高性能零售IT系统的建设01-一场HTTP组件引发的血灾
Posted TGITCIC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高性能零售IT系统的建设01-一场HTTP组件引发的血灾相关的知识,希望对你有一定的参考价值。
从问题的表象来看问题是怎么发生的
我们的系统大约在上线后2个月内,我们发觉我们的前端小程序即TO C端的商品目录这一块,经常会有用户在点一下“分类”进入后在显示相应的分类项时右边的具体商品列表会时不时卡一下,卡个大概1秒-2秒左右。它还经常发生。
另外就是,我们有TO B端即运营管理端,它的访问来自于通过公司内网访问。我们的系统有上游主数据也有下游相应的仓库、财务、发票等系统。由于这些系统为Legacy因此大部分-约90%为跑批而并非real time的交易。然后以触发式MQ的方式,收到一条消息就会有一条主数据下行中台或者是中台下行仓库的调用。而在这种调用时,前端小程序也会莫明卡个几十秒。
虽然它没有构成特别严重的问题,但是给人感觉特别的难受。另外在我了解下来,TO B端这一侧经常会出现time out的error日志。不过好在90%以上的TO B端操作有on error retry机制。但是当这个现象越来越多、越来越频繁时特别的烦人。
我们的系统它在我接手前你们可以认为这是一座“屎山”,一座拥有600万行代码的“屎山”。我不知道有人遇到过“屎山”,就算遇到过但是可能真的稀少有像我这样遇到的是一座喜马拉雅这么高大的“屎山”。
我一般对于生产问题会做这样的记录和整理:
- 有一次生产问题,我们会当成incident即bug;
- 而同样的问题产生>=3次,我会把它归为defects;
BUG我平时一般很少会去细看,但是我有每天花5分钟快速扫几眼生产BUG的习惯。我对生产BUG的要求是“D+1天清零”,那么当发觉这样的BUG已经被报了三次了,它立刻引起了我的重视。
于是我开始对这个问题进行了分析。
发现问题
问题的描述就像我上面所述,它具有一个很好玩的通性。TO B端操作一下就会引起TO C端的卡。或者TO C端那些模块如果不是采用的是RPC或者是spring的微服务而是HttpClient访问请求时就会发生这种现象。
要知道我拿接手的是一个己有600万行代码的项目的框子上改出来的东西,它光本身基础模块达34个,还有企业内部一堆的legacy system相关连,而API连接点更是高达上万处。
这不是一般的项目可以想像得到的也不是一个系统对接另一个系统这种单对单的“普通”对接。
它是一个网、超大的蜘蛛网!千丝万缕!
因此,这个系统注定它里面的相应的一条条技术栈非单一技术而论。
因此,在系统中会存在这么几种连接:
- 模块间用MQ通讯
- 模块间用标准微服务通讯,这个量大约在85%
- 系统(中台)和上下游legacy间用http连接,大约在10%
- 系统间使用跑批文件交互,5%
所以我们从总的架构图(好在“屎山”上线前我绘制有总架构图,从南北、东西、模块、系统间交互用的是什么方式都完整的绘制出来了)上对应着三次生产上发生的问题来看,找到了第3个点。
在当时,我们还没有上全链路跟踪APM,只有靠日志、GLOWROOT和Grafna来排查。而这种问题它不会表现在表面。在表面可以找到的证据,就只有可以找到elk日志里有相应的connection time out这种字眼和相应的代码位置。
那么我把这些日志挑出来,找到相应的代码再去排查,才发觉了以下这么几个好玩的现象。
- 乱用http 调用,比如说:我原先有一个http调用叫getUserById,入参是一个userid,于是先有这个框架的原设计者把这个http调用封装成了一个service方法,然后在需要取1万个user时一个for循环,对着这个getUserById调个1万次;
- 还是原设计者,它觉得模块化、要封装,因此一切跨模块的操作都是http请求,一个数据库delete语句封一个http、一个数据库add语句封一个http,到处是http调用;
- 最悲惨的事是第3点,在几十个模块中存在着18个不同的HttpUtil封装工具helper类,而这些helper类再分成两种:
- 使用CloseableHttpConnecton Pool
- 直接使用HttpClient
各位要知道,这个庞大的项目它不是一切从0行代码开始写起的,它至少有一个框子。我们知道程序员最喜欢的就是推倒从来,可是最考验人的却是“治理屎山”。
那么我现在手上的就是这座“屎山”,特别是上面的第3点,由于这个框子的升级是经过了3年多,因此它里面用到的http client的helper类还不是spring托管的,也不是restTemplate。而是纯编码书写的http client啊。
- 在代码里声明了CloseableHttpConnection Pool,一次请求过来调用就new 这么一个connection pool出来;
- 直接使用HttpClient的呢,没有finally块,有的在try里close,有的在catch里close,有的一条close也没;
然后呢,结合着3个好玩的现象,在系统运行时,整个架构内的http connection由如下图所示:
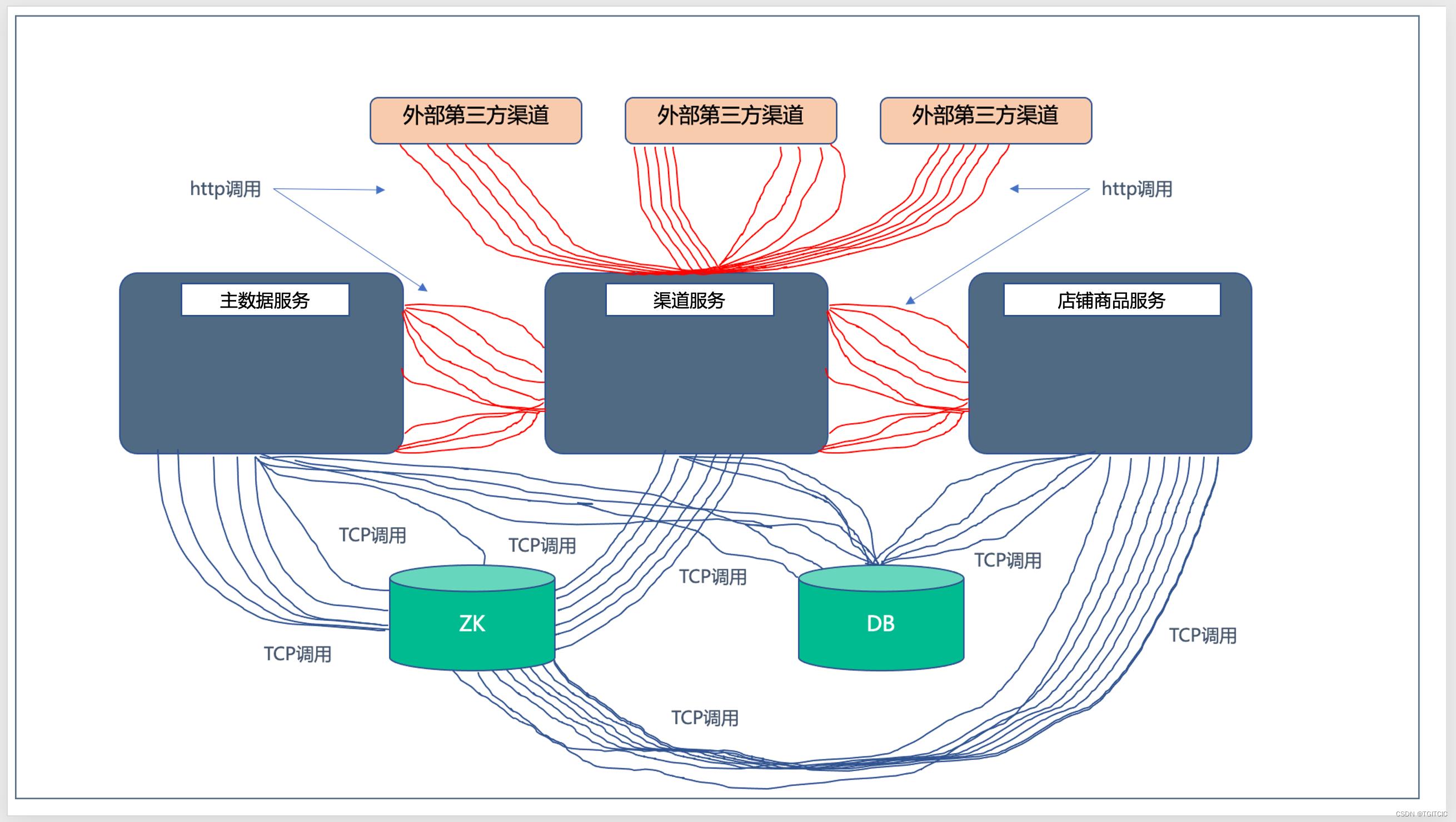
整个系统里随时伴随着7位数的Http连接风暴。
而解决问题没有这么简单
发生了这种问题就是改呗?但实际问题没有这么简单。
我前文在:家乐福618保卫战二-零售O2O场景中的万级并发交易情况下的极限性能调优中提到过,我们这个是生产环境,生产环境有业务在运行和严格的业务排期计划。
你要动排期计划,这可是要了业务的命了。你不动,那么最终因为当这个系统外部的请求越来越多时,早则一个月慢则三个月你还是会没命。
因此为了说服业务型领导,你给他看代码吗?他也不需要看或者他找到的相应的咨询者怀有着自己的一些目的也会给你把话题给说偏了。比如说来一句:你不用手动去关的,spring啊,spring里一切都会自动关闭。
然后这时你为了和他争论你们要开始翻spring 源码和http client源码来比对和说明这个问题。这么简单的问题马上会沦落成bla bla bla。然后业务领导就烦了,就不会听你的了,也不让你动手去改这个技术认为特别严重的问题而在业务听不懂的问题了。
真的,有时技术干活真就这么难。
这怎么办呢?现在摆在我面前有两个困难
- 这些点,我共计发现了2,000多处,涉及到18个模块,而且我重构时一定会动到原有的业务层逻辑,光回归测试就得2-3个月,不亚于一次全量上线的3分之1工作量;
- 业务功能的确紧锣密鼓的排期排在那,而且一点都动不得,那些业务功能都是渠道接入、新渠道订单、新业务模式,那可是一个个真金白银来钱的功能啊?
换成一般的技术,此时“心累”了,要走了!
唉。。。说实话我确实心累,累在很难说服业务型领导。但这个事我知道是必须去做的,怎么做呢?
我采用了以下几招。
以客观事实为依据认识问题、以聪明的项目实施去推进技术类优化
首先,我们使用grafna,抓这些出问题的功能模块上的linux里的文件打开数。我们知道http的底层归根到底还是tcp连接,而一条tcp被打开它就会创建一个linux里的file open句柄。
我们假设这个file open没有被用完后close而再开、再开、不断的开,它会发生什么?linux里的文件打开数很快就会都被搞“爆”,linux的文件打开数被搞爆后会发生什么?运维和devops人员连远程sftp管理工具都连不上。
因此,我们做了一件这样的事:
- 直接用准生产环境模拟上下游和中台,连续的做了300条订单的从上到中、从中到下的流转,然后用远程sftp连接订单、主数据、商户三个模块所属的若干台linux。各位知道,linux里的最大打开文件数默认是1024,而这个数是可以设的,那么我们把它设到了655,350,其实这也是一刀切不合理,原则上65,535就够用了。而我们设了一个655,350。然后做了300条订单流转。那么按照上面问题的描述各位也可以知道,订单绑user、绑主数据、绑店铺,一个迪卡尔积下来多少?我们的用户是刚开始可能只有几十万吧。好家伙,300个订单在后台产生了6位数的http。此时我们不操作,让DEVOPS和运维人员去操作,他们发觉远程的这些服务器统统在300条订单下行后就已经连不上了。我告诉你们呀,这个就搞大了!你们知道为什么?任何项目初期,业务领导不是太看得上软件资产和人员,它对硬件资产却特别看重,因为那是有型的。。。而现在你告诉他,这个问题导致你硬件(尽管在云上的vm或者是k8s)都不能维护了,这不搞大了?
- 于是,此时业务领导惊讶的并且有了耐心,他坐了下来开始听你说这个问题的严重性了。此时如果你告诉他上面我写的这一堆BLA,我估计他能听5分钟就已经算你lucky了。业务领导要听什么?听结果为导向。因此呢我直接告诉他我准备这么来改这件事;
聪明的改进手法
问题最严重的点在于TO B端那几个连接legacy时的操作,由于都是MQ触发式或者是XXLJOB频率跑批类的,因此这些关联操作它们涉及到的http connection的梗特别严重,而且在白天必现。而有一些呢在晚上才出现的呢?可以先按照优先级往后放。
要知道,2,000多个点有这样的问题,动到了3分之1以上的原功能模块和业务逻辑啊?这不是15天,1个月可以搞得定的事。
因此按照:
- 影响最大、必现的,排成一期,并且在一期里按照手上正在进行的3个大的CR里程碑划成S101集、S102集、S103集;
- 只有在晚上跑批相关的理出来,排成二期;
- 积累成血的教训即-case study然后开发们自查,查到一个开成一个jira task,把这些task聚焦在一起排成三期;
那么业务领导就会来问了:这三期,总计达近3个月,我的业务功能要delay吗?
我告诉他:不用不用,一点不用delay,一边上业务功能一边改。
领导:那么你改这个是要全回归啊?这个也需要时间,你说的话不符合logic啊?
于是我告诉他:很简单,我们开发还好人手有,因此在做业务功能开发时顺手把正在开发到的这些功能模块里的http connection乱用问题撸掉。撸掉清掉后,它不是要提测功能单吗?我们看这几次上线里程碑里的业务功能,都要用到订单、主数据、商铺、用户对吧?而这个http connecton属于底层“基建”,基建如果在改动时影响了业务功能、或者是反而改坏了,那么在测试时就会发现问题。因此这对开发叫“顺手撸掉”,因此要纠正这种问题真的不难改,而对测试来说呢正好是带着当前版本“测”掉。
所以我把功能模块就是咬合着业务功能叠代的里程碑去做的折分。
领导又问:我比较关注于第三期就是依靠开发自己发现、梳理和避免下次如何不会再发生一次这样的问题?
于是我做了以下几件事。
改改都是很简单的而难在如何避免同类事的再次发生
其实这件事在我看来是好事,就如我所说,我接手的我认为是一座“屎山”。但我真的有这个信心把它变成一座“金”山。关键不在于发现问题,而在于发现了问题后同样的问题不要再发生,这不属于天天你拿鞭子抽就可以抽得出来的结果,而在于整体团队的一个提升,这是技术管理的核心价值所在,那就是“变废为宝”。
我做了以下这样的事:
- 制作成case study,说清原因、重现手段;
- 写成规范,全员宣导;
- 既然成了规范那么违反者就有惩罚;
我们来看看我们的这方面的规范是什么样的吧,我这边摘录核心的3条内容(其实我们仅仅为http connection的使用上就制定了小20条规范):
- 对于老的功能模块已经用了http client的,需要全局共用一处Http Util,这个Http Util必须在finally块中套一个trycatch块再去close;
- 对于使用的是CloseableHttpConnection的,必须把这个CloseablehttpConnection做成一个全局带双重校验机制的单例,所有业务代码里永远只getConnection而不可以去new;
- 超过50次同业务http接口如: getUserById调用,不得使用for循环去调用http接口,而是要用for循环把50条内容组成一个json array,一次通过新增的http接口送过去;
以上第3点在一开始遭到了不少开发们的抵触,要知道上百人的开发团队,高手有、大部分为中级程序员,还有不少初级和刚毕业的程序员。它们就是我们嘴里的“码农”。以上这样的技术点在于大厂的P5、P6、P7来说简直和1+1=2的问题一样都不需要做任何告知,他们平时的开发习惯就是这样的,而我们要知道99%的企业真的不是大厂,还是以码农为主的开发团队。
于是为了消除这样的抵触,我着重和开发们举了一个例子,为什么很简单的我一个for循环,然后在循环里塞上一个http接口的调用不好呢?这是因为,好比你有一个目录,这个目录里有几十万个几百k大小的jpg或者是txt文件,你用鼠标“拎”着这个目录往百度网盘里一扔,你以为很快就会传完?实际用了4,50分钟。而另一种做法是:我把这个目录连同里面的文件打成一个zip包,它可能有2个G,打成zip包后我把这个zip包然后再往百度网盘里再去做备份上传,那么就算在家里面这种普通用户带宽情况下也只用了两分钟。这就是因为每一个http connection是一条Network IO。系统性能有一条很重要的点就叫:减少Network IO的调用。
看!这么一举例,所有的开发包括刚毕业的新人都领悟了和深刻记下了这件事。
不要觉得这么傻瓜的事还要如此兴事动众值得炫耀
这不是炫耀,上面我说的这个问题放在任何单模块、或者就2-3个系统对接时你会觉得这个改改只是一周的时间。
没错,真的全改了就一周。
你别忘了有回归测试啊。
你说:这个测试快一点也一周,最多两周。
我这样告诉你,这么多改动,你说测试只要一周,业务型领导就会觉得你已经不靠谱了。为什么呢?业务型领导只看有型资产和看得到的东西,对于这些看得到的它觉得投入是值。哪些是看得到的呢:硬件他肯投、测试他肯投因为这个关系质量哈。
关键还有,这个系统有600万行代码,小一半业务功能底层里有一部分被动到了,而且被动到的这一部分是涉及到订单、主数据、用户,那可是零售三大主流程啊!
你敢拍胸脯说:没事?
嘿!
大型团队、上百人开发合作,忌讳的就是拍胸脯。
这件事上其实有这么三个点:
- 如何去说服领导有这个问题(你不可以不说,不说那叫瞒报,因为确实发生了3次了);
- 如何用最有效的方式去优化(其实我也可以七七八八多要个两周的,而我实际的优化对业务功能没有造成1分钟的delay。为什么要说呢?咳。。。其实说是打个招呼作好可能会有delay个1-3天的buffer来准备的,必竟改动点太多了,我也不敢保证会不会真的没改好或者把原有功能改坏了);
- 如何又能让这件事以后彻底避免
因此我采用了以上的手法。
你们看这件事,它属于管理吗?看了又不太像,因为里面是有技术点的。你说它属于技术吗?这里面还有敏捷项目管理、项目折分、沟通演示技巧也不是那么“全技术”;
各位,我以此一例带领各位开始正式入门“架构-而且我传播的一定不只是纯技术架构,而是企业架构”这一理念。
写一些附言(我大厂的同学听了后说的话)
这都什么问题呀,这么简单的这么烂的事。。。根本上就一开始时就可以完全避免这么LOW的事。
我的回答:
等等。。。等等。。。且打住兄弟。。。
任何程序员都喜欢摧毁式的去重构一个系统,而你实际的人生时间里有99%碰到的是接手“屎山”。接手“屎山”真心不怕,屎山完全可以变金山。也不要去怨开发,不是个个企业是大厂,在大厂的程序员都已经讨论到leet code level5, level7了。不是这样的。
超过99%的人手下的团队,都是我在一开始碰到的这一群连http close要放在finally块中也需要着重教育的“猿”们,你把他们都fire了?谁去做事?
把他们培养好、把他们带向“员”、再带向“师”,这才是真正的挑战。
everyone says: I need the good resource, but how about to train your current resource?这是乔帮主说过的话。
结束本篇篇章。
以上是关于高性能零售IT系统的建设01-一场HTTP组件引发的血灾的主要内容,如果未能解决你的问题,请参考以下文章