LeetCode9月 每日一题
Posted woodwhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeetCode9月 每日一题相关的知识,希望对你有一定的参考价值。
【LeetCode】9月 每日一题
9.1
题目
思路
模拟即可
代码
function finalPrices(prices: number[]): number[]
let len: number = prices.length
let res: number[] = new Array(len)
for (let i = 0; i < len - 1; i++)
let discount: number = 0
let price: number = prices[i]
for (let j = i + 1; j < len; j++)
if (price >= prices[j])
discount =prices[j]
break
res[i] = price - discount
res[len - 1] = prices[len - 1]
return res
9.2
题目
思路
dfs即可,但是是在dfs的过程中找到最大值,dfs的返回值是左右选择后的最长路径,最终需要返回的结果是左右所有的路径加起来
代码
/**
* Definition for a binary tree node.
* class TreeNode
* val: number
* left: TreeNode | null
* right: TreeNode | null
* constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null)
* this.val = (val===undefined ? 0 : val)
* this.left = (left===undefined ? null : left)
* this.right = (right===undefined ? null : right)
*
*
*/
function longestUnivaluePath(root: TreeNode | null): number
let res = 0
const find = (node: TreeNode) =>
if (node == null) return 0
let l = find(node.left), r = find(node.right)
let al = 0, ar = 0
if (node.left && node.left.val == node.val) al = l + 1
if (node.right && node.right.val == node.val) ar = r + 1
res = Math.max(res, al + ar)
return Math.max(al, ar)
find(root)
return res
9.3
题目
思路
dp思想,先排序,按照头一个元素升序,如果头一个元素相同,就按照后一个减去前一个的顺序
然后就是dp[i]表示0到1的最长数对链的长度
每次遍历选取当前遍历坐标前面的最长的长度,如果当前这个可以加入链中,dp[i]+1
代码
function findLongestChain(pairs: number[][]): number
let len = pairs.length
if (len == 1) return 1
pairs.sort((a,b) => a[0] == b[0] ? b[1] - a[0] : a[0] - b[0])
let dp = new Array(len).fill(0)
dp[0] = 1
let res = -Infinity
for (let i = 1; i < len; i++)
let tmp = 0
for (let j = 0; j < i; j++)
if (pairs[i][0] > pairs[j][1] && pairs[i][1] > pairs[j][1])
tmp = Math.max(dp[j], tmp)
dp[i] = tmp + 1
res = Math.max(res, dp[i])
return res
9.4
题目
思路
暴力梭哈遍历
代码
function numSpecial(mat: number[][]): number
const rows: number = mat.length
const cols: number = mat[0].length
let res: number = 0
const isSpecial: Function = (x: number, y: number): boolean =>
if (mat[x][y] == 0) return false
for (let col = 0; col < cols; col++)
if (col == y) continue
if (mat[x][col] != 0) return false
for (let row = 0; row < rows; row++)
if (row == x) continue
if (mat[row][y] != 0) return false
return true
for (let i = 0; i < rows; i++)
for (let j = 0; j < cols; j++)
if (isSpecial(i, j)) res++
return res
9.5
题目
思路
众所周知我不会dfs,只能用bfs混混日子这样子(主要是脑容量太小了无法用程序的逻辑在脑子里模拟一个个stack,只能用que的空间换脑容量
这题其实思路很简单,hash+serialization,记录每次序列化后的结果,比较是否出现过,出现过就加入最后的返回结果中
但是因为我是使用bfs,第一次直接malloc空间不足了,给我整不会了
后来想明白了,bfs必然过不了,向左右扩展肯定是会挂的,因为每次都会重复计算大量相同的数据
还是得回归dfs,挖到最deep的一层,从下向上serialization,这样就不会重复计算,下方计算好的结果str可以交给上方重复利用
代码
第一版wa的bfs代码,内存不够用
/**
* Definition for a binary tree node.
* class TreeNode
* val: number
* left: TreeNode | null
* right: TreeNode | null
* constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null)
* this.val = (val===undefined ? 0 : val)
* this.left = (left===undefined ? null : left)
* this.right = (right===undefined ? null : right)
*
*
*/
type Tree = TreeNode | null
function findDuplicateSubtrees(root: TreeNode | null): Array<TreeNode | null>
// 前序遍历进行序列化
const frontOrder = (node: TreeNode) =>
let res: string = ""
let stack: Tree[] = [node]
while (stack.length)
let cur: Tree = stack.pop()
if (cur == null) res += "#"
else res += cur.val
res += ','
if (cur != null)
stack.push(cur.right)
stack.push(cur.left)
return res
let stack: Tree[] = [root]
let map: Map<string, number> = new Map()
let res: Tree[] = []
// 前序遍历对比序列化结果
while (stack.length)
let node: Tree = stack.pop()
let serial = frontOrder(node)
// console.log(set, serial)
if (map.get(serial) == undefined)
map.set(serial, 1)
else if (map.get(serial) == 1) // 出现过一次就加入结果
res.push(node)
map.set(serial, map.get(serial) + 1)
else
map.set(serial, map.get(serial) + 1)
if (node.right) stack.push(node.right)
if (node.left) stack.push(node.left)
return res
执行执行几个运行示例是完全没压力的,看了一眼数据范围,10的四次方,必然超内存
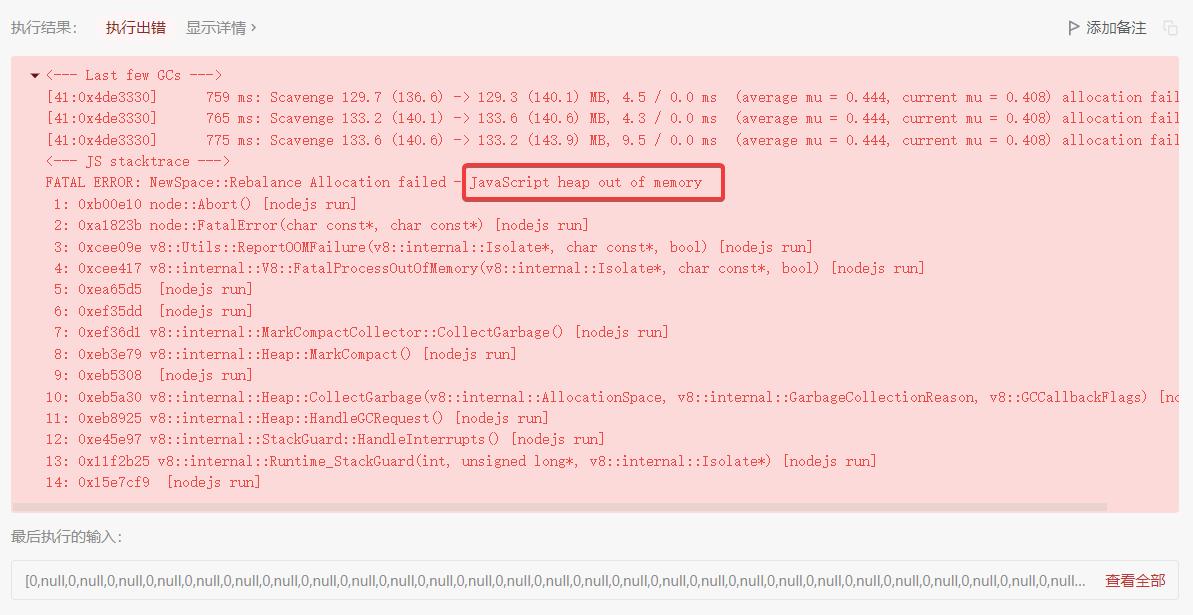
于是使用dfs的版本来了
/**
* Definition for a binary tree node.
* class TreeNode
* val: number
* left: TreeNode | null
* right: TreeNode | null
* constructor(val?: number, left?: TreeNode | null, right?: TreeNode | null)
* this.val = (val===undefined ? 0 : val)
* this.left = (left===undefined ? null : left)
* this.right = (right===undefined ? null : right)
*
*
*/
type Tree = TreeNode | null
function findDuplicateSubtrees(root: TreeNode | null): Array<TreeNode | null>
const map: Map<string, number> = new Map() // 记录出现的序列化的结果的次数
const res: Tree[] = []
const frontOrder = (node: Tree) =>
if (node == null) return "#"
let serializtion = node.val + "," + frontOrder(node.left) + "," +frontOrder(node.right)
if (map.get(serializtion) == undefined)
map.set(serializtion, 1)
else if (map.get(serializtion) == 1)
res.push(node)
map.set(serializtion, 2)
else
map.set(serializtion, map.get(serializtion) + 1)
return serializtion
frontOrder(root)
return res
这题真的思路一下子打开了,以前总以为dfs和bfs在实际应用可以互相转换,但似乎这题不用dfs真滴很难使用bfs来进行树的向下模拟

顺带一提,使用c++版本的dfs还是可以勉强过的,估计是语言特性,typescript这种封装类型的语言就是比不过原生类型的,为了这题我甚至专门写了一个题解
9.6
题目
思路
典中典奥数题,还是得看题解
对每一个字符i,向前找到相同的字符j,向后找到相同的字符k。当前字符对最终结果的贡献是:(i-j)*(k-i)。
这相当于两种方案的拼接:在字符串A(j到i)当中,字符i贡献的次数是(i-j)次。在字符串B(k-i)当中,字符i贡献的次数是(k-i)。那么当两者拼接的时候,字符i对子串(j到k)的贡献就是两种方案的乘积(符合乘法公式)。
遍历两次,分别得到每个字符最左边出现和最右边出现的位置,结果两个距离相乘
代码
function uniqueLetterString(s: string): number
const len: number = s.length
const l: number[] = new Array(len)
const r: number[] = new Array(len)
const cnts: number[] = new Array(26).fill(-1)
for (let i = 0; i < len; i++)
let tmp: number = s[i].charCodeAt(0) - 'A'.charCodeAt(0)
l[i] = cnts[tmp]
cnts[tmp] = i
cnts.fill(len)
for (let i = len - 1; i >= 0; i--)
let tmp: number = s[i].charCodeAt(0) - 'A'.charCodeAt(0)
r[i] = cnts[tmp]
cnts[tmp] = i
let res: number = 0
for (let i = 0; i < len; i++)
console.log(l[i], i, r[i])
res += (i - l[i]) * (r[i] - i)
return res
9.7
题目
思路
纯纯的模拟,有啥好思路
好思路就是我用python
代码
class Solution:
def reorderSpaces(self, text: str) -> str:
space_cnt = 0
words = []
word = ''
for i in range(len(text)):
if text[i] == ' ':
space_cnt += 1
if word != '':
words.append(word)
word = ''
else:
word += text[i]
if i == len(text) - 1 and word != '':
words.append(word)
words_cnt = len(words)
if (words_cnt == 1):
return words[0] + " " * space_cnt
average_spaec_cnt = space_cnt // (words_cnt - 1)
ramain_space_cnt = space_cnt % (words_cnt - 1)
res = (" " * average_spaec_cnt).join(words) + " " * ramain_space_cnt
return res
9.8
题目
思路
由于最近回溯写得多,以看这种题目又以为是回溯,直接全排列的dfs+剪枝,以看数据范围1e4,直接wa
最后还是得去找规律
当n = 50, k = 20时: [1,21,2,20,3,19,4,18,5,17,6,16,7,15,8,14,9,13,10,12,11,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50] 当n = 50,k = 17时: [1,18,2,17,3,16,4,15,5,14,6,13,7,12,8,11,9,10,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50] 当n = 80,k = 30时: [1,31,2,30,3,29,4,28,5,27,6,26,7,25,8,24,9,23,10,22,11,21,12,20,13,19,14,18,15,17,16,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80] 是不是发现了规律,就是 下标从[0, k]中,偶数下标填充[1,2,3…],奇数下标填充[k + 1, k, k - 1…],后面[k + 1, n - 1]都是顺序填充
代码
失败的dfs
function constructArray(n: number, k: number): number[]
// n个数
const used = new Array(n+1).fill(false)
used[0] = true
let res: number[]
const set: Set<number> = new Set()
const dfs = (num: number, arr: number[]) =>
if (num > n && set.size == k+1 && arr.length == n)
console.log(arr, set, num)
res = [...arr]
return true
for (let i = 1; i <= n; i++)
const sub = Math.abs(arr[arr.length - 1] - i)
if (!used[i])
set.add(sub)
used[i] = true
arr.push(i)
if (dfs(i+1, arr)) return true
set.delete(sub)
used[i] = false
arr.pop()
return false
dfs(1, [])
return res
找规律
function constructArray(n: number, k: number): number[]
const res: number[] = new Array(n)
let tmp: number = 1, retmp:以上是关于LeetCode9月 每日一题的主要内容,如果未能解决你的问题,请参考以下文章