Metacat实现原理解析
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Metacat实现原理解析相关的知识,希望对你有一定的参考价值。
本文首发微信公众号:码上观世界
Metacat 是Netflix开源的元数据管理平台, 它的三个主要目标是:
提供元数据系统的联合视图
用于数据集元数据的统一 API
支持业务和用户元数据存储
本文从系统特性与架构、Metacat元数据存取模型以及技术实现方面来讲述Metacat的实现原理。
Metacat特性与架构
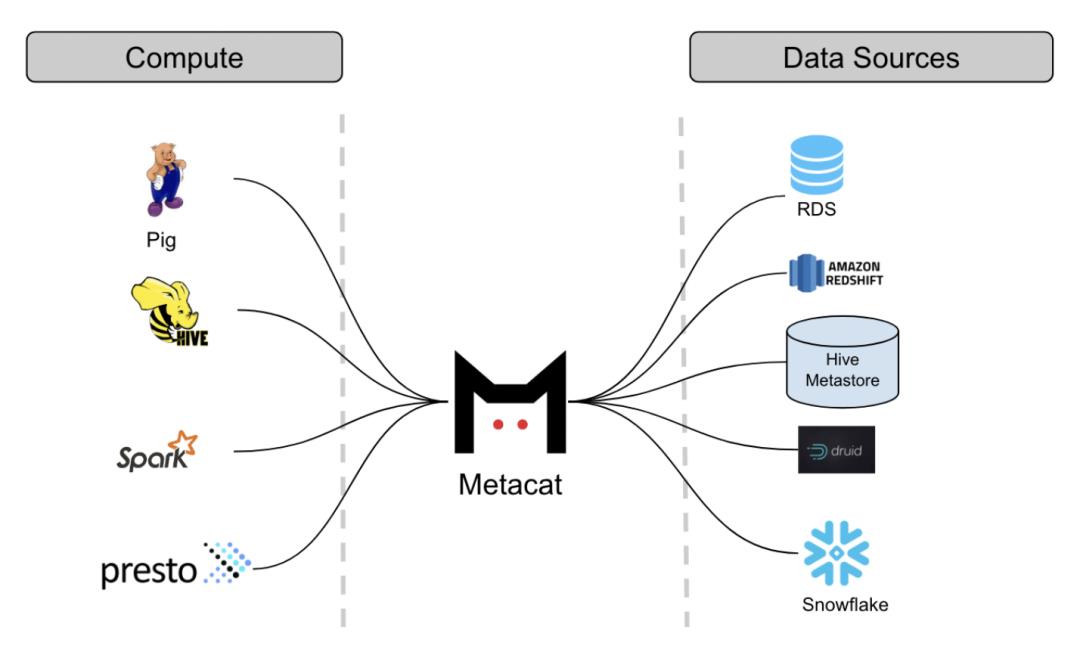
Metacat本身不存储数据源的元数据,只存储跟数据源相关的业务元数据和用户自定义元数据。从高层视角,可以将Metacat的特性归为以下几类:
数据抽象和互操作性:通过引入通用的抽象层,提供统一的访问API,不同的引擎可以交互访问这些数据集。为便于与 Spark、Flink和 Trino等 集成,提供支持 Hive 的 Thrift 接口。
存储业务和用户自定义的元数据:统一元存储只存储技术元数据,实际上,还会有部分业务元数据和用户自定义元数据,例如 RDS 数据源)、配置信息、度量指标(Hive/S3 分区和表)以及数据表的 TTL(生存时间)等。它们是一种自由格式的元数据,可由用户根据自己的用途进行定义。
业务元数据也可以大致分为逻辑元数据和物理元数据。有关逻辑结构(如表)的业务元数据被视为逻辑元数据。我们使用元数据进行数据分类和标准化我们的 ETL 处理流程。数据表的所有者可在业务元数据中提供数据表的审计信息。他们还可以为列提供默认值和验证规则,在写入数据时会用到这些。存储在表中或分区中的实际数据的元数据被视为物理元数据。我们的 ETL 处理在完成作业时会保存数据的度量标准, 在稍后用于验证。相同的度量可用来分析数据的成本和空间。因为两个表可以指向相同的位置(如 Hive), 所以要能够区分逻辑元数据与物理元数据。两个表可以具有相同的物理元数据,但应该具有不同的逻辑元数据。
数据发现:作为数据的消费者,我们应该能够轻松发现和浏览各种数据集。为提升查询效率和能力,需要将Schema元数据和业务及用户定义的元数据发布到 Elasticsearch,以便进行全文搜索。SQL 编辑器因此能够实现 SQL 语句的自动建议和自动完成功能。将数据集组织为Catalog有助于消费者浏览信息,根据不同的主题使用标签对数据进行分类。我们还使用标签来识别表格,进行数据生命周期管理。
数据变更审计和通知:作为数据存储的中央网关,统一元数据能够捕获所有元数据变更和数据更新,通过构建基于事件驱动的系统架构,将元数据变更通知发布到消息系统,不仅有助于上下游系统解耦,还有助于下游系统响应的及时性。
Schema和元数据的版本控制:用于提供数据表的历史记录。例如,跟踪特定列的元数据变更,或查看表的大小随时间变化的趋势。能够查看过去某个时刻元数据的信息对于审计、调试以及重新处理和回滚来说都非常有用。
Hive Metastore 优化:由 RDS 支持的 Hive Metastore 在高负载下表现不佳。我们已经注意到,在使用元数据存储 API 写入和读取分区方面存在很多问题。为此,我们不再使用这些 API。我们对 Hive 连接器(在读写分区时,该连接器直接与 RDS 通信)进行了改进。之前,添加数千个分区的 Hive Metastore 调用通常会超时,在重新实现后,这不再是个问题。另一个问题是,Hive Metastore Server配置项是静态的,无法支持动态添加配置,特别是在需要支持多种外部存储(如S3、HDFS等)的场景。我们通过绕过原有的Thrfit RPC接口访问方式,根据原生底层API跟Hive Metastore交互,不仅提升了访问速率,还可以实现动态传递任意原来不能传递的Configuration配置信息。
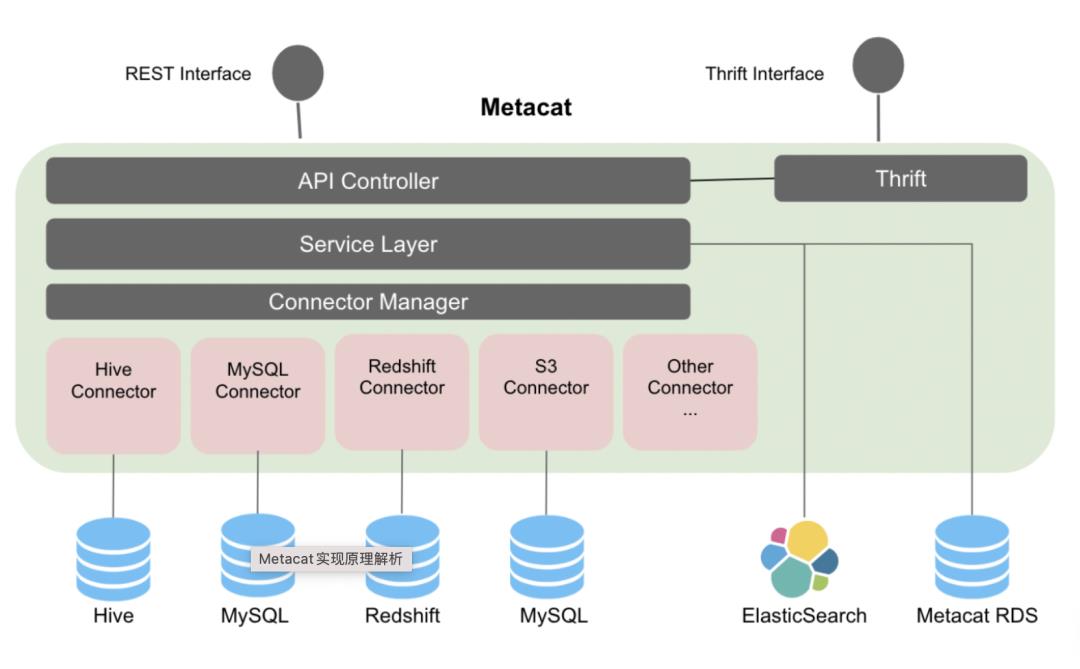
Metacat元数据存取模型
这里按照从Controller API 请求开始,到对底层数据源的元数据存取的流程来看看具体涉及到的系统组件和功能,在Controller API层Metacat
定义了一套专有的数据结构,比如CatalogDto、DatabaseDto、TableDto等。以创建数据表为例,首先创建Catalog,然后再创建Database,最后再创建表,当然数据库可以使用系统默认数据库。不管请求哪种元数据服务接口,系统都会按照下图右侧的逻辑流程处理:
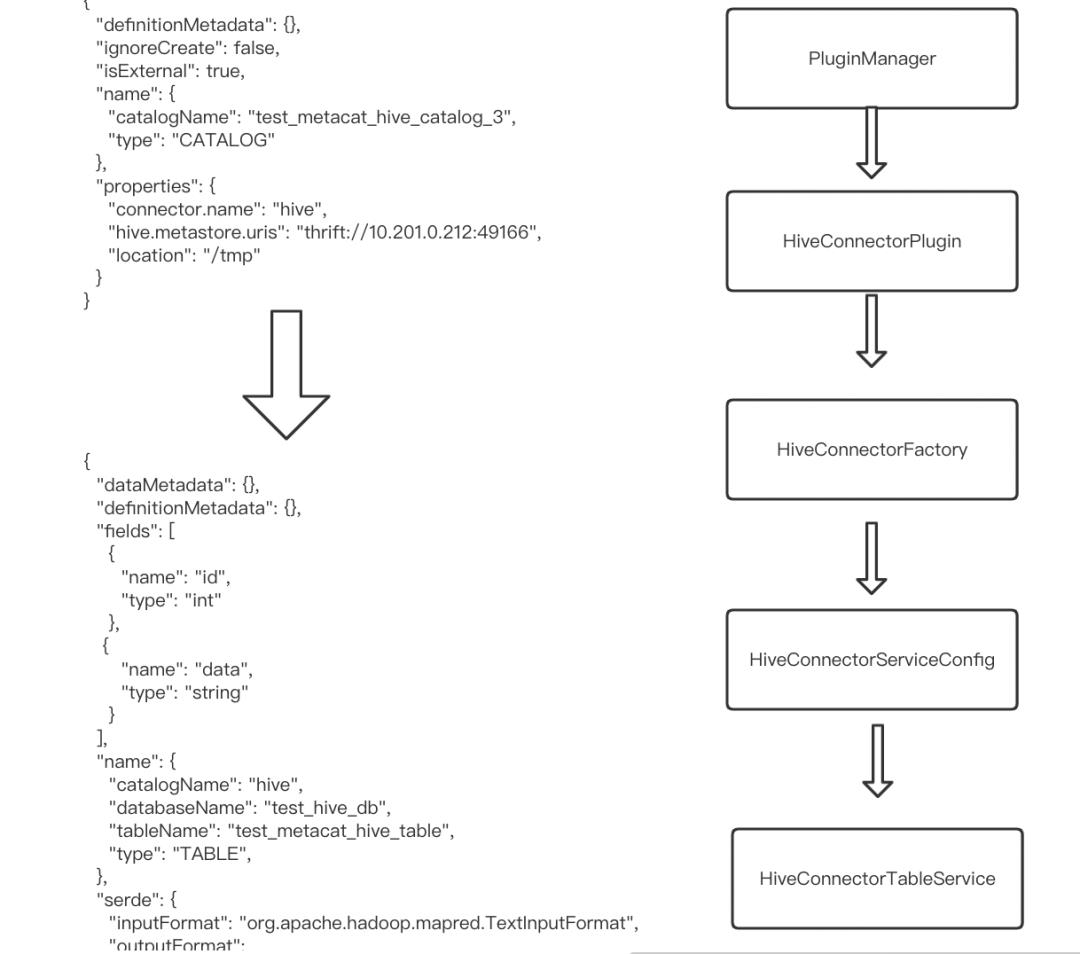
这些组件的UML关系可表示为:
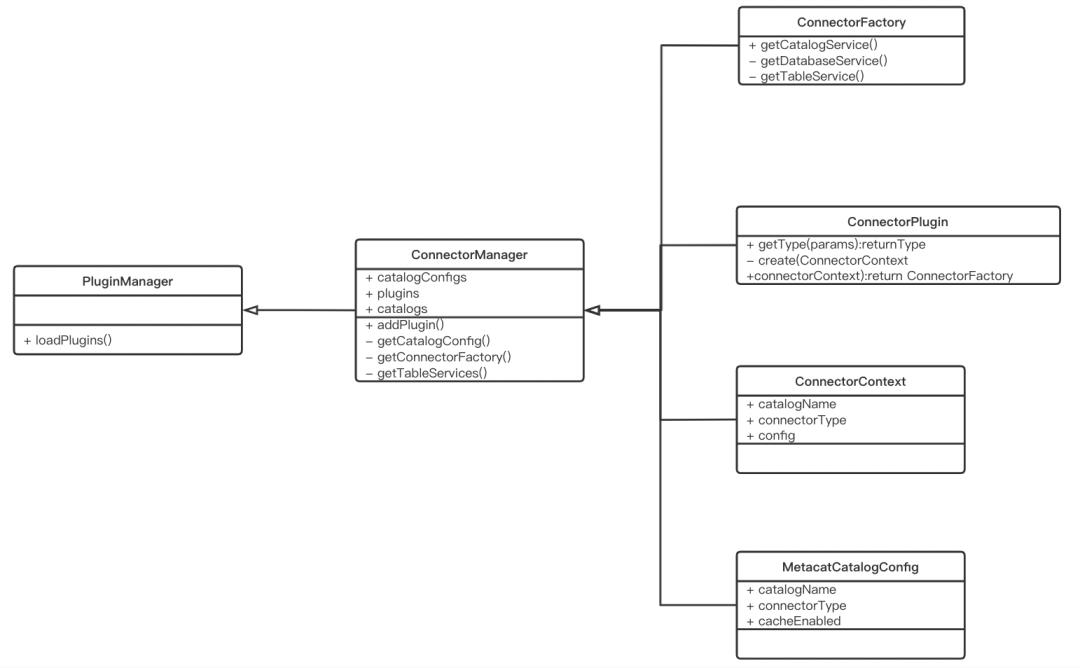
这个图表示了系统组件的宏观视图。
PluginManager
PluginManager通过SPI动态加载系统中注册的ConnectorPlugin,每种ConnectorPlugin代表一种数据源。比如系统中注册的Hive和mysql:
com.netflix.metacat.connector.hive.HiveConnectorPlugin
com.netflix.metacat.connector.mysql.MySqlConnectorPlugin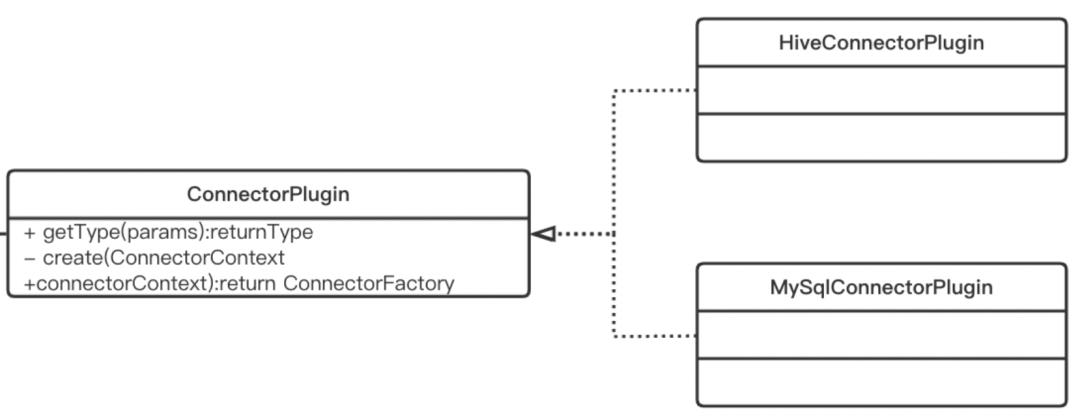
public class PluginManager
private final ConnectorManager connectorManager;
public void loadPlugins() throws Exception
final ServiceLoader<ConnectorPlugin> serviceLoader =
ServiceLoader.load(ConnectorPlugin.class, this.getClass().getClassLoader());
final List<ConnectorPlugin> connectorPlugins = ImmutableList.copyOf(serviceLoader);
for (ConnectorPlugin connectorPlugin : connectorPlugins)
log.info("Installing ", connectorPlugin.getClass().getName());
this.installPlugin(connectorPlugin);
log.info("-- Finished loading plugin --", connectorPlugin.getClass().getName());
private void installPlugin(final ConnectorPlugin connectorPlugin)
this.connectorManager.addPlugin(connectorPlugin);
PluginManager将注册的数据源注册到ConnectorManager:
public class ConnectorManager
// Map of connector plugins registered.
private final ConcurrentMap<String, ConnectorPlugin> plugins = new ConcurrentHashMap<>();
public void addPlugin(final ConnectorPlugin connectorPlugin)
plugins.put(connectorPlugin.getType(), connectorPlugin);
有了每种数据源相应的ConnectorPlugin,就能够创建对应数据源的各种元数据请求服务,比如catalogService,databaseService,tableServices等:
public synchronized void createConnection(final ConnectorContext connectorContext)
final String connectorType = connectorContext.getConnectorType();
final String catalogName = connectorContext.getCatalogName();
final ConnectorPlugin connectorPlugin = plugins.get(connectorType);
if (connectorPlugin != null)
final ConnectorFactory connectorFactory = connectorPlugin.create(connectorContext);
catalogServices.add(connectorFactory.getCatalogService());
databaseServices.add(connectorFactory.getDatabaseService());
tableServices.add(connectorFactory.getTableService());
partitionServices.add(connectorFactory.getPartitionService());
ConnectorFactory
ConnectorFactory是一个声明了获取各种元数据服务的接口:
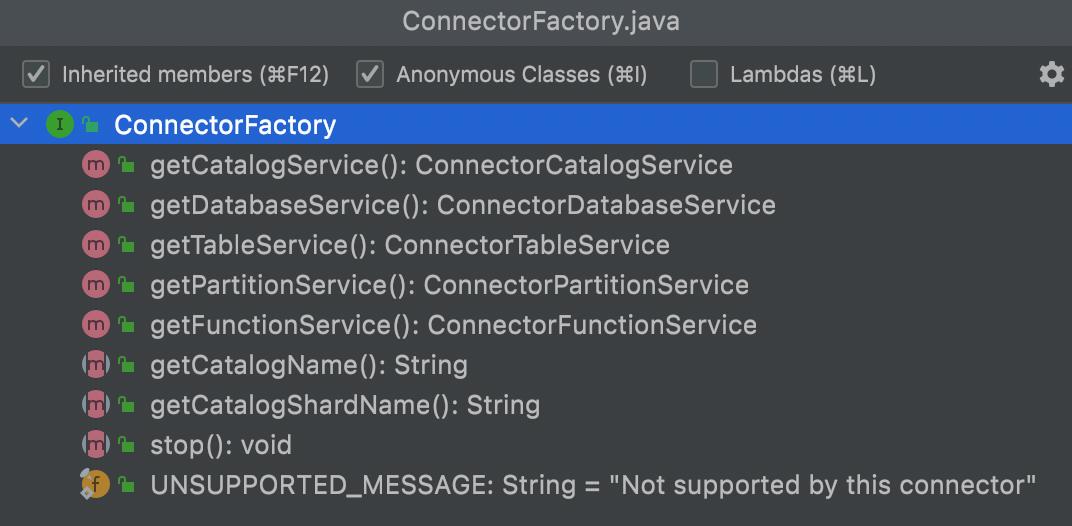
主要有两种实现:
HiveConnectorFactory
MySqlConnectorFactory两种ConnectorFactory实现方式大不相同,前者通过HMS RPC方式获取元数据,后者通过JDBC获取元数据。但对外暴露接口一样,以Hive数据源为例说明:
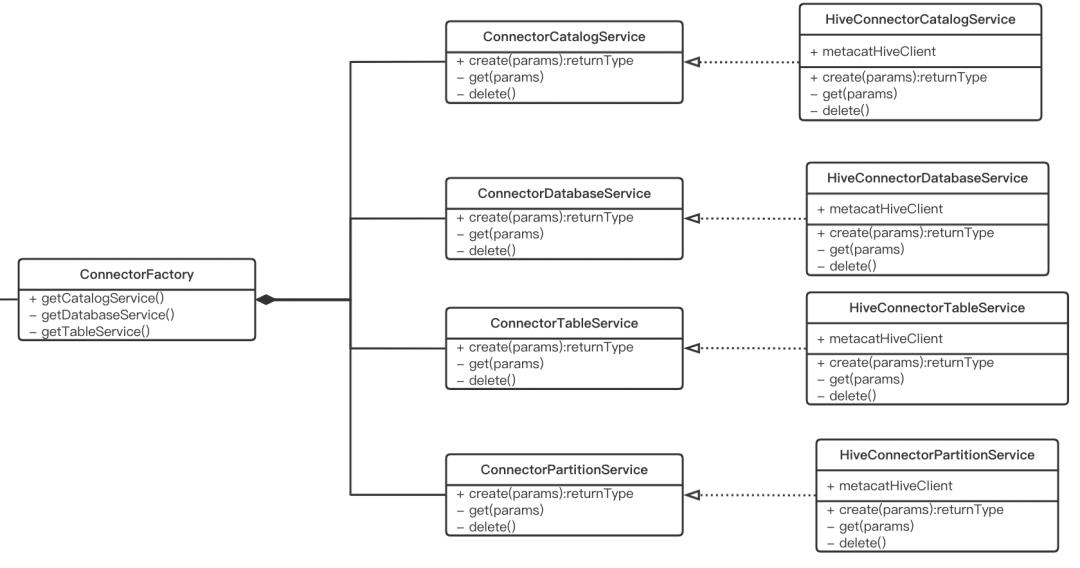
对Hive,除了通过Thrift RPC方式,Metacat还实现了另外一套快速访问元数据的方式。
HiveConnectorFactory通过Spring bean注册和获取相应的服务:
public class HiveConnectorFactory extends SpringConnectorFactory
@Override
public ConnectorCatalogService getCatalogService()
return this.ctx.getBean(HiveConnectorCatalogService.class);
@Override
public ConnectorDatabaseService getDatabaseService()
return this.ctx.getBean(HiveConnectorDatabaseService.class);
@Override
public ConnectorTableService getTableService()
return this.ctx.getBean(HiveConnectorTableService.class);
而MySqlConnectorFactory通过Guice注册和获取服务。
ConnectorCatalogService
目前只要Hive3 数据源支持实现ConnectorCatalogService,比如:
public class HiveConnectorCatalogService implements ConnectorCatalogService
private final IMetacatHiveClient metacatHiveClient;
@Override
public void create(final ConnectorRequestContext requestContext, final CatalogInfo catalogInfo)
final QualifiedName catalogName = catalogInfo.getName();
metacatHiveClient.createCatalog(hiveMetacatConverters.fromCatalogInfo(catalogInfo));
ConnectorDatabaseService
Hive实现的创建数据库方法:
public class HiveConnectorDatabaseService implements ConnectorDatabaseService
private final IMetacatHiveClient metacatHiveClient;
@Override
public void create(final ConnectorRequestContext requestContext, final DatabaseInfo databaseInfo)
final QualifiedName databaseName = databaseInfo.getName();
this.metacatHiveClient.createDatabase(hiveMetacatConverters.fromDatabaseInfo(databaseInfo));
Mysql实现的创建数据库方法:
public class JdbcConnectorDatabaseService implements ConnectorDatabaseService
@Override
public void create(@Nonnull final ConnectorRequestContext context, @Nonnull final DatabaseInfo resource)
final String databaseName = resource.getName().getDatabaseName();
log.debug("Beginning to create database for request ", databaseName, context);
try (final Connection connection = this.dataSource.getConnection())
JdbcConnectorUtils.executeUpdate(connection, "CREATE DATABASE " + databaseName);
log.debug("Finished creating database for request ", databaseName, context);
catch (final SQLException se)
throw this.exceptionMapper.toConnectorException(se, resource.getName());
ConnectorTableService
Hive实现的创建表方法:
public class HiveConnectorTableService implements ConnectorTableService
@Override
public void create(final ConnectorRequestContext requestContext, final TableInfo tableInfo)
final QualifiedName tableName = tableInfo.getName();
final Table table = hiveMetacatConverters.fromTableInfo(tableInfo);
updateTable(requestContext, table, tableInfo);
metacatHiveClient.createTable(table);
以上是ConnectorManager层的实现方式,实际上,在Controller层和ConnectorManager之间还有一个Service层,实现跟具体的Connector无关的业务逻辑,比如从Controller层 DTO对象到Connector对象类型的转换,业务元数据和用户元数据的校验和存取,以及元数据的版本管理和消息订阅等功能。
以上是关于Metacat实现原理解析的主要内容,如果未能解决你的问题,请参考以下文章