线性回归实验之成人死亡率预测
Posted CSU迦叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线性回归实验之成人死亡率预测相关的知识,希望对你有一定的参考价值。
对数据集进行的改进:和死亡率的皮尔逊系数小于0.01的参数被我丢掉了——
'infant deaths', 'Measles ', 'under-five deaths ', 'Population', 'Year'
可选线性模型:RandomForestRegressor, ExtraTreesRegressor 感觉效果差不多
可选验证方法:GridSearchCV, RandomizedSearchCV(前者是穷举,后者是抽取n_iter个参数组合进行验证,想要模型性能选前者,想要节省时间选后者)
代码
import time
from sklearn.metrics import mean_squared_error, r2_score
import seaborn as sns
import pandas as pd
import sklearn
import numpy as np
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import MinMaxScaler
from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
import joblib
# 读取数据集
train_data = pd.read_csv('your_path/train_data.csv')
model_filename = 'your_path/your_model_name.pkl'
imputer_filename = 'your_path/your_imputer_name.pkl'
scaler_filename = 'your_path/your_scaler_name.pkl'
def preprocess_data(data, imputer=None, scaler=None):
print("data.shape", data.shape)
column_name = ['Year', 'Life expectancy ', 'infant deaths',
'Alcohol', 'percentage expenditure', 'Hepatitis B', 'Measles ', ' BMI ',
'under-five deaths ', 'Polio', 'Total expenditure', 'Diphtheria ',
' HIV/AIDS', 'GDP', 'Population', ' thinness 1-19 years',
' thinness 5-9 years', 'Income composition of resources', 'Schooling']
data = data.drop(["Country", "Status"], axis=1)
if imputer == None:
imputer = SimpleImputer(strategy='mean', missing_values=np.nan)
imputer = imputer.fit(data[column_name])
data[column_name] = imputer.transform(data[column_name])
if scaler == None:
scaler = MinMaxScaler()
scaler = scaler.fit(data)
data_norm = pd.DataFrame(scaler.transform(data), columns=data.columns)
data_norm = data_norm.drop(
['infant deaths', 'Measles ', 'under-five deaths ', 'Population', 'Year'], axis=1)
print("data_norm.shape", data_norm.shape)
print("type(data_norm)", type(data_norm))
return data_norm, imputer, scaler
def model_fit(train_data):
train_y = train_data.iloc[:, -1].values
train_data = train_data.iloc[:, :-1]
train_data_norm, imputer, scaler = preprocess_data(train_data)
train_x = train_data_norm.values
# 需要网格搜索的参数
n_estimators = [i for i in range(650, 681, 5)]
max_depth = [i for i in range(14, 18)] # 最大深度
min_samples_split = [i for i in range(2, 4)] # 部节点再划分所需最小样本数
min_samples_leaf = [i for i in range(3, 5)] # 叶节点最小样本数
max_samples = [i/100 for i in range(95, 97)]
parameters = 'n_estimators': n_estimators, # 弱学习器的最大迭代次数
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'max_samples': max_samples
regressor = RandomForestRegressor(
bootstrap=True, oob_score=True, random_state=0)
gs = RandomizedSearchCV(regressor, parameters, n_iter = 100,refit=True,
cv=10, verbose=1, n_jobs=-1)
gs.fit(train_x, train_y)
joblib.dump(gs, model_filename)
joblib.dump(imputer, imputer_filename)
joblib.dump(scaler, scaler_filename)
return gs
def predict(test_data):
loaded_model = joblib.load(model_filename)
imputer = joblib.load(imputer_filename)
scaler = joblib.load(scaler_filename)
test_data_norm, _, _ = preprocess_data(test_data, imputer, scaler)
test_x = test_data_norm.values
predictions = loaded_model.predict(test_x)
return predictions
# 咳咳 开始训练了
time_start = time.time()
model = model_fit(train_data)
print('最优参数: ', model.best_params_)
print('最佳性能: ', model.best_score_)
time_end = time.time()
time_sum = time_end - time_start
label = train_data.loc[:, 'Adult Mortality']
data = train_data.iloc[:, :-1]
# 咳咳 开始预测了
y_pred = predict(data)
r2 = r2_score(label, y_pred)
mse = mean_squared_error(label, y_pred)
print("MSE is ".format(mse))
print("R2 score is ".format(r2))训练集上结果

Mo平台测试结果
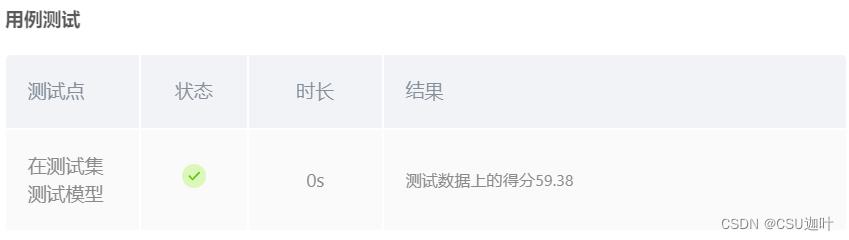
不想再改了,就它吧。
以上是关于线性回归实验之成人死亡率预测的主要内容,如果未能解决你的问题,请参考以下文章