MySQL从入门到精通高级篇(二十四)EXPLAIN中select_type,partition,type,key,key_len字段的剖析
Posted 码农飞哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL从入门到精通高级篇(二十四)EXPLAIN中select_type,partition,type,key,key_len字段的剖析相关的知识,希望对你有一定的参考价值。
您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 5. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
文章目录
1. 简介
上一篇文章我们介绍了【MySQL从入门到精通】【高级篇】(二十三)EXPLAIN的概述与table,id字段的剖析,重点对EXPLAIN命令进行了阐述,并且对table,id字段进行了剖析。这篇文章接着对EXPLAIN命令的其余字段进行解析,本文将介绍select_type,partition,type,key,key_len 字段的含义。其中:读者朋友们需要重点掌握 select_type,type 两个字段的含义。
2. 测试的表和数据

详细的测试表创建以及插入测试数据,请参见:【MySQL从入门到精通】【高级篇】(二十三)EXPLAIN的概述与table,id字段的剖析
3. select_type
一条大的查询语句里面可以包含若干个SELECT 关键字,每个SELECT关键字代表着一个小的查询语句, 而每个SELECT 关键字的FROM子句中都可以包含若干张表(这些表用来做连接查询),每一张表都对应着执行计划输出中的一条记录,对于在同一个SELECT关键字中的表来说,它们的id值是相同的。
mysql为每一个SELECT关键字代表的小查询都定义了一个称之为select_type的属性,意思是我们只要知道了某个小查询的select_type属性,就知道了这个小查询在整个大查询中扮演了一个什么角色, 我们看一下select_type都能取得哪些值,请看官方文档:
| 名称 | 描述 |
|---|---|
| SIMPLE | 简单的查询(没有使用UNION 或者子查询(subqueries)) |
| PRIMARY | 主键查询 |
| UNION | 在UNION中第二个或者更后面的查询语句 |
| UNION RESULT | UNION的结果 |
| SUBQUERY | 子查询中的第一个查询 |
| DEPENDENT SUBQUERY | 子查询中第一个查询,依赖外部查询 |
| DEPENDENT UNION | 在UNION中第二个或者更后面的查询语句,依赖外部查询 |
| DERIVED | 驱动表 |
| MATERIALIZED | Mateerialized 子查询 |
| UNCACHEABLE SUBQUERY | 子查询的结果不能被缓存,必须被用于外部查询的计算 |
| UNCACHEABLE UNION | UNION的第二个或者更后面的查询,数据不能被缓存 |
3.1. 连接查询也算是SIMPLE类型
EXPLAIN SELECT * FROM s1 INNER JOIN s2;

3.2. 包含UNION或者UNION ALL的情况
对于包含UNION或者UNION ALL 或者子查询的大查询来说,它是由几个小查询组成的,其中最左边的查询的select_type 值就是 PRIMARY
对于包含 UNION或者UNION ALL 的大查询来说,它是由几个小查询组成的,其中除了最左边的那个小查询以外,其余的小查询的 select_type值就是UNION
MySQL选择使用临时表来完成UNION查询的去重工作,针对该临时表的查询的select_type就是 UNION RESULT
EXPLAIN SELECT * FROM s1 UNION SELECT * FROM s2;

如果是UNION ALL 连接的话则不需要通过临时表来去重
EXPLAIN SELECT * FROM s1 UNION ALL SELECT * FROM s2;

3.3. 子查询
如果包含子查询的查询语句不能够转为对应的semi-join的形式,并且该子查询是不相关子查询。该子查询的第一个SELECT 关键字代表的那个查询的 select_type 就是SUBQUERY。
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2) OR key3='a';
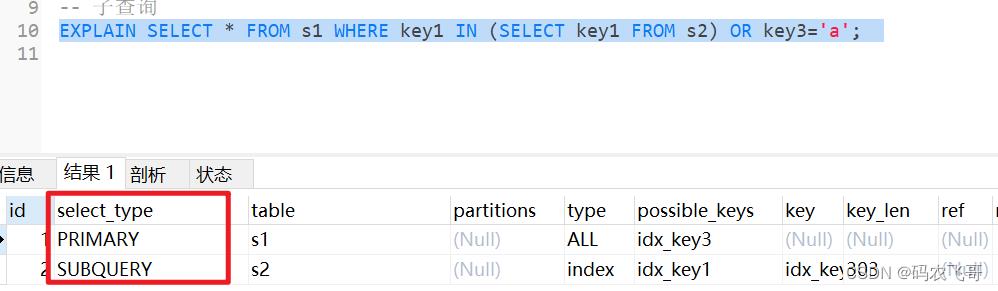
如果包含子查询的查询语句不能欧转为对应的semi-join 的形式,并且该子查询是相关子查询,则该子查询的第一个 SELECT 关键字代表的那个查询的select_type 就是DEPENDENT SUBQUERY。
EXPLAIN SELECT * FROM s1 WHERE key1 IN(SELECT key1 FROM s2 WHERE s1.key1=s2.key2) OR key3='a';

需要注意的是,select_type为DEPENDENT SUBQUERY的查询可能会被执行多次。
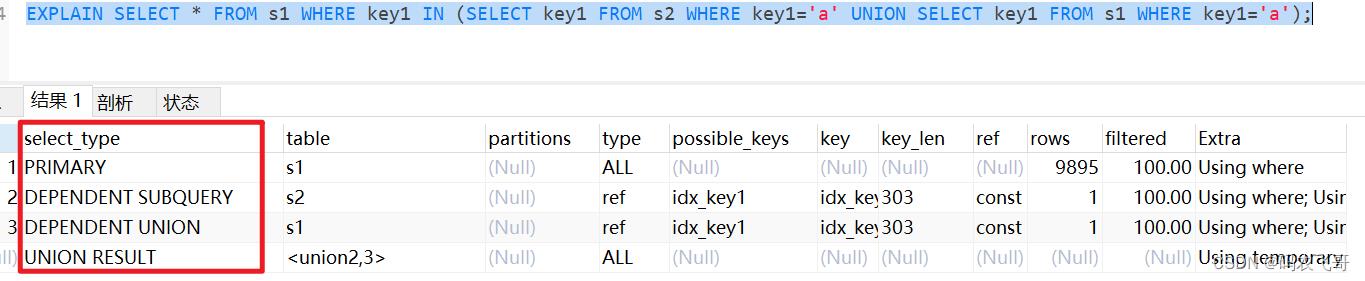
在包含 UNION或者UNION ALL 的大查询中,如果各个小查询都依赖于外层查询的话,那除了最左边的那个小查询之外,其余的小查询的select_type 的值就是DEPENDENT UNION。
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2 WHERE key1='a' UNION SELECT key1 FROM s1 WHERE key1='a');
对于包含派生表的查询,该派生表对应的子查询的select_type 就是DERIVED
EXPLAIN SELECT * FROM (SELECT key1,COUNT(*) AS c FROM s1 GROUP BY key1) AS derived_s1 WHERE c>1;

当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,该子查询对应的select_type 属性就是MATERIALIZED
EXPLAIN SELECT * FROM s1 WHERE key1 IN (SELECT key1 FROM s2);
子查询被转化为了物化表。

4. partitions
partitions 代表分区表中的命中情况,非分区表,该项为NULL,一般情况下我们的查询语句的执行计划的partitions的列的值都是NULL。 该部分不重要,可以省略
5. type (非常重要)
执行计划的一条记录就代表着MySQL对某个表的执行查询时的访问方法,又称"访问类型",其中type列就表明了这个访问方法是啥,是较为重要的一个指标。比如,看到type列的值是ref,表明MySQL即将使用ref访问方法来执行对s1表的查询。
完整的访问方法如下:system,const,eq_ref,ref,fulltext,ref_or_null,index_merge,unique_subquery,index_subquery,range,index,ALL
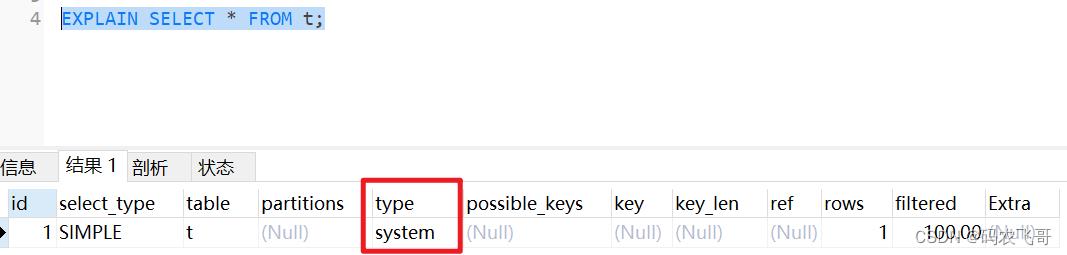
5.1. system
当表中只有一条记录 并且该表使用的存储引擎的统计数据是精确的,比如MyISAM、Memory、那么对该表的访问方法就是system。比方说我们新建一个MyISAM表,并为其插入一条记录。
CREATE TABLE t(i int) ENGINE=MyISAM;
INSERT INTO t VALUES(1);

EXPLAIN SELECT * FROM t;
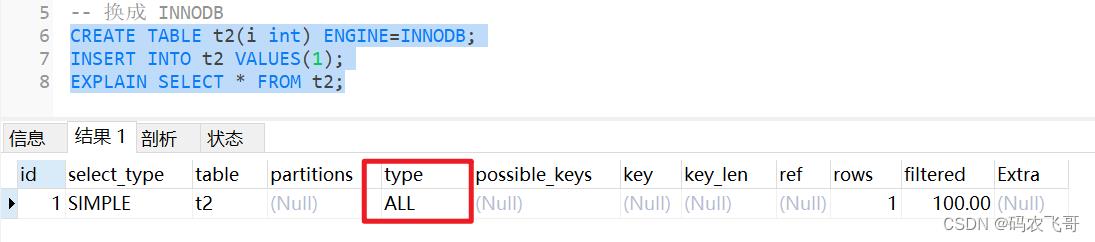
CREATE TABLE t2(i int) ENGINE=INNODB;
INSERT INTO t2 VALUES(1);
EXPLAIN SELECT * FROM t2;
5.2. const
const 表示通过索引一次就找到,const用于比较primary key或者unique索引,因为只需匹配一行数据,所以很快,如果将主键置于where列表中,mysql就能将该查询转换为一个const。
当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const。
EXPLAIN SELECT * FROM s1 WHERE id=10005;

5.3. eq_ref
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或者唯一索引扫描。
在连接查询时,如果被驱动表是通过主键或者唯一二级索引列等值匹配的方式进行访问的(如果该主键或者唯一二级索引是联合索引的话,所有的索引列都必须进行等值比较),则对该被驱动表的访问方法就是eq_ref。
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id=s2.id;

注意:ALL全表扫描的表是记录最少的表,如s1表。
5.4. ref
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而它可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体。
EXPLAIN SELECT * FROM s1 WHERE key1='a';

5.5. ref_or_null
当对普通二级索引进行等值匹配查询,该索引列的type值就可能是ref_or_null。
EXPLAIN SELECT * FROM s1 WHERE key1='a' OR key1 is NULL;

5.6. index_merge
index_merge 表示在单表访问方法时在某些场景下可以使用Intersection、union、sort-union 这三种索引合并的方式来执行查询
EXPLAIN SELECT * FROM s1 WHERE key1='a' OR key3='a';

5.7. unique_subquery
unique_subquery 是针对在一些包含IN子查询的查询语句中,如果查询优化器决定将IN子查询转换为EXISTS 子查询,而且子查询可以使用到主键进行等值匹配的话,那么该子查询执行计划的type列的值就是 unique_subquery
EXPLAIN SELECT * FROM s1 WHERE key2 IN (SELECT id FROM s2 WHERE s1.key1=s2.key1) OR key3='a';

5.8. range
只检索给定范围的行,使用一个索引来选择行,key列显示使用了那个索引。一般就是在where语句中出现了 between、<、>、in等的查询。这种索引上的范围扫描比全表扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引。
EXPLAIN SELECT * FROM s1 WHERE key1 IN('a','b','c');
同上
EXPLAIN SELECT * FROM s1 WHERE key1>'a' AND key2<'b';

5.9. index
Full index Scan,index与ALL区别为index类型只遍历索引树。这通常为ALL块,应为索引文件通常比数据文件小。(Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取)
EXPLAIN SELECT key_part2 FROM s1 WHERE key_part3='a';

5.10 ALL (全表扫描)
ALL: Full Table Scan,遍历全表以找到匹配的行
EXPLAIN SELECT * FROM s1;

5.11 小结
type(访问类型)是sql查询优化中一个很重要的指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
其中比较重要的几个做了加粗处理,SQL性能优化的目标:至少要达到range级别,要求是ref级别,最好是const级别(阿里巴巴开发手册要求)
6. possible_keys和key
在EXPLAIN语句输出的执行计划中,possible_keys 列表示在某个查询语句中,对某个表执行单表查询时可能用到的索引有哪些。如果为NULL,则没有使用索引,比方说下边这个查询:
EXPLAIN SELECT * FROM s1 WHERE key1>'z' AND key3='a';

这里可能使用到的索引有 idx_key1和idx_key3,但是实际使用到索引是 idx_key3。
7. key_len
实际使用到的索引长度(即:字节数)
帮你检查是否充分的利用上了索引,值越大越好,主要针对联合索引,有一定的参考意义。
EXPLAIN SELECT * FROM s1 WHERE id=10005;

这里int本身占4个字节。
EXPLAIN SELECT * FROM s1 WHERE key2=10126;

这里key2是int类型,本身占用4个字节,并且其还被设置了一个唯一索引,占用一个非空字节,所以是5个字节。
EXPLAIN SELECT * FROM s1 WHERE key1='a';

这里key1的长度是100,而在utf-8中一个字符占用3个字节,那么就是1003,key1有可能是空的情况,那么就需要+1,并且varchar是变长的类型,所以,还需要两个字节去记录实际长度是多少,那么就是 1003+1+2=303。
7.1. 针对联合索引的情况
EXPLAIN SELECT * FROM s1 WHERE key_part1='a';
EXPLAIN SELECT * FROM s1 WHERE key_part1='a' and key_part2='b';


这里的两个查询都使用到了 idx_key_part索引,该索引是一个联合索引,而下面的查询语句的key_len比上面的查询语句的key_len要大。所以,下面的查询效果要比上面的查询效果要好。
总结
本文详细介绍了EXPLAIN中select_type,partition,type,key,key_len字段。
以上是关于MySQL从入门到精通高级篇(二十四)EXPLAIN中select_type,partition,type,key,key_len字段的剖析的主要内容,如果未能解决你的问题,请参考以下文章