论文笔记 StructCoder: Structure-Aware Transformer for Code Generation
Posted nbyvy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记 StructCoder: Structure-Aware Transformer for Code Generation相关的知识,希望对你有一定的参考价值。
目录
具有结构感知力的自注意力机制structure-aware self-attention
模型的限制与更深思考
简单介绍
这篇文章介绍提出了一个具有代码结构感知能力的Transformer模型用来处理代码翻译(基于某种程序语言生成另一种程序语言)和代码生成任务(基于自然语言描述生成程序语言)。
摘要
Transformer在处理自然语言任务上取得了不错的效果,由于代码语言(PL)和自然语言(NL)
之间存在一定的共同性,因此近年来有很多的组织开始使用Transformer来处理PL任务。
但是相比于自然语言,程序语言具有更强的语义和句法逻辑,基于此,开发者改进Transformer提出StructCoder模型,使模型的编码器可以很好的学到source code的语法和数据流向(data flow),模型的解码器可以很好的学到target code的语法和数据流。此模型在CodeXGLUE 集上是目前的SOTA模型。
目前已有的两种代码句法表征方法是将以下两种结构编码进模型:
- AST(Abstract Syntax Tree ,抽象语法树):生成AST的中序遍历,AST的生成规则,使用RNN 编码AST的路径,在序列模型中使用基于AST的attention机制;
- DFG(Data Flow Graph 数据流向图):含有的信息比AST更多,却没有AST复杂。
int add1 ( int a ) s= a + 1 ; return s ; 基于以上代码生成的AST与DFG分别如下图所示:
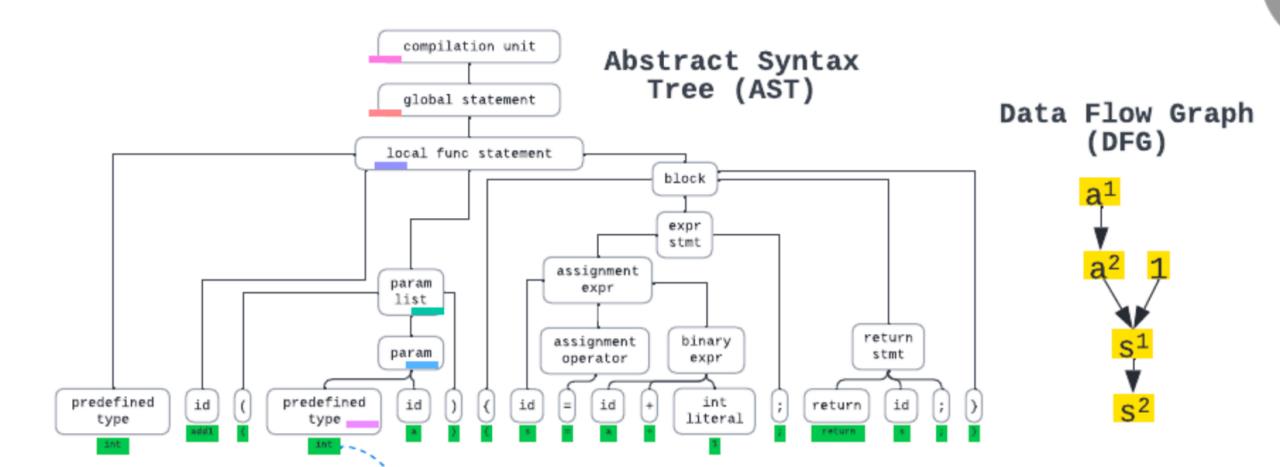
相关模型结构的比较
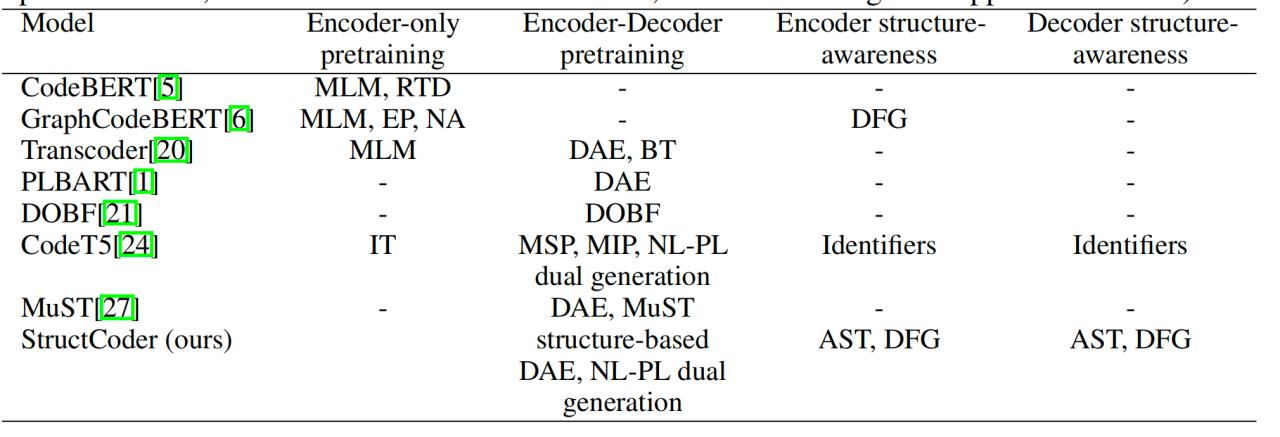
MLM :Masked Language Modeling
RTD:Replaced Token Detection
DAE:Denoising Autoencoding
BT:Back-Translation
本文的贡献
- 改进Transformer模型使编码器解码器都具有结构感知能力,提出StructCoder:
- 编码器使用结构感知自注意力机制(structure-aware self-attention);
- 解码器加入两项附加任务:APP(AST路径预测),DFP(数据流向预测);
- 预训练,使输入的代码、AST和DFG中部分失去意义,以此训练生成原始代码并且进行APP和DFP两项训练任务;
3. StructCoder是目前基于CodeXGLUE 数据集的SOTA模型。
StructCoder模型与设计
符号表示
Code
Source Code tokens 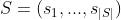 ;
;
Target Code tokens 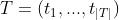 。
。
AST
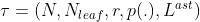
N代表AST中所有节点的集合;
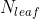 代表所有AST中的叶子节点;
代表所有AST中的叶子节点;
r代表AST的根结点;
p(n)表示的节点n的父节点;
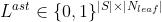 ,当且仅当token
,当且仅当token 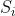 是叶节点
是叶节点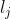 一部分时
一部分时 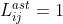 ;
;
n.type代表是一个节点的类型。
DFG
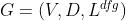
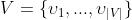 代表了Code S中的所有变量;
代表了Code S中的所有变量;
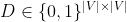 是两个变量之间的邻接矩阵,当且仅当
是两个变量之间的邻接矩阵,当且仅当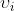 来源于
来源于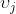 时
时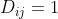 ;
;
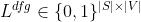 ,当且仅当变量是token
,当且仅当变量是token 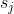 的一部分时,
的一部分时, 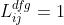 。
。
编码器Encoder
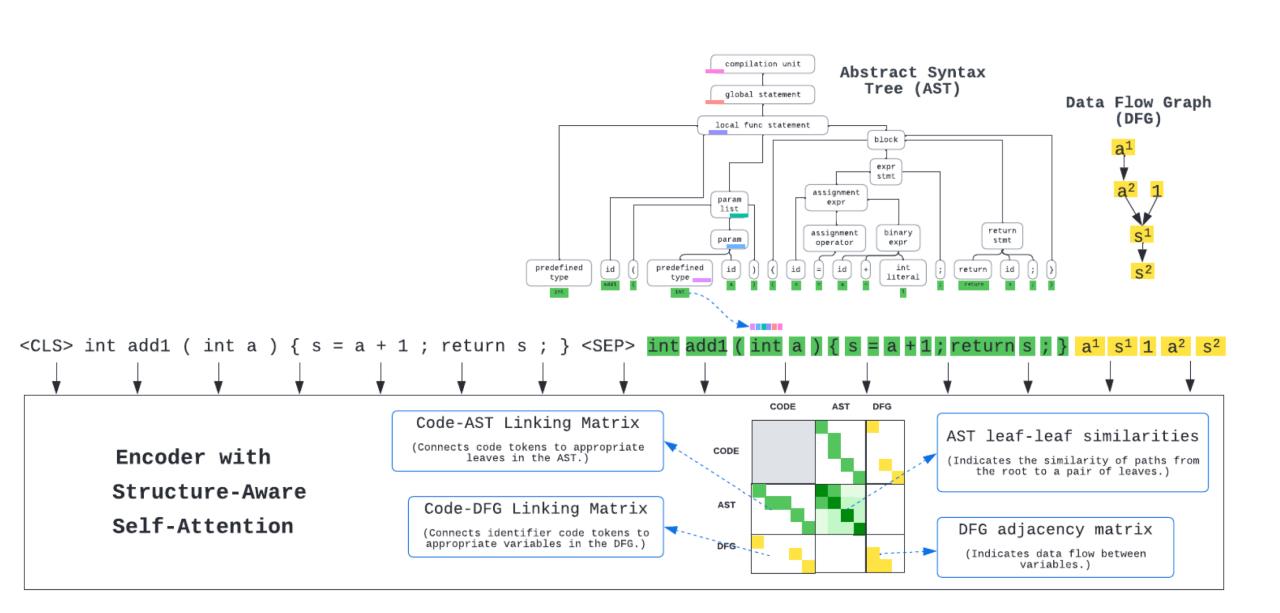
输入编码Input emdedding
输入序列由源代码tokens,对应的AST叶节点,对应的DFG变量构成:
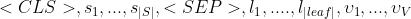
token:通过单词表来编码;
DFG变量:use a default emdedding(原文是这么写的,还不是很理解);
AST叶节点:需要按照以下公式编码叶节点的路径信息:
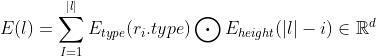
其中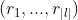 为根结点
为根结点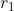 到该叶节点
到该叶节点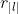 的路径上的节点;
的路径上的节点;
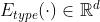 为节点类型的编码函数;
为节点类型的编码函数;
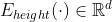 为节点顺序编码函数。
为节点顺序编码函数。
具有结构感知力的自注意力机制structure-aware self-attention
代码之间Code-code:和传统注意力计算方式一致
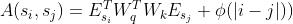
其中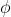 代表的lookup emdedding函数,用来存储两个token之间的相对位置信息。
代表的lookup emdedding函数,用来存储两个token之间的相对位置信息。
叶节点之间Leaf-leaf:除了计算两个叶节点之间的自注意力之外还需要计算两节点之间的相似度
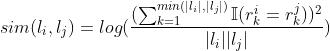
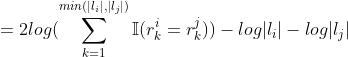
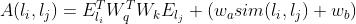
变量之间Variable-variable:两个变量之间有联系才会计算注意力
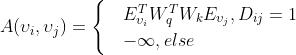
代码与叶节点或者变量之间Code-leaf/variable:两者相互之间有联系才会计算注意力
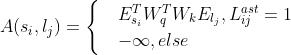
特殊符号<CLS>和<SEP>被视作代码并且和其他所有的变量与叶节点有联系。
上图就代表了输入编码和注意力机制的可视化表示。
解码器Decoder
在解码器的输出需要完成三个任务:基于以输出序列的下一个token的预测,根叶节点路径预测和DFG变量之间联系预测。
语言模型Token预测
和传统的语言模型一样。
概率:
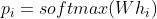
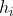 为解码器第i个时刻隐藏层的输出向量;
为解码器第i个时刻隐藏层的输出向量;
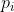 为第i个时刻各个token的预测概率。
为第i个时刻各个token的预测概率。
损失:
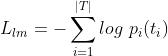
 为第i个时刻输出的在正确token上面的预测概率。
为第i个时刻输出的在正确token上面的预测概率。
AST路径预测APP
时刻i,根叶路径 中第k个节点的概率分布:
中第k个节点的概率分布:
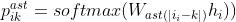
损失:
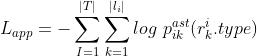
DFG关系预测DFP
第i个时刻的token来自于第j个时刻的token的概率:
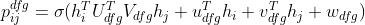
cond判断在ground truth中两个token有联系(一个来源于另一个):
存在两个有联系的变量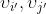 即
即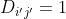 ,使得
,使得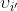 与token
与token 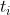 有联系即
有联系即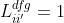 ,并且
,并且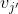 和token
和token 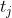 有联系即
有联系即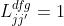 。
。
损失:
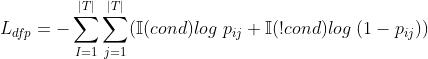
decoder总损失
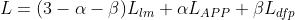
预训练
增加噪声:掩盖或者去除原始输入的35%的token,AST叶节点与DFG变量,和35%的叶节点路径;
模型参数初始化:使用CodeT5模型中的参数来初始化本次预训练的参数,与AST,DFG有关的参数随机初始化;
数据集:CodeSearchNet
实验结果
PL-PL
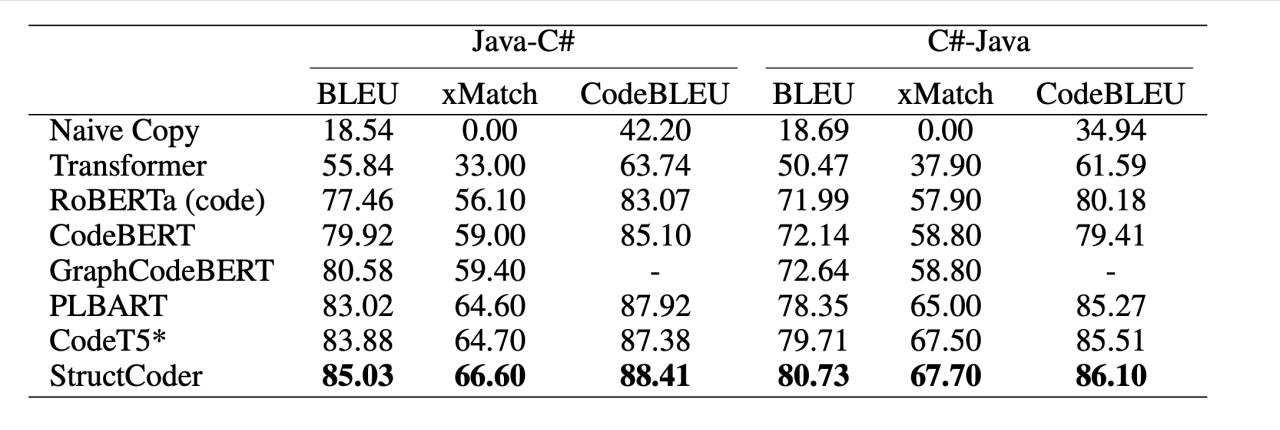
NL-PL
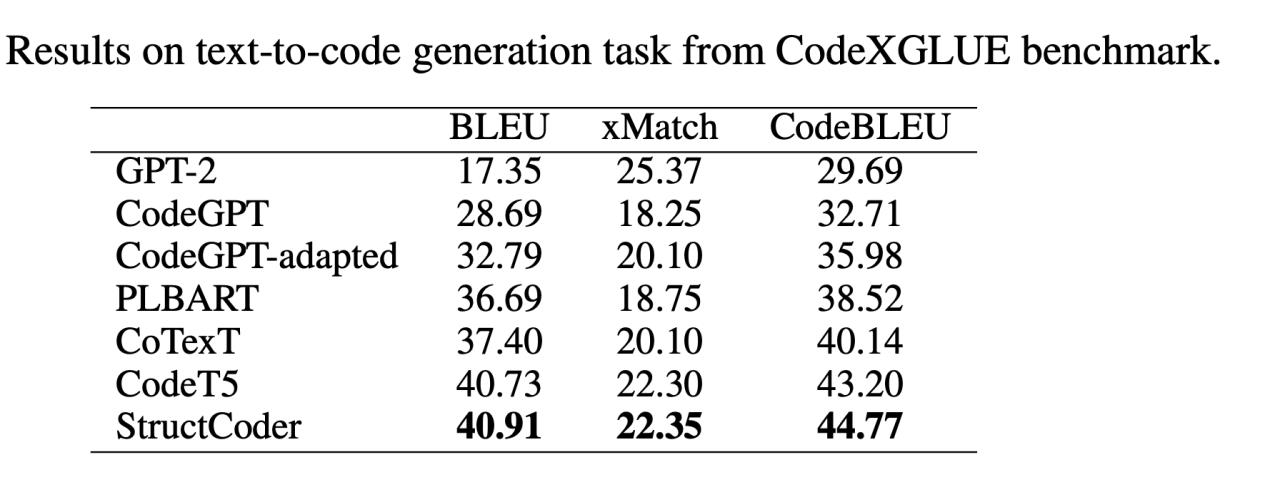
从上述数据可以看出CodeT5是一个有力的竞争对手,而StructCoder是在CodeXGLUE上实现代码翻译和代码生成的SOTA模型。
案例对比

说明StructCoder可以很好学习到代码中的语义与数据流向。
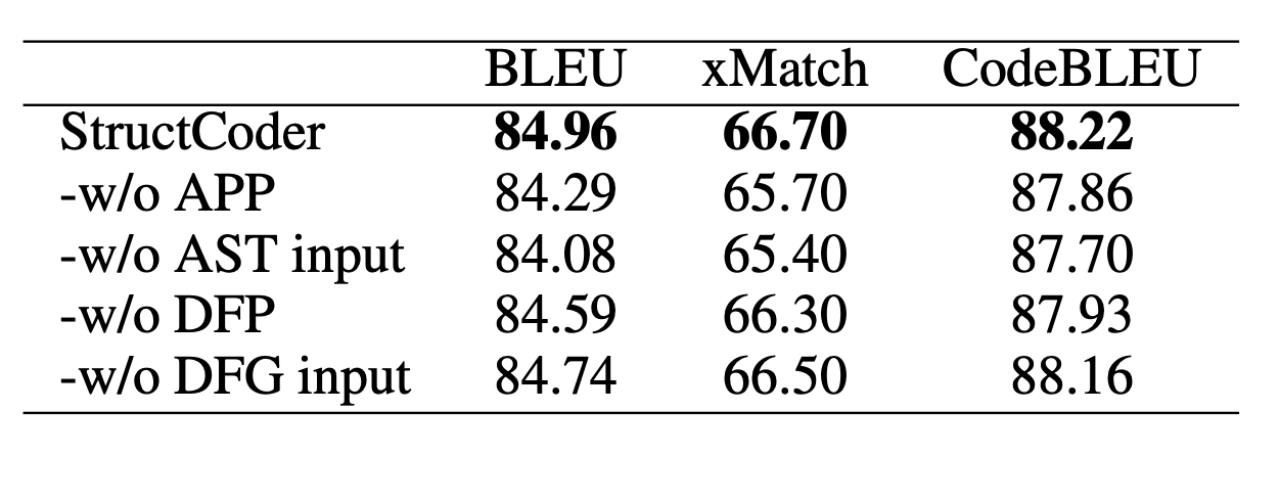
消融实验
去除StructCoder中的某一个组件,观察StructCoder中的表现,发现去除任意一个组件都会降低StructCoder的评价表现,尤其是去除AST输入之后。
模型的限制与更深思考
- 由于在输入序列中加入了AST与DFG信息,处理起来复杂度增加尤其是在算注意力时复杂度二次增长
- 存在少数bad case,需要二次加工
- 代码的生成有多种正确答案,而在训练时数据集只有一个ground truth,因此需要制定合适的评价标准
- 生成的代码缺少安全性,有效性,模块化方面的思考
- 只有大企业才适合训练此巨大规模的模型
以上就是我认为论文中值得学习的内容,更多的训练细节与超参设置推荐去阅读原文!
以上是关于论文笔记 StructCoder: Structure-Aware Transformer for Code Generation的主要内容,如果未能解决你的问题,请参考以下文章