,Foundation库提供了自然语言处理的功能,GameplayKit应该是在游戏中使用的,这些库封装了苹果提供的机器学习模型,提供上层接口供开发者使用。
Vision库是一个高性能的图像和视频分析库,提供了包括人脸识别、特征检测、场景分类等功能。本文也会举相关栗子。对于自然语言处理和GameplayKit作者没有涉猎,不做举例。
总而言之,Core ML提供了高性能的本地化运行机器模型的功能,能够很方便的实现机器学习模型本地化运行,并提供了一些封装好的模型接口供上层使用。其中最重要的当然就是机器学习模型,Core ML只支持mlmodel格式的模型,但苹果提供了一个转换工具可以将Caffe、Keras等框架训练的机器学习模型转换为mlmodel格式供应用使用,还有一些第三方的工具可以将Tensorflow、MXNet转换为mlmodel格式的模型,苹果官方也提供了一些mlmodel格式的深度学习模型,如VGG16、GooLeNet等用于ImageNet物体识别功能的模型,具体可在官网Apple Machine Learning下载。
Core ML实战 - 实时捕获与识别
首先,使用官网提供的模型尝试一下,在上面的网站中,可以下载到物体识别相关的模型有MobileNet、SqueezeNet、ResNet50、Inception V3、VGG16,本文以VGG16为例进行讲解,你也可以下载一个比较小的模型做简单的实验。
将下载的模型mlmodel文件拖入到XCode工程中,单击该文件可以看到相关描述,如下图所示:
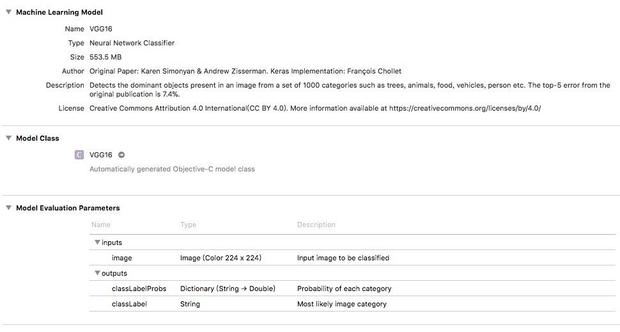
在这个描述中,Machine Learning Model下可以看到模型的相关描述信息。模型文件拖入工程以后也会生成模型相关的接口文件,单击Model Class下的VGG16即可跳转到VGG16模型的接口文件中。Model Evaluation Parameters则提供了模型的输入输出信息,如上图,输入为224*224大小的三通道图片,输出有两个,classLabelProbs输出每一个分类的置信度字典,该VGG16可以对1000个类别进行识别,因此字典会有1000个key-value键值对,classLabel则输出置信度最高的分类的标签。
单击VGG16去查看相关接口声明如下:
//VGG16模型的输入类
@interface VGG16Input : NSObject<MLFeatureProvider>
/*
创建输入类,需要传入一个CVPixelBufferRef类型的图像数据
类型需要为kCVPixelFormatType_32BGRA,大小为224*224像素
*/
@property (readwrite, nonatomic) CVPixelBufferRef image;
- (instancetype)init NS_UNAVAILABLE;
//直接使用该构造函数创建对象即可
- (instancetype)initWithImage:(CVPixelBufferRef)image;
@end
//VGG16模型的输出类
@interface VGG16Output : NSObject<MLFeatureProvider>
//前文讲述的1000分类的名称和置信度字典
@property (readwrite, nonatomic) NSDictionary<NSString *, NSNumber *> * classLabelProbs;
//前文讲述的置信度最高的类别名称
@property (readwrite, nonatomic) NSString * classLabel;
//一般不手动创建输出对象,通过模型对象识别时返回结果为输出对象
- (instancetype)init NS_UNAVAILABLE;
//在进行预测是,Core ML会调用该方法创建一个output对象返回给调用者
- (instancetype)initWithClassLabelProbs:(NSDictionary<NSString *, NSNumber *> *)classLabelProbs classLabel:(NSString *)classLabel;
@end
//VGG16模型接口
@interface VGG16 : NSObject
//MLModel即为Core ML抽象的模型对象
@property (readonly, nonatomic, nullable) MLModel * model;
//构造函数,可以直接使用默认构造函数,则默认加载工程文件中名称为VGG16的mlmodel模型文件
//也可以提供远程下载的功能,使用该构造函数来加载模型
- (nullable instancetype)initWithContentsOfURL:(NSURL *)url error:(NSError * _Nullable * _Nullable)error;
/*
进行预测的方法,需要传入VGG16Input对象和一个NSError指针的指针
返回结果为VGG16Ouput对象,从返回的对象中即可获取到识别的结果
*/
- (nullable VGG16Output *)predictionFromFeatures:(VGG16Input *)input error:(NSError * _Nullable * _Nullable)error;
//直接通过CVPixelBufferRef进行预测,省去了创建input对象的步骤
- (nullable VGG16Output *)predictionFromImage:(CVPixelBufferRef)image error:(NSError * _Nullable * _Nullable)error;
@end这个接口文件中只声明了三个类,VGG16Input表示模型的输入对象、VGG16Output表示模型的输出对象、VGG16表示模型对象,其实对于任何mlmodel格式的深度学习模型,最终生成的接口文件都是相同的,差别就在于输入输出的不同,所以,掌握了一个模型的使用方法,其他模型都是通用的。
接下来看一下具体的使用代码:
//模型拖入工程后,使用默认构造函数进行模型加载,就会去加载同名的VGG16.mlmodel文件
VGG16 *vgg16Model = [[VGG16 alloc] init];
//加载一个需要识别图片,一定是224*224大小的,否则不能识别
UIImage *image = [UIImage imageNamed:@"test.png"];
//将图片转换为CVPixelBufferRef格式的数据
CVPixelBufferRef imageBuffer = [self pixelBufferFromCGImage:[image CGImage]];
//使用转换后的图片数据构造模型输入对象
VGG16Input *input = [[VGG16Input alloc] initWithImage:imageBuffer];
NSError *error;
//使用VGG16模型进行图片的识别工作
VGG16Output *output = [vgg16Model predictionFromFeatures:input error:&error];
//根据error判断识别是否成功
if (error)
NSLog(@"Prediction Error %@", error);
else
//识别成功,输出可能性最大的分类标签
NSLog(@"Label: %@", output.classLabel);
//由于在转换UIImage到CVPixelBufferRef时,手动开辟了一个空间,因此使用完成后需要及时释放
CVPixelBufferRelease(imageBuffer);
//CGImageRef转换CVPiexlBufferRef格式数据
- (CVPixelBufferRef) pixelBufferFromCGImage: (CGImageRef) image
NSDictionary *options = @
(NSString*)kCVPixelBufferCGImageCompatibilityKey : @YES,
(NSString*)kCVPixelBufferCGBitmapContextCompatibilityKey : @YES,
;
CVPixelBufferRef pxbuffer = NULL;
/*
注意需要使用kCVPixelFormatType_32BGRA的格式
深度学习常用OpenCV对图片进行处理,OpenCV使用的不是RGBA而是BGRA
这里使用CVPixelBufferCreate手动开辟了一个空间,因此使用完成后一定要释放该空间
*/
CVReturn status = CVPixelBufferCreate(kCFAllocatorDefault, CGImageGetWidth(image),
CGImageGetHeight(image), kCVPixelFormatType_32BGRA, (__bridge CFDictionaryRef) options,
&pxbuffer);
if (status != kCVReturnSuccess)
NSLog(@"Operation failed");
NSParameterAssert(status == kCVReturnSuccess && pxbuffer != NULL);
CVPixelBufferLockBaseAddress(pxbuffer, 0);
void *pxdata = CVPixelBufferGetBaseAddress(pxbuffer);
CGColorSpaceRef rgbColorSpace = CGColorSpaceCreateDeviceRGB();
CGContextRef context = CGBitmapContextCreate(pxdata, CGImageGetWidth(image),
CGImageGetHeight(image), 8, 4*CGImageGetWidth(image), rgbColorSpace,
kCGImageAlphaNoneSkipFirst);
NSParameterAssert(context);
CGContextConcatCTM(context, CGAffineTransformMakeRotation(0));
CGAffineTransform flipVertical = CGAffineTransformMake( 1, 0, 0, -1, 0, CGImageGetHeight(image) );
CGContextConcatCTM(context, flipVertical);
CGAffineTransform flipHorizontal = CGAffineTransformMake( -1.0, 0.0, 0.0, 1.0, CGImageGetWidth(image), 0.0 );
CGContextConcatCTM(context, flipHorizontal);
CGContextDrawImage(context, CGRectMake(0, 0, CGImageGetWidth(image),
CGImageGetHeight(image)), image);
CGColorSpaceRelease(rgbColorSpace);
CGContextRelease(context);
CVPixelBufferUnlockBaseAddress(pxbuffer, 0);
return pxbuffer;
编译运行以后就可以看到输出结果啦,对于目标识别这样的简单问题来说,输入为一张图片,输出为一个分类结果,所有的模型几乎都是这样的处理步骤。首先获取要识别的图片,创建模型对象,创建模型输入对象,通过模型对象进行识别来获取模型输出对象,从输出对象获取结果。
对于官网提供的其他目标识别,Resnet50、GoogLeNet等,不再举例了,过程都是一样的,读者可自行实验。
接下来做一点有趣的尝试,通过手机摄像头实时获取拍摄的数据,然后去实时检测目标并给出分类结果。
首先需要做一定的限制,输入图片要求是224*224大小的,通过摄像头获取的图像数据是1080*1920的,如果直接转换为224*224会有拉伸,影响识别结果,所以,作者采用的方法是获取中间区域部分的正方形图像,然后转换为目标大小。
代码如下:
//定义一个深度学习模型执行的block,方便在一个应用内,调用不同的模型
typedef void(^machineLearningExecuteBlock)(CVPixelBufferRef imageBuffer);
//实时目标检测视图类,需要实现一个协议用于获取摄像头的输出数据
@interface RealTimeDetectionViewController() <AVCaptureVideoDataOutputSampleBufferDelegate>
//当前获取到的设备
@property (nonatomic, strong) AVCaptureDevice *device;
/*
设备的输入,表示摄像头或麦克风这样的实际物理硬件
通过AVCaptureDevice对象创建,可以控制实际的物理硬件设备
*/
@property (nonatomic, strong) AVCaptureDeviceInput *input;
//视频输出,还有音频输出等类型
@property (nonatomic, strong) AVCaptureVideoDataOutput *output;
//设备连接,用于将session会话获取的数据与output输出数据,可以同时捕获视频和音频数据
@property (nonatomic, strong) AVCaptureConnection *videoConnection;
/*
捕捉设备会话,从实际的硬件设备中获取数据流,可以从摄像头或麦克风中获取
将数据流输出到一个或数个目的地,对于图像可以预设捕捉图片的大小质量等
*/
@property (nonatomic, strong) AVCaptureSession *session;
//设备预览layer,对于图像来说,摄像头拍摄到的图像数据直接展示在该layer上
@property (nonatomic, strong) AVCaptureVideoPreviewLayer *preview;
//感兴趣的区域,即将摄像头上该区域的图像捕获去进行识别
@property (nonatomic, assign) CGRect interestRegionRect;
//目标图像的大小,针对不同模型,有不同的输入图像大小
@property (nonatomic, assign) CGSize targetSize;
//一个框,类似于扫描二维码的,提示在这个框内的图像会被用于实时检测
@property (nonatomic, strong) UIImageView *interestRegionImageView;
//session传递数据是阻塞的,使用单独的串行队列处理
@property (nonatomic) dispatch_queue_t videoCaptureQueue;
//显示识别结果的label
@property (nonatomic, strong) UILabel *titleLabel;
//退出button
@property (nonatomic, strong) UIButton *exitButton;
//切换前后摄像头button
@property (nonatomic, strong) UIButton *reverseCameraButton;
//机器学习模型识别block
@property (nonatomic, copy) machineLearningExecuteBlock executeBlock;
@end上面的代码使用AVFoundation框架来实现视频数据的捕获,注释很详细,不再赘述了。
/**
初始化设备、界面函数
@param interestRegion 感兴趣区域,如果为CGRectZero不创建提示imageView
@param targetSize 目标图像大小,如果为CGSizeZero不转换图像大小
@param executeBlock 机器学习模型执行block
*/
- (void)setUpWithInterestRegion:(CGRect)interestRegion targetSize:(CGSize)targetSize machineLearningExecuteBlock:(machineLearningExecuteBlock)executeBlock
self.view.backgroundColor = [UIColor whiteColor];
//创建一个串行队列,用于处理session获取到的数据,即执行回调函数
self.videoCaptureQueue = dispatch_queue_create("VideoCaptureQueue", DISPATCH_QUEUE_SERIAL);
//获取一个默认摄像头设备,默认使用后置摄像头
//self.device = [AVCaptureDevice defaultDeviceWithDeviceType:AVCaptureDeviceTypeBuiltInWideAngleCamera mediaType:AVMediaTypeVideo position:AVCaptureDevicePositionFront];
//指定获取前置或后置摄像头
self.device = [self cameraWithPosition:AVCaptureDevicePositionFront];
//设置摄像头自动对焦
if (self.device.isFocusPointOfInterestSupported && [self.device isFocusModeSupported:AVCaptureFocusModeContinuousAutoFocus])
[self.device lockForConfiguration:nil];
[self.device setFocusMode:AVCaptureFocusModeContinuousAutoFocus];
[self.device unlockForConfiguration];
//创建一个捕获输入
self.input = [AVCaptureDeviceInput deviceInputWithDevice:self.device error:nil];
//创建捕获输出
self.output = [[AVCaptureVideoDataOutput alloc] init];
//设置输出数据的代理为self,代理函数执行队列为创建的串行队列
[self.output setSampleBufferDelegate:self queue:self.videoCaptureQueue];
//创建一个字典,用于限制输出数据类型,输出数据的格式为kCVPixelFormatType_32BGRA
NSDictionary *outputSettings = @(id)kCVPixelBufferPixelFormatTypeKey: [NSNumber numberWithInt:kCVPixelFormatType_32BGRA];
//限制输出数据类型
[self.output setVideoSettings:outputSettings];
//创建一个session会话
self.session = [[AVCaptureSession alloc] init];
//设置输出数据为高质量,输出图像大小为1080*1920
[self.session setSessionPreset:AVCaptureSessionPresetHigh];
//将input、output添加进session会话进行管理
if ([self.session canAddInput:self.input])
[self.session addInput:self.input];
if ([self.session canAddOutput:self.output])
[self.session addOutput:self.output];
//创建一个connection
self.videoConnection = [self.output connectionWithMediaType:AVMediaTypeVideo];
self.videoConnection.enabled = NO;
//设置拍摄图像是竖屏,1080*1920,否则默认会旋转
[self.videoConnection setVideoOrientation:AVCaptureVideoOrientationPortrait];
//创建一个预览layer
self.preview = [AVCaptureVideoPreviewLayer layerWithSession:self.session];
self.preview.videoGravity = AVLayerVideoGravityResize;
//设置这个预览layer为全屏
self.preview.frame = self.view.frame;
self.preview.contentsScale = [[UIScreen mainScreen] scale];
//将预览layer插入到view.layer的第一个,作为子layer
[self.view.layer insertSublayer:self.preview atIndex:0];
//判断是否有感兴趣的区域,如果有就创建一个imageView防一个框在该区域中,用于提示用户
if (!CGRectEqualToRect(interestRegion, CGRectZero))
self.interestRegionImageView = [[UIImageView alloc] initWithFrame:interestRegion];
self.interestRegionImageView.image = [UIImage imageNamed:@"InterestRegionBG"];
[self.view addSubview:self.interestRegionImageView];
self.interestRegionRect = interestRegion;
//创建显示结果的label
self.titleLabel = [[UILabel alloc] initWithFrame:CGRectMake(0, self.view.frame.size.height - 50, self.view.frame.size.width, 50)];
self.titleLabel.textAlignment = NSTextAlignmentCenter;
self.titleLabel.textColor = [UIColor redColor];
[self.view addSubview:self.titleLabel];
//创建退出button
self.exitButton = [UIButton buttonWithType:UIButtonTypeCustom];
self.exitButton.titleLabel.textColor = [UIColor redColor];
[self.exitButton setTitle:@"Exit" forState:UIControlStateNormal];
self.exitButton.frame = CGRectMake(20, 20, 80, 40);
[self.exitButton addTarget:self action:@selector(exitButtonClickedHandler) forControlEvents:UIControlEventTouchUpInside];
[self.view addSubview:self.exitButton];
//创建摄像头翻转butotn
self.reverseCameraButton = [UIButton buttonWithType:UIButtonTypeCustom];
self.reverseCameraButton.titleLabel.textColor = [UIColor redColor];
[self.reverseCameraButton setTitle:@"ReverseCamera" forState:UIControlStateNormal];
self.reverseCameraButton.frame = CGRectMake(self.view.frame.size.width - 20 - 200, 20, 200, 40);
[self.reverseCameraButton addTarget:self action:@selector(reverseCameraButtonClickedHandler) forControlEvents:UIControlEventTouchUpInside];
[self.view addSubview:self.reverseCameraButton];
//记录targetsize和block
self.targetSize = targetSize;
self.executeBlock = executeBlock;
//启动session,打开摄像头,开始收数据了
[self.session startRunning];
self.videoConnection.enabled = YES;
/**
初始化函数
@return return value description
*/
- (instancetype)initWithVGG16
if (self = [super init])
//加载本地的VGG16模型
VGG16 *vgg16Model = [[VGG16 alloc] init];
//获取一个weakSelf,在block中使用,防止引用循环
__weak typeof(self) weakSelf = self;
/*
调用setUpWithInterestRegion:targetSize:machineLearningExecuteBlock函数进行初始化操作
感兴趣区域放在屏幕正中央,大小为224*224,目标大小也为224*224
*/
[self setUpWithInterestRegion:CGRectMake((self.view.frame.size.width - 224) / 2.0, (self.view.frame.size.height - 224) / 2.0, 224, 224) targetSize:CGSizeMake(224, 224) machineLearningExecuteBlock:^(CVPixelBufferRef imageBuffer)
//使用block的参数构造VGG16的输入对象
VGG16Input *input = [[VGG16Input alloc] initWithImage:imageBuffer];
NSError *error;
//使用VGG16模型识别imageBuffer获取输出数据
VGG16Output *output = [vgg16Model predictionFromFeatures:input error:&error];
//获取一个strong的self
__strong typeof(weakSelf) strongSelf = weakSelf;
//如果识别失败,在主队列即主线程中修改titleLbale
if (error)
dispatch_async(dispatch_get_main_queue(), ^
strongSelf.titleLabel.text = @"Error!!!";
);
else
//识别成功,在主队列即主线程中修改titleLabel
dispatch_async(dispatch_get_main_queue(), ^
strongSelf.titleLabel.text = output.classLabel;
);
];
return self;
上面的两个函数就是具体的初始化设备和执行机器学习模型识别的代码,可以看出识别的代码还是和上个栗子一样简洁明了。
接下来看一下AVFoundation的代理函数,如何将视频数据经过一系列转换交给executeBlock做识别。
/**
AVCaptureVideoDataOutputSampleBufferDelegate代理方法,摄像头获取到数据后就会回调该方法
默认是30FPS,每秒获取30张图像
@param output output description
@param sampleBuffer 摄像头获取到的图像数据格式
@param connection connection description
*/
- (void)captureOutput:(AVCaptureOutput *)output didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection
//需要将CMSampleBufferRef转换为CVPixelBufferRef才能交给机器学习模型识别
CVPixelBufferRef buffer;
//首先判断是否需要将图像转换为目标大小
if (!CGSizeEqualToSize(self.targetSize, CGSizeZero))
//将CMSampleBufferRef转换为UIImage类型的对象
UIImage *image = [self convertImage:sampleBuffer];
//截图,获取感兴趣区域的图像,然后转换为目标大小
image = [self getSubImage:self.interestRegionRect image:image targetSize:self.targetSize];
//将CGImageRef图像转换为CVPixelBufferRef,使用CVPixelBufferCreate手动开辟的空间,使用完成后需要释放
buffer = [self pixelBufferFromCGImage:[image CGImage]];
else
//不需要转化,则直接将CMSampleBufferRef转换为CVPixelBufferRef类型
//这个函数虽然是叫get ImageBuffer,其实CVPixelBufferRef是CVImageBufferRef的别称
//不是手动开辟的空间,随着弹栈自动释放内存
buffer = CMSampleBufferGetImageBuffer(sampleBuffer);
//如果executeBlock不为空,传递CVPixelBufferRef数据,执行识别
if (self.executeBlock)
self.executeBlock(buffer);
//自己创建的buffer自己清理,不是自己创建的交由系统清理
if (!CGSizeEqualToSize(self.targetSize, CGSizeZero))
CVPixelBufferRelease(buffer);
/**
截图函数
@param rect 感兴趣区域
@param image 要截的图
@param targetSize 目标大小
@return 截过的图片
*/
- (UIImage*)getSubImage:(CGRect)rect image:(UIImage*)image targetSize:(CGSize)targetSize
CGFloat screenWidth = [[UIScreen mainScreen] bounds].size.width;
CGFloat screenHeight = [[UIScreen mainScreen] bounds].size.height;
//因为输出图像是1080*1920,屏幕大小比这个小,所以需要根据比例将感兴趣区域换算到1080*1920大小的图像上
CGRect imageRegion = CGRectMake((rect.origin.x / screenWidth) * image.size.width, (rect.origin.y / screenHeight) * image.size.height, (rect.size.width / screenWidth) * image.size.width, (rect.size.height / screenHeight) * image.size.height);
//使用C函数直接截取感兴趣区域的图像
CGImageRef imageRef = image.CGImage;
CGImageRef imagePartRef = CGImageCreateWithImageInRect(imageRef, imageRegion);
//获取到截取的UIImage对象
UIImage *cropImage = [UIImage imageWithCGImage:imagePartRef];
//释放创建的CGImageRef数据
CGImageRelease(imagePartRef);
//开启一个绘制图像的上下文,设置大小为目标大小
UIGraphicsBeginImageContext(targetSize);
//将前面裁剪的感兴趣的图像绘制在目标大小上
[cropImage drawInRect:CGRectMake(0, 0, targetSize.width, targetSize.height)];
//获取绘制完成的UIImage对象
UIImage *resImage = UIGraphicsGetImageFromCurrentImageContext();
//释放内存
UIGraphicsEndImageContext();
return resImage;
/**
官方给的转换代码
@param sampleBuffer sampleBuffer description
@return return value description
*/
- (UIImage*)convertImage:(CMSampleBufferRef)sampleBuffer
// Get a CMSampleBuffer's Core Video image buffer for the media data
CVImageBufferRef imageBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
// Lock the base address of the pixel buffer
CVPixelBufferLockBaseAddress(imageBuffer, 0);
// Get the number of bytes per row for the pixel buffer
void *baseAddress = CVPixelBufferGetBaseAddress(imageBuffer);
// Get the number of bytes per row for the pixel buffer
size_t bytesPerRow = CVPixelBufferGetBytesPerRow(imageBuffer);
// Get the pixel buffer width and height
size_t width = CVPixelBufferGetWidth(imageBuffer);
size_t height = CVPixelBufferGetHeight(imageBuffer);
// Create a device-dependent RGB color space
CGColorSpaceRef colorSpace = CGColorSpaceCreateDeviceRGB();
// Create a bitmap graphics context with the sample buffer data
CGContextRef context = CGBitmapContextCreate(baseAddress, width, height, 8,
bytesPerRow, colorSpace, kCGBitmapByteOrder32Little | kCGImageAlphaPremultipliedFirst);
// Create a Quartz image from the pixel data in the bitmap graphics context
CGImageRef quartzImage = CGBitmapContextCreateImage(context);
// Unlock the pixel buffer
CVPixelBufferUnlockBaseAddress(imageBuffer,0);
// Free up the context and color space
CGContextRelease(context);
CGColorSpaceRelease(colorSpace);
// Create an image object from the Quartz image
//UIImage *image = [UIImage imageWithCGImage:quartzImage];
UIImage *image = [UIImage imageWithCGImage:quartzImage scale:1.0f orientation:UIImageOrientationUp];
// Release the Quartz image
CGImageRelease(quartzImage);
return image;
上面的代码就实现了实时的检测,代理函数会以30帧的速率执行,但有时数据来了,前一个识别还没结束,这一帧就会被抛弃,所以实时的检测对深度学习模型和设备性能的要求很高。代码很简单,整个流程就是从获取到的图像根据比例截取感兴趣区域后再转换为目标大小,然后交由深度学习模型去识别后显示结果,注释很详细,不再讲解了。
下面是一些翻转摄像头、对焦之类的辅助函数
#pragma mark touchsbegin
- (void)touchesBegan:(NSSet<UITouch *> *)touches withEvent:(UIEvent *)event
for (UITouch *touch in touches)
CGPoint point = [touch locationInView:self.view];
//触摸屏幕,实现对焦
[self focusOnPoint:point];
#pragma mark avfoundation function
/**
根据deviceDiscoverySession类型,获取前置或后置摄像头
@param position position description
@return return value description
*/
- (AVCaptureDevice*)cameraWithPosition:(AVCaptureDevicePosition)position
//iOS10以后使用该类方法获取想要的设备
AVCaptureDeviceDiscoverySession *deviceDiscoverySession = [AVCaptureDeviceDiscoverySession discoverySessionWithDeviceTypes:@[AVCaptureDeviceTypeBuiltInWideAngleCamera] mediaType:AVMediaTypeVideo position:position];
//遍历获取到的所有设备,返回需要的类型
for (AVCaptureDevice* device in deviceDiscoverySession.devices)
if(device.position == position)
return device;
return nil;
/**
手动对焦
@param point 需要对焦的区域点
*/
- (void)focusOnPoint:(CGPoint)point
if ([self.device isFocusPointOfInterestSupported] && [self.device lockForConfiguration:nil])
self.device.focusPointOfInterest = point;
[self.device unlockForConfiguration];
#pragma mark - UIButton target-action handler
- (void)exitButtonClickedHandler
[self dismissViewControllerAnimated:YES completion:nil];
/**
前后摄像头翻转
*/
- (void)reverseCameraButtonClickedHandler
//创建一个新的设备
AVCaptureDevice *newCamera;
//根据当前设备类型,获取翻转后的摄像头设备
if (self.device.position == AVCaptureDevicePositionBack)
newCamera = [self cameraWithPosition:AVCaptureDevicePositionFront];
else
newCamera = [self cameraWithPosition:AVCaptureDevicePositionBack];
//根据设备创建一个新的input
AVCaptureDeviceInput *newInput = [AVCaptureDeviceInput deviceInputWithDevice:newCamera error:nil];
self.device = newCamera;
//会话开启一个配置阶段
[self.session beginConfiguration];
//删除旧设备input
[self.session removeInput:self.input];
//添加新设备input
[self.session addInput:newInput];
self.input = newInput;
//关闭connection,重新创建一个,否则切换摄像头时输出的图片又默认旋转了
self.videoConnection.enabled = NO;
self.videoConnection = [self.output connectionWithMediaType:AVMediaTypeVideo];
self.videoConnection.enabled = NO;
[self.videoConnection setVideoOrientation:AVCaptureVideoOrientationPortrait];
self.videoConnection.enabled = YES;
//提交配置,自动更新
[self.session commitConfiguration];
所有的事实检测代码就完成了,读者可以编写多个initWithVGG16这样的构造函数,通用整个代码进行模型切换。下面是在我的设备上运行的结果:

coremltools转换自己的模型
前文讲解了一个详细的实时检测的栗子,但深度学习模型的调用其实还是很简单的,官方的模型玩完以后,我们就可以尝试将训练好的模型转换为mlmodel格式,苹果官方推出的python包coremltools就是完成这个事情的,不过这个包只支持caffe和keras,一些第三方的可以支持Tensorflow,不过它支持的操作比较少,有些模型没办法转换,还需要等开发者们继续完善。
安装coremltools
pip install coremltools
安装完成后,就可以去下载你想要的模型了,你可以在Caffe Model Zoo上下载的训练好的模型,作者之前看到过一个CVPR2015的年龄和性别预测的论文,这里就以这个模型为例讲解一下转换过程。
论文下载地址: CNN_AgeGenderEstimation
模型下载地址: CNN_AgeGender Caffe Model
下载完成后得到了.caffemodel的权值文件、.prototxt的网络结构配置文件,如果这是一个多分类的模型,最好给出模型最终输出的标签,以txt的格式,一行一个标签,这样,在转换完成后的mlmodel文件就直接输出最终的易于读的结果,而不是最后一层输出的数据。
>>> import coremltools
>>> model = coremltools.converters.caffe.convert(('age_net.caffemodel', 'deploy_age.prototxt'), image_input_names='data', class_labels='age_labels.txt')
>>> model.save('AgePredictionNet.mlmodel')运行上述代码后,就可以产生转换后的mlmodel文件了,转换代码也很简单,只需要一个tuple类型的数据,传入.caffemodel文件,.prototxt网络结构配置文件,后面都是可选参数了,其中class_labels的age_labels.txt是作者自己写的,在论文中可以看到这个年龄预测的网络最终输出结果是八个类别中的一个,如果不自己写标签文件,输出结果就是0-7的数字,文件内容如下:
0-2
4-6
8-13
15-20
25-32
38-43
48-53
60每一个标签占一行,转换时会将该内容集成进mlmodel中,最后在输出时,直接可以获得易于读的标签数据。
将转换后的模型拖入Xcode中,可以查看到如下信息:
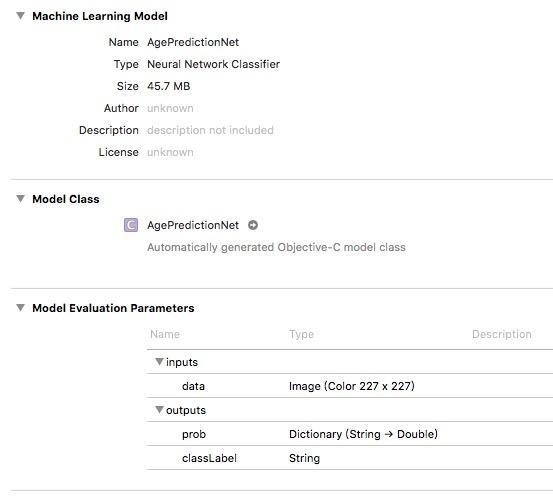
开发者关心的是网络接口定义,输入与输出信息,输入为227*227的图像数据,输出结果有两个,一个是八个类别各自置信度的字典,还有一个是置信度最高的类别名称,即前面的class_labels填写的内容。由于篇幅问题,该网络具体的使用就不赘述了,和前面的VGG16是一样的。读者可以自行实验一下性别分类网络的转换,这个网络的输出是二分类问题,所以可以不需要class_labels自己解析输出结果就好了,当然也可以写一个文件标识。
看一下该方法的定义:
def convert(model, image_input_names=[], is_bgr=False,
red_bias=0.0, blue_bias=0.0, green_bias=0.0, gray_bias=0.0,
image_scale=1.0, class_labels=None, predicted_feature_name=None):model就是一个tuple,包括.caffemodel、.prototxt、.binaryproto均值文件,其中前两个是必须的。
image_input_names可选参数,表示网络输入层的名称,可以在.prototxt文件中查看到。
is_bgr之前在前面的栗子说过caffe的图像是BGRA格式的。
red_bias blue_bias green_bias image_scale顾名思义啦,各种偏置和缩放比例。
class_labels就是前面举例的易于读和获取最终结果的文件。
predicted_feature_name模型输出类别名称,感觉没什么用
Tensorflow模型的转换
Tensorflow用的越来越多了,所以也需要了解一下转换方法,coremltools暂时还不支持Tensorflow的转换,但苹果官方推荐使用tfcoreml进行转换,说实话,用起来没有转caffe的那么方便。
安装tfcoreml
pip install tfcoreml
具体使用可参考github上的栗子:tfcoreml Github
可以下载Tensorflow训练好的Inception/Resnet v2模型,下载完成后包含一个frozen.pb文件和imagenet_slim_labels.txt的ImageNet1000分类的标签文件,接着使用如下代码即可完成转换:
tf_model_dir = '/Users/chenyoake/Desktop/MLModel/inception_resnet'
tf_model_path = os.path.join(tf_model_dir, 'inception_resnet_v2_2016_08_30_frozen.pb')
mlmodel_path = os.path.join(tf_model_dir, 'InceptionResnetV2.mlmodel')
mlmodel = tf_converter.convert(
tf_model_path = tf_model_path,
mlmodel_path = mlmodel_path,
output_feature_names = ['InceptionResnetV2/Logits/Predictions:0'],
input_name_shape_dict = 'input:0':[1,299,299,3],
image_input_names = ['input:0'],
red_bias = -1,
green_bias = -1,
blue_bias = -1,
image_scale = 2.0/255.0,
class_labels = '/Users/chenyoake/Desktop/MLModel/inception_resnet/imagenet_slim_labels.txt')转换时需要传入网络的输入和输出层名称,指定输入数据的维度等信息,所以需要开发者对相关网络结构有所了解,最好能查看源码。
转换完成后的使用和VGG16的栗子一样,不再赘述了。
Vision库的使用
在文章的最开始,我们讲解了Vision库在Core ML的上层,所以本质上,Vision库是封装了一些机器学习模型,并提供了易于使用的上层接口。包括人脸识别、人脸特征检测、目标识别、目标追踪等。但经过我的实验,对于动态实时识别似乎并不是很合适,像目标追踪,只能追踪物体,我尝试追踪人脸失败了,但物体追踪效果也不是很好,人脸识别的准确率比较高。
Vision库是基于Core ML以上是关于Core ML简介及实时目标检测及Caffe TensorFlow coremltools模型转换的主要内容,如果未能解决你的问题,请参考以下文章