随机森林的简单学习记录
Posted 小陈皓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了随机森林的简单学习记录相关的知识,希望对你有一定的参考价值。
随机森林小记
这里采用的随机森林的库选择sklearn库
1.首先是导入数据:
path = "D:/1课内学习/神经网络与深度学习/课程设计题目及要求/Epileptic Seizure Classification.csv"
# 针对csv文件
rawdata = pd.read_csv(path)
# 针对xlsx文件
rawdata = pd.read_excel(path)
2.根据数据分布,选出样本的标签和数据,使用函数将他们分开:
使用iloc函数,提出相应的数据
iloc[]函数,属于pandas库,全称为index location,即对数据进行位置索引,从而在数据表中提取出相应的数据。
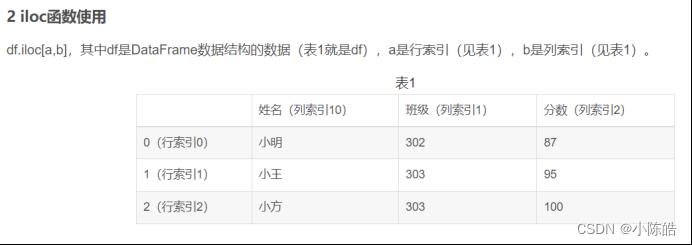
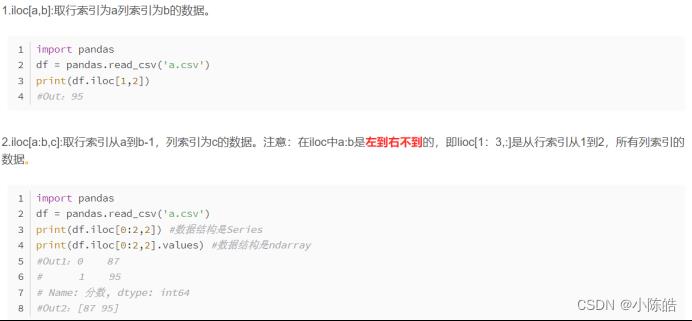
了解了相关函数的用法,就可以将数据进行分开。这里用到的数据为,第一列是对应天数,后面的所有数据时高光谱的数据,所以x为数据,y是对应的天数。
# 得到分类后的数据和标签
X = rawdata.iloc[:,1:]
Y = rawdata.iloc[:,0]
3.得到数据和标签后,就可以将其分为训练集和验证集,套用train_test_split函数
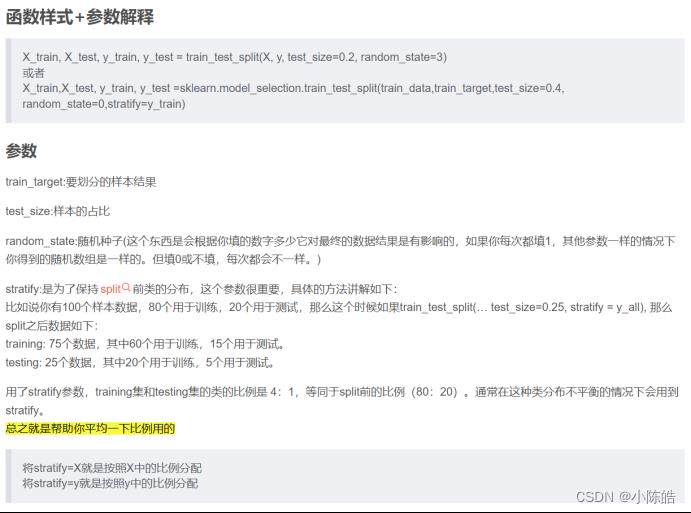
将训练集和验证集按9:1的比例分开:
x_train, x_test, y_train, y_test = train_test_split(X, Y, random_state=1, train_size=0.9,stratify=Y)
4.随机森林主体部分
整个流程是,将分类好的训练集和验证集进行随机森林训练,选择不同的树的个数,输出最后的结果。
def rf_model(k):
return RandomForestClassifier(n_estimators=k*10, criterion="gini",max_features='sqrt')
def svc_model(model):
model.fit(x_train, y_train)
acu_train = model.score(x_train, y_train)
acu_test = model.score(x_test, y_test)
y_pred = model.predict(x_test)
recall = recall_score(y_test, y_pred, average="macro")
return acu_train, acu_test, recall
def run_rf(kmax):
result =
"k": [],
"acu_train": [],
"acu_test": [],
"recall": [],
"time":[]
for i in range(1, kmax + 1):
start_time = time.time()
acu_train, acu_test, recall = svc_model(rf_model(i))
end_time = time.time()
result["k"].append(i)
result["acu_train"].append(acu_train)
result["acu_test"].append(acu_test)
result["recall"].append(recall)
result["time"].append(end_time-start_time)
print(i,result["acu_test"][-1])
return pd.DataFrame(result)
其中RandomForestClassifier函数为随机森林函数主体:

以上是关于随机森林的简单学习记录的主要内容,如果未能解决你的问题,请参考以下文章