H264熵编码之CABAC
Posted 贺二公子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了H264熵编码之CABAC相关的知识,希望对你有一定的参考价值。
原文地址:https://blog.csdn.net/weixin_38189964/article/details/116953871
文章目录
算术编码
算术编码
例1:假设信源符号为A, B, C, D,这些符号的概率分别为 0.1, 0.4, 0.2,0.3 ,根据这些概率可把间隔[0, 1]分成4个子间隔:[0, 0.1), [0.1, 0.5), [0.5, 0.7), [0.7, 1)。

如果二进制消息序列的输入为:C A D A C D B。编码时首先输入的符号是C,找到它的编码范围是[0.5,0.7]。由于消息中第二个符号A的编码范围是[0, 0.1],因此它的间隔就取[0.5, 0.7]的第一个十分之一作为新间隔[0.5,0.52]。依此类推,编码第3个符号D时取新间隔为[0.514, 0.52],编码第4个符号A时,取新间隔为[0.514, 0.5146],…。消息的编码输出可以是最后一个间隔中的任意数。整个编码过程如图所示:
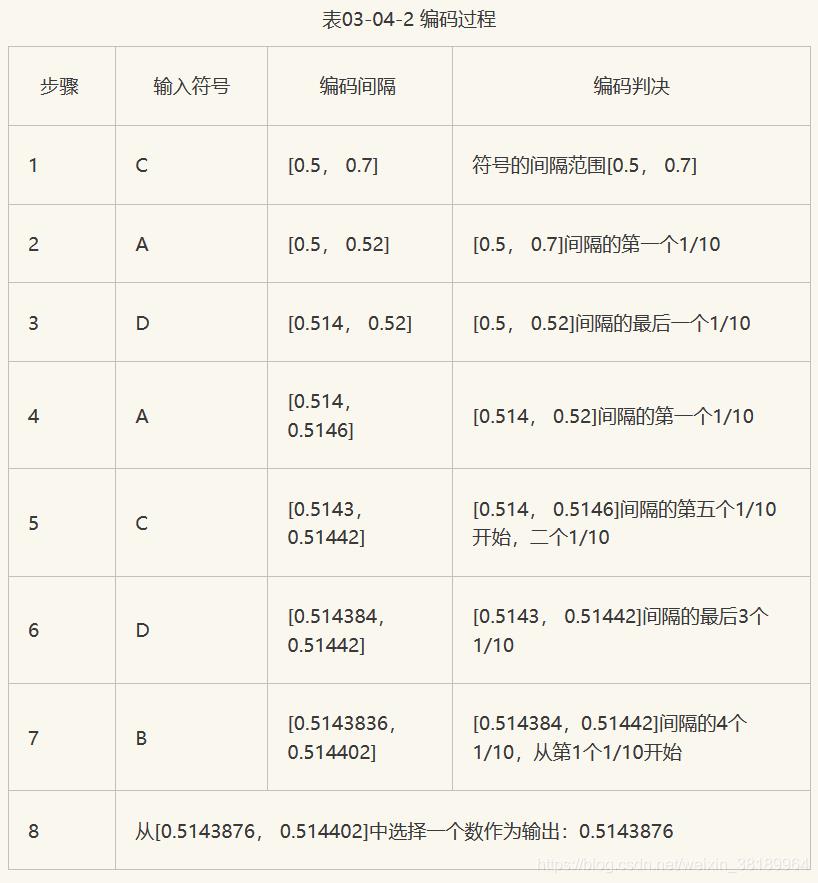
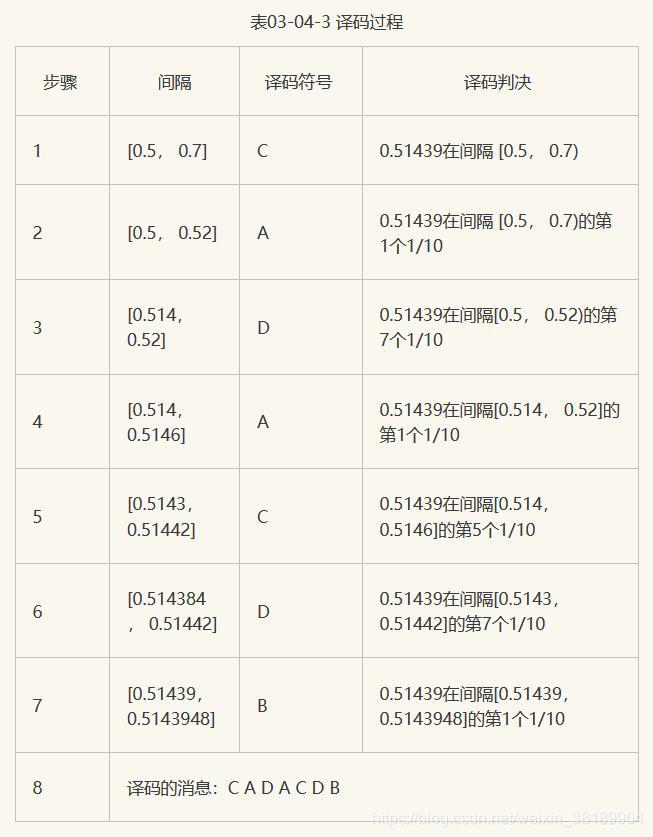
在上面的例子中,我们假定编码器和译码器都知道消息的长度,因此译码器的译码过程不会无限制地运行下去。实际上在译码器中需要添加一个专门的终止符,当译码器看到终止符时就停止译码。
二进制算术编码
二进制算术编码的编码过程


二进制算术编码的解码过程

CABAC讲解
一、CABAC目的
用于H264的语法编码以及数据残差的熵编码
二、编码流程
- 二值化:CABAC使用二进制算数编码,这意味着仅仅有两个数字(1 或 0)被编码。一个非二进制的数值符号,比如一个转换系数或者运动适量,在算术编码之前会首先被二值化或者转化成二进制码字。这个过程类似于将一个数值转化成可变长码字,但是这个二进制码字在传输之前会通过算术编码器进一步的编码。
- 上下文模型选择:上下文模型就是一个概率模型,这个模型是根据最近的被编码的数据符号的统计数字而选择的一个模型。这个模型保存了每个‘bin’是1或者0的概率。
- 算术编码:算术编码器根据选择的概率模型对每一个‘bin’进行编码。
- 概率更新:被选中的上下文模型会根据实际的编码值而去更新。例如,如果bin的值是 1,那么 1 的频率计数会增加。对于被二值化的符号中的每个比特或‘bin’,会重复执行阶段2、3和4。如图:
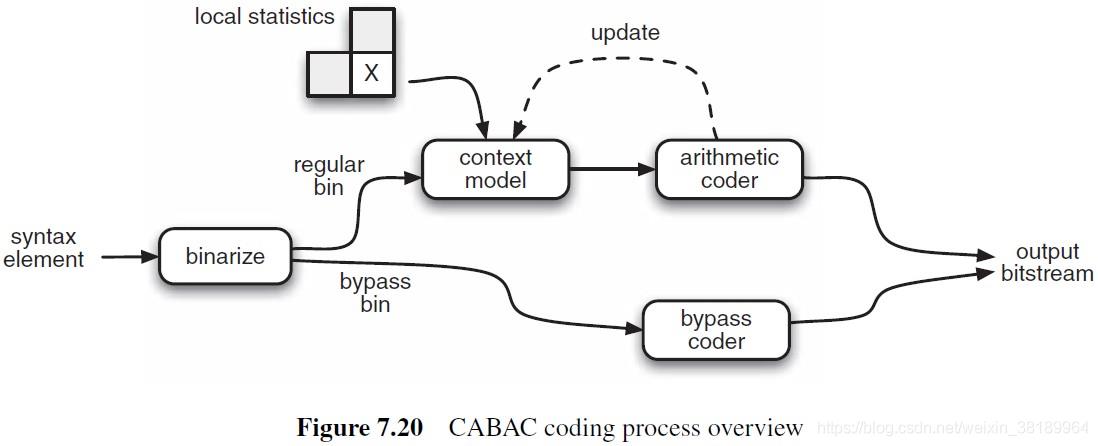
- 归一化生成最终编码结果
三、二值化
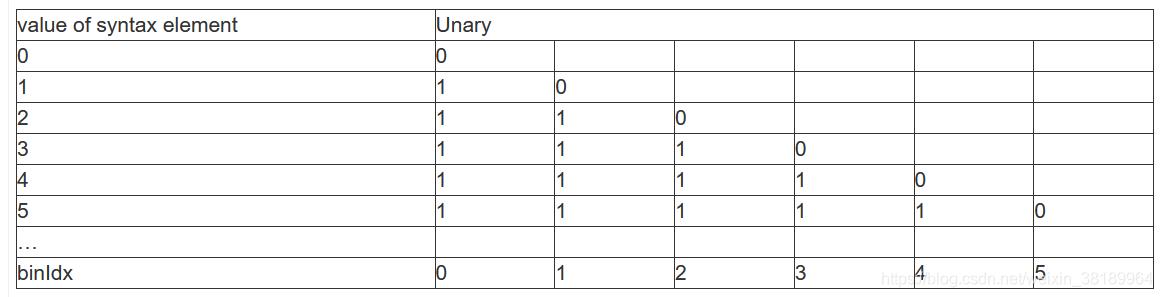
- 一元码(Unary)
对于一个非二进制的无符号整数值符号x?0,在CABAC中的一元码码字由xx个“1”位外加一个结尾的“0”组成,见下表。例如,输入的语法元素值为3,其二值化结果为1110。
- 截断一元码(TU,Truncated Unary)
一元码的变体,用在已知语法元素的最大值cMax的情况。对于0?x<cMax的范围内的取值,使用一元码进行二值化。对于x=cMaxx=cMax,其二值化的二进制串全部由“1”组成,长度为cMax。例如,当cMax=5时,语法元素值为4的二进制串为11110,语法元素值为5的二进制串为11111。 - k阶指数哥伦布编码(kth order Exp-Golomb,EGk)
在计算机中,一般数字的编码都为二进制,但是由于以相等长度来记录不同数字,因此会出现很多的冗余信息,如下:
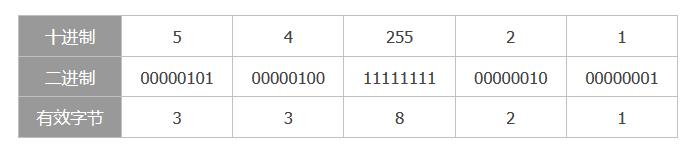
如数字1,原本只需要1个bit就能表示的数据,如今需要8个bit来表示,那么其余7个bit就可以看做是冗余数据。在网络传输时,如果以原本等长的编码方式来传输数据,则会出现很大的冗余量,加重网络负担;但是如果只用有效字节来传输上述码流,则会是:10110011111111101,这样根本不能分离出原本的数据。
哥伦布编码则是作为一种压缩编码算法,能很有效地对原本的数据进行压缩,并且能很容易地把编码后的码流分离成码字。
哥伦布编码就采用了加0前缀,用于表达码字的信息量,在得到m个0前缀后,就能知道该码字在码流中的长度,并从码流中把码字分离出来。
指数哥伦布码的比特串分为“前缀”(prefix)和“后缀”(suffix)两个部分。它的逻辑结构为:[(M-k)Zeros][1][M个bits INFO]
编码后码长为2M + 1 + k,M为前缀长度,1为中间的1长度,M+k为后缀长度,其中k为阶数
设置编码数值为codeNum,可得M和INFO值为:
M = f l o o r ( l o g 2 [ c o d e N u m + 2 k ] ) M = floor(log2[codeNum + 2^k]) M=floor(log2[codeNum+2k])
I N F O = c o d e N u m + 2 k − 2 M INFO = codeNum + 2^k - 2^M INFO=codeNum+2k−2M
解码时,前缀0的个数和k可得到M,则可计算出codeNum。
H264使用0阶编码。 - 定长编码(FL,Fixed-Length)
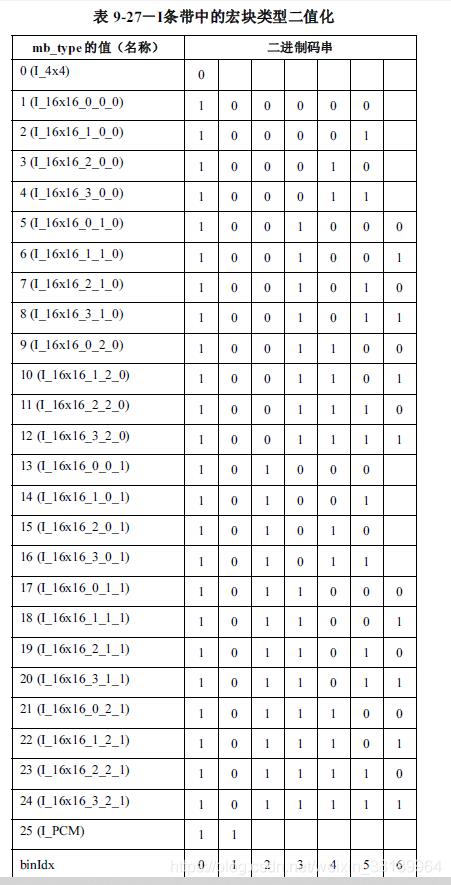
用定长编码二进制的无符号语法元素, 语法元素的最大值cMax已知,那么定长编码的长度为fixlength=?log2(cMax+1)?fixlength=?log2(cMax+1)?,其中值就是语法元素的值的二进制。定长编码用于近似均匀分布的语法元素的二值化,可以理解为十进制二进制化 - mb_type与sub_mb_type特有的查表方式
- 4位FL与截断值为2的TU联合二值化方案
这种方案只用于对语法元素CBP的二值化。4位的FL(cMax=15)的前缀用于编码亮度CBP,2位的TU用于编码色度CBP(当色彩格式为4:2:0或4:2:2时才会存在这个后缀) - TU与EGk的联合二值化方案(UEGk,Unary/kth order Exp-Golomb)
这种方案的前缀使用一元截断码,后缀使用k阶哥伦布编码。但是在取值较小的范围内,只用一元码表示(即只有前缀部分)。对于不同的语法元素,有不同的截断值与阶数。如下表为abs_level_minus1的二值化表(cMax=14的TU、0阶哥伦布编码)
四、自适应
-
自适应的基本介绍
在CABAC中所有的信息都会转换为二进制数据进行编码,即0和1两种字符。因此在CABAC中,概率模型实际上只包含有一个概率——P(a),另外一个元素P(b)实际上等于1-P(a),其中a=1,b=0或相反。无论二者关系如何,总有一个值的概率不小于0.5,另一个值的概率不超过0.5。其中,概率不大于0.5的字符定义为LPS(Least Probability Symbol),概率不小于0.5的字符定义为MPS(Most Probability Symbol),分别用于表示当前状态下的小概率字符以及大概率字符。
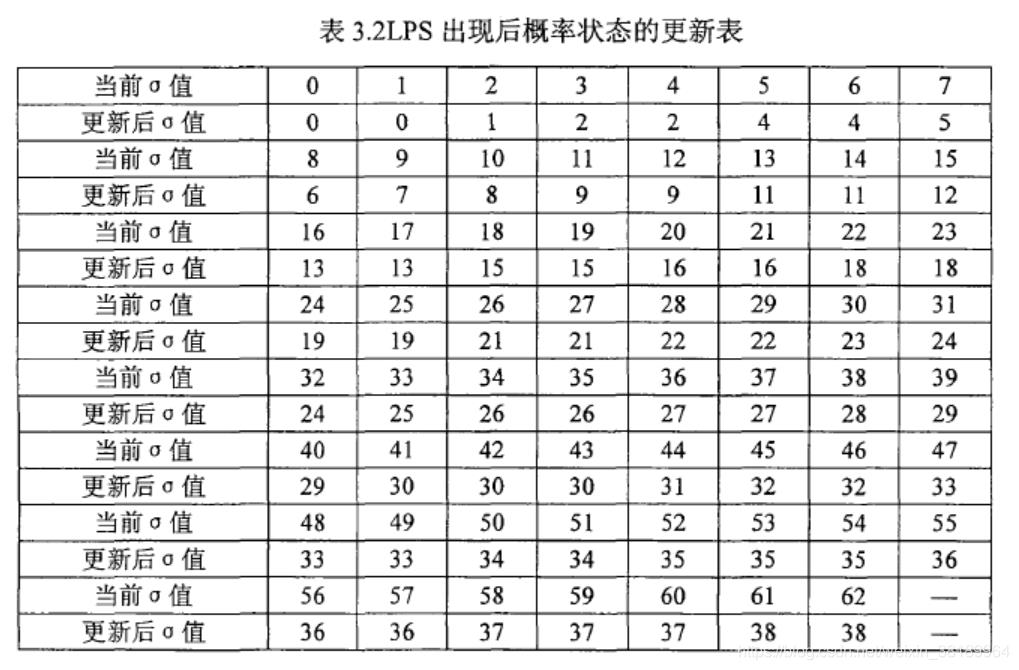
对于CABAC的算术编码中,根据先验知识为LPS的概率设定了64个代表概率,认为LPS的概率值只在这64个代表概率之间变化,而不会取为其他值,如下:

这样,由σ就构成了概率模式的64个概率状态,P0 = 0.5,P1=0.95*P0,…,P63=0.01875.
由于σ与Pσ是一一对应的关系,Pσ的自适应更新就表现为σ值的变化。所以,用σ的更新就代表Pσ的更新。由于二进制算术编码只有LPS和MPS两个符号,LPS的概率确定了,MPS的概率也就确定了,这样,Pσ值的确定和更新就代表了整个概率模型的概率分配的确定和更新。如此一来,概率的自适应估计问题就转化为概率状态σ值的自适应更新问题,接下来看σ值的确定和更新。 -
自适应更新过程
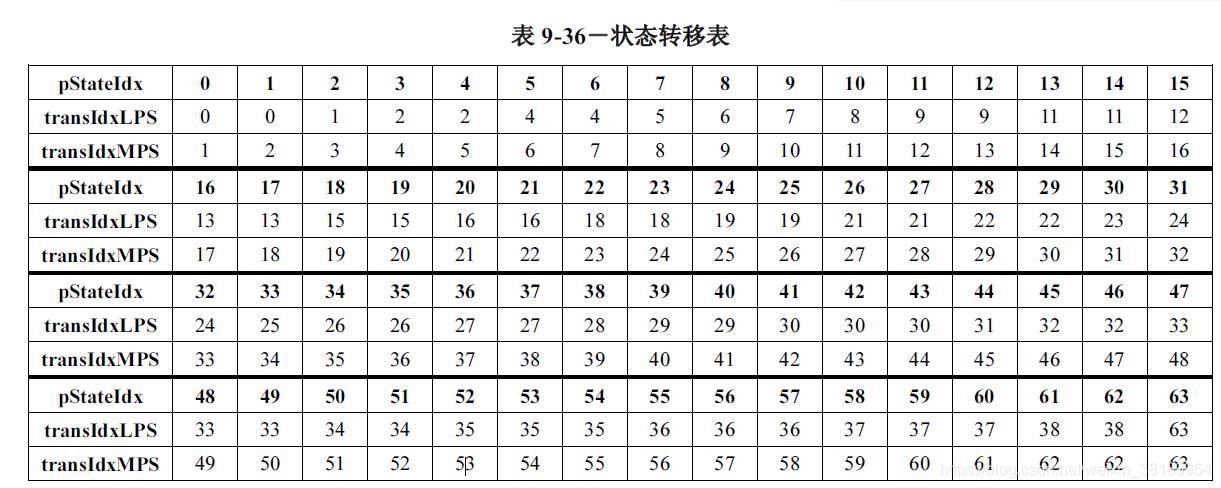
在CABAC中所有的概率模型都是自适应模型(σ=63除外)在每个符号被编码后,概率估计会被更新。在CABAC中,诶编码完一个比特位后,都要进行概率更新。从而得到新的概率状态,实现context自适应编码。概率状态的自适应更新发生在对每一个二进制符号编码之后。概率状态σ值自适应更新的法则是:
若MPS出现,σ++;σ=62后,若再出现MPS,则σ保持62不变。可以看出,σ增加则意味着Pσ值得减少,从俄日(1-Pσ)的值增大,它的实际意义就是表示下一次的MPS的概率增大,而出现LPS的概率减小。如果σ=62,这就意味着LPS出现的概率值Pσ已达到最小,而相应得MPS出现的概率(1-Pσ)已达到最大,因此σ不再改变,直到LPS出现为止。需要指出的是,当σ=0时,若LPS出现,更新后的σ仍为0,但LPS与MPS的值互换了;另外,σ=63倍固定用来对算术编码结束判断进行编码,不参与自适应。
-
概率状态的初始化
前文已经提到自适应算术编码把各类符号的概率初始值定为1/N,如果直接把LPS和MPS初始值定为1/2—即把σ的初始值定为0,这种概率的初始化方法虽然算法简便,但没有利用之前的信息,会影响数据压缩效率。
在H264中,slice是自适应编码的基本单位。因为后向自适应过程不会超过整个片的编码过程的持续时间,它表示整个自适应过程的一个数目,所有模型不得不在slice边缘重新初始化,采用一些预先定义的概率初始化,初始化的重要依据是QP参数,各slice的QP参数不同,则在初始化时各概率状态值不同。
根据以上分析,取概率状态的初始化另一种方法:把每个context modle下的0-1概率分布的经验值作为其初始概率,以此推算出该context model的概率状态下的初值,同时也确定了MPS和LPS的初值。
在这种方法中,σ的初始值的取值要受两个因素的影响:第一:其所对应的的context model;第二:系数的量化步长QP。
每个context model下的σ初始值可用下面流程得到:
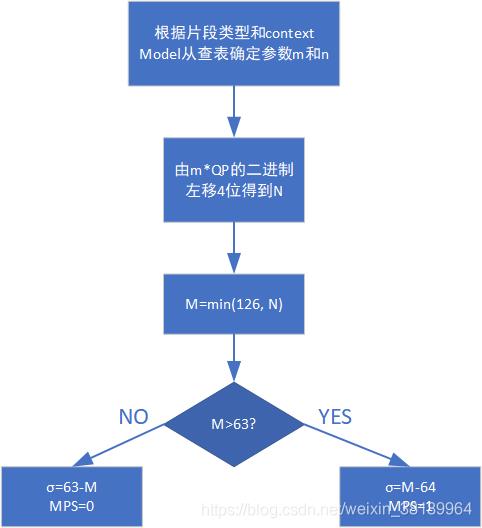
m和n的值可以通过查表获得,不需要在线计算,提高了运算速度。查询表如下:(h264官方手册的表9-12到9-24)
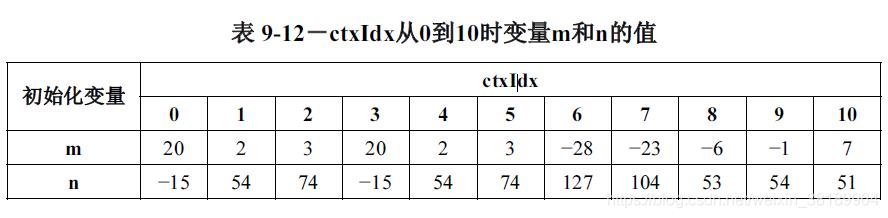
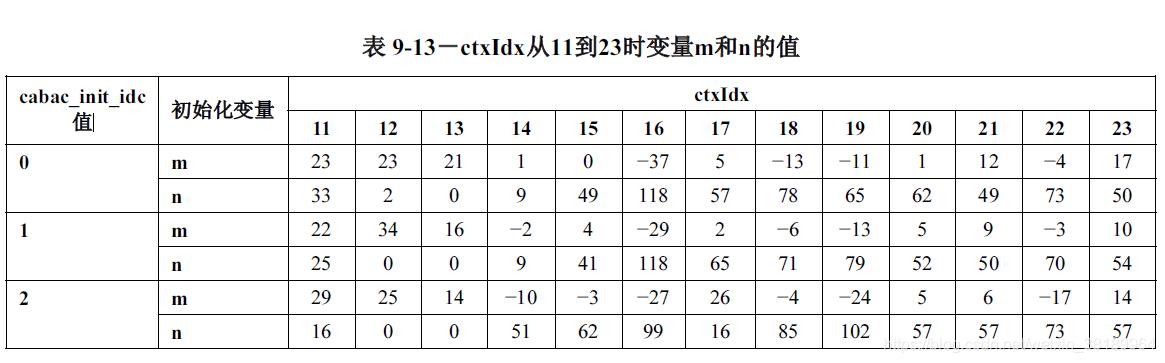
表中,cabac_init_idc为句法元素的值,取值范围为0-2,表示用于决定关联变量的初始化过程中使用的初始化表格的序号。
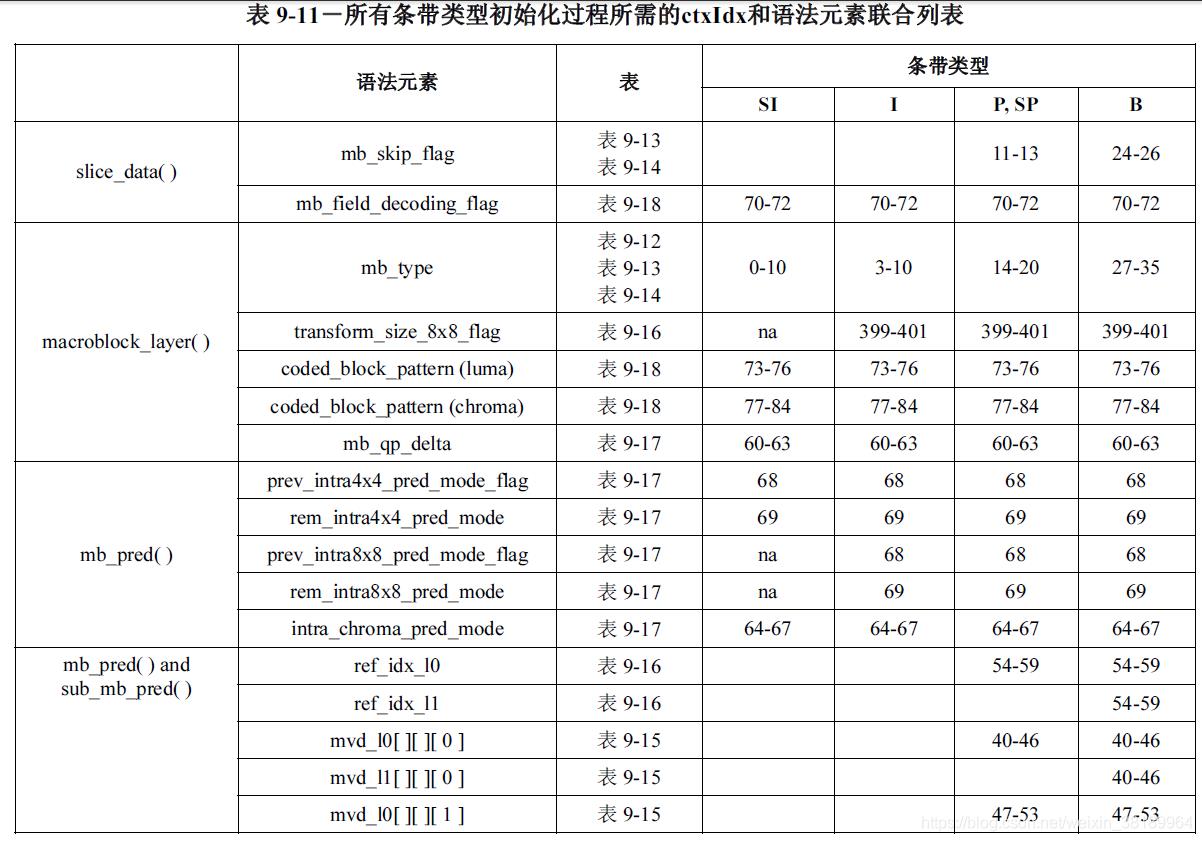
在表9-11中,列出了所有条带类型需要初始化的ctxIdx,同时包含了初始化过程中需要的m和n的值的表格编号也在表中列出。
根据以上的分析,我们知道m和n确定σ和LPS的初始化值,然后根据σ的状态转换表可以得到更新的σ值。m和n与ctxIdx相关,那么ctxIdx又是如何获取的呢?给定binIdx、maxBinIdxCtx和ctxIdxOffset,由9.3.3.1中定义的过程导出ctxIdx,可参考H264文档9.3.3.1节。
五、归一化
编码部分:
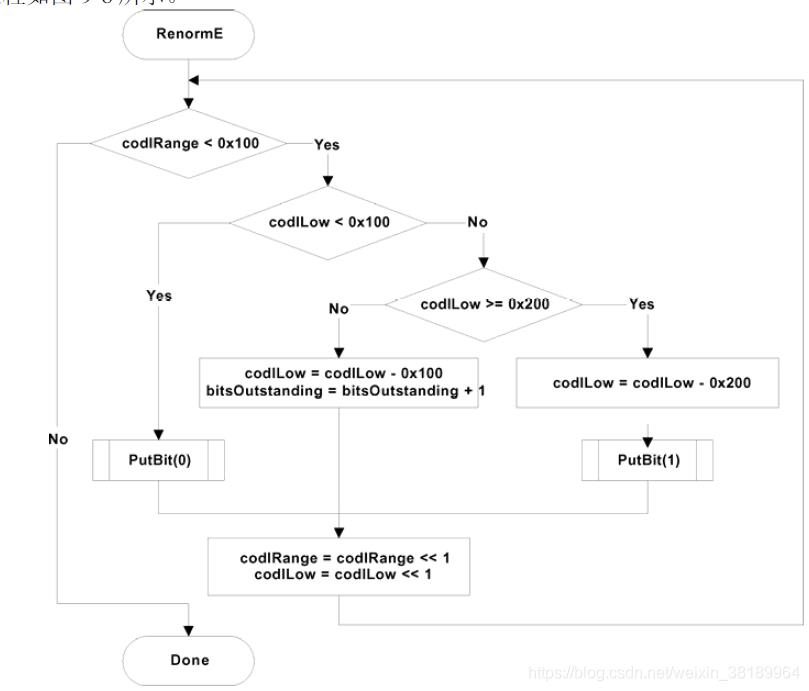
解码部分:
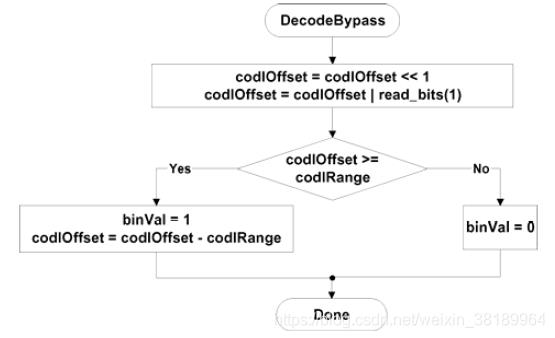
五、码流输出
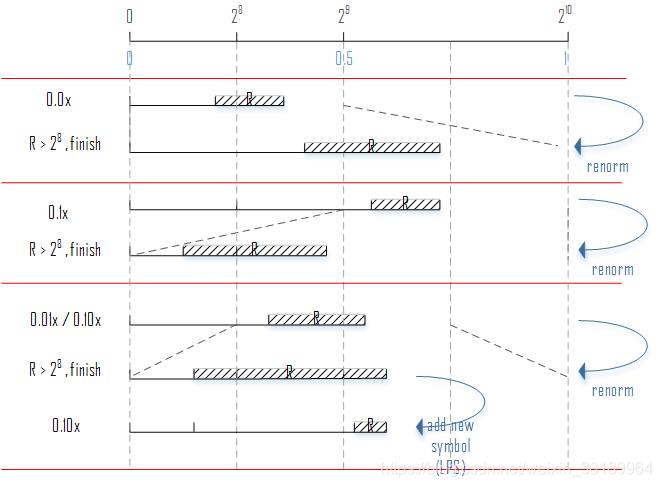
由上图的编码过程可知,随着编码位数的增加,靠前的位的数的值被逐渐的确定下来。举个例子来说就是:如果确定了R处于区间[0.010,0.011),那么0.01就是已确定部分,后来输入的符号无法修改到这部分。随着编码更多的符号,输出的bit会增多,也就是已确定部分会越来越多,越来越接近算术编码的最终结果。但是在编码完最后一个符号之后,剩下的未确定部分该怎么确定?
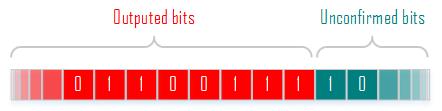
这部分目前还未搞清楚
以上是关于H264熵编码之CABAC的主要内容,如果未能解决你的问题,请参考以下文章