redis 技术分享
Posted 香菜聊游戏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis 技术分享相关的知识,希望对你有一定的参考价值。
1、是什么
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
2、应用场景
2.1 特点
Redis 与其他 key - value 缓存产品有以下特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
- Redis支持lua脚本
2.2 redis 为什么这么”快“?
1、完全基于内存,绝大部分请求是纯粹的内存操作。
2、采用单线程,避免了不必要的上下文切换和竞争条件,但同时也无法利用多核的优势。
3、使用多路 I/O 复用模型,实现高吞吐的 IO 操作。
4、数据结构简单,大多数读/写操作为 O(n) 或 O(log(N))。
2.3 应用场景
- 缓存,作为Key-Value形态的内存数据库,Redis 最先会被想到的应用场景便是作为数据缓存
- 分布式锁,分布式环境下对资源加锁
- 分布式共享数据,在多个应用之间共享
- 排行榜,自带排序的数据结构(sorted set)
- 消息队列,pub/sub功能也可以用作发布者 / 订阅者模型的消息

3、技术解析
3.1 技术架构
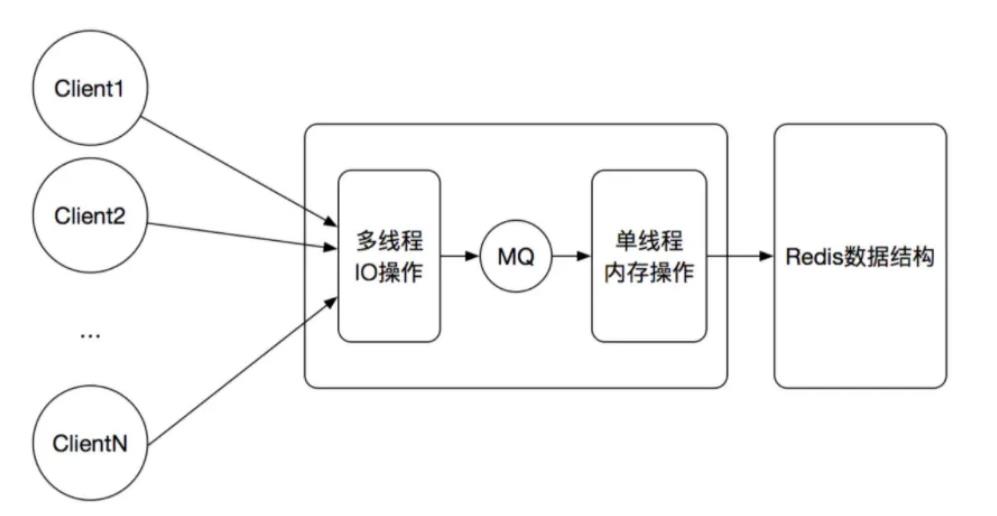 redis 6.x 之前是真正意义上的单线程(处理客户端的连接和执行操作的命令都是由一个线程完成的)。
redis 6.x 之前是真正意义上的单线程(处理客户端的连接和执行操作的命令都是由一个线程完成的)。
redis 6.x 之后引入多线程(处理客户端请求是由专门的线程处理, 执行命令还是单线程)。
3.2 redis的数据类型

3.2.1、String
set key value:设置值 get key:获取值 del key:删除key
strlen key:获取该key值对应的value值的长度
append key "xxx":在该key对应的value值追加上xxx
incr key:该key对应的value自增1 decr key:该key对应的value自减1'
incrby key xx:该key对应的value增加xx decrby key xx:减少xx
getrange key x1 x2: 获取x1-x2范围内的值,类似between...and的关系,从零到负一表示全部
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。常规key-value缓存应用: 常规计数:微博数,粉丝数等
3.2.2、List列表 命令格式 lxxx
所有的list命令都是用l开头的
lpush 集合名 xx:将xx插入到集合头部 rpush:将xx插入到集合尾部
lrange 集合名 x y:获取集合里x-y的值 (0 -1为获取集合中所有的值)
lpop 集合名:移除该集合的左值 rpop:移除该集合的右值
lindex 集合名 x:获取该集合中下标为x的值 llen 集合名:获取集合的长度
lset 集合名 index xx:该集合下标为index的值更新为xx(不能添加)
linsert 集合名 before yy xx:在集合中的yy值前面插入一个xx值
linsert 集合名 after yy xx:在集合中的yy值后插入一个xx值
3.2.3、Set 命令格式 sxxx
set中的值是不能重复的
sadd 集合名 值:向set集合中添加值
smembers 集合名:查看该set集合中所有的值
srem 集合名 值:移除set集合中的某个值
srandmember 集合名:随机取出集合中的一个值
spop 集合名:随机删除一些set集合中的元素
smove set1 set2 "xx":把set1中的xx移动到set2
sdiff set1 set2:差集 sinter set1 set2:交集 sunion set1 set2:并集
3.2.4、Hash 命令格式 hxxx
hset 集合名 key1 value1:给map集合中添加一个或者多个key-value键值对
hget 集合名 key:获取对应的key的value值 hgetall 集合名:获取集合中所有的键值对
hexists 集合名 key:判断该集合中的指定key是否存在 hkeys 集合名:获取集合中所有的key
3.2.5、Zset有序集合命令格式 zxxx
zadd 集合名 scroe值 xx:想集合中增加xx值,排序的时候通过score的值进行排序
zrange 集合名 0 -1:查询集合中所有的值,默认按照score值的升序排列
zrangebyscore 集合名 -inf +inf:按score值升序排列,可以用具体值替换+-inf,例如[-inf,2000]
zrevrangebyscore 集合名 +inf -inf:按照score的值降序排列
zrem 集合名 值:移除该集合中的指定元素 zcard 集合名:获取有序集合中的元素的个数
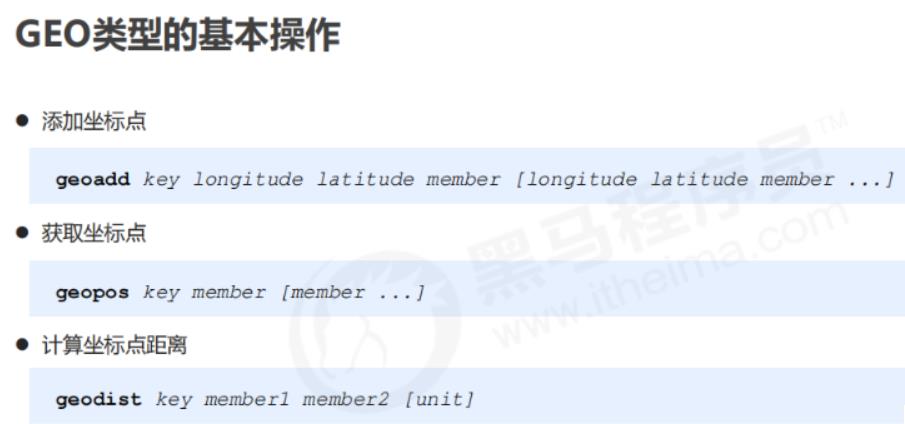
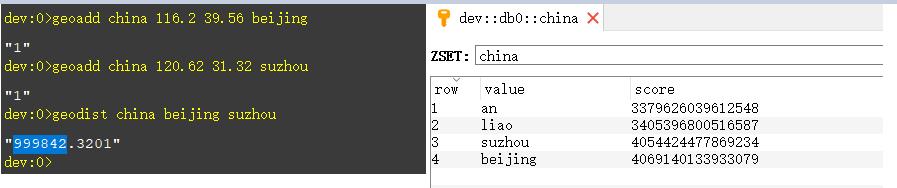
3.2.6、GEO类型 命令格式 geoxxx
将指定的地理空间位置(经度、纬度、名称)添加到指定的 key 中,这些数据将会存储到 sorted set。这样的目的是为了方便使用 GEORADIUS 或者 GEORADIUSBYMEMBER 命令对数据进行半径查询等操作。也就是说,推算地理位置的信息,两地之间的距离,周围方圆的人等等场景都可以用它实现。
4、使用步骤
介绍在程序中的编程步骤,使用方式
spring-boot-data-redis 和 redission
spring-boot-data-redis 默认使用 Lettuce 客户端操作数据。但Reddissin 很强大,它提供的功能远远超出了一个 Redis 客户端的范畴,使用它来替换默认的 Lettuce。在可以使用基本 Redis 功能的同时,也能使用它提供的一些高级服务:
- 远程调用
- 分布式锁
- 分布式对象、容器
常规使用可以使用spring-boot-data-redis,在spring-data下操作一致
有分布式需求的情况下可以使用redission
1)添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2)配置连接
server.port=8088 spring.redis.host=127.0.0.1 #Redis服务器连接端口 spring.redis.port=6379 #Redis服务器连接密码(默认为空) spring.redis.password=123456 #连接池最大连接数(使用负值表示没有限制) spring.redis.pool.max-active=8 #连接池最大阻塞等待时间(使用负值表示没有限制) spring.redis.pool.max-wait=-1 #连接池中的最大空闲连接 spring.redis.pool.max-idle=8 #连接池中的最小空闲连接 spring.redis.pool.min-idle=0 #连接超时时间(毫秒) spring.redis.timeout=30000
3)创建entity
@Data
@AllArgsConstructor
@RedisHash("user")
public class Player
@Id
String name;
int age;
4)创建dao
@Repository
public interface PlayerDao extends CrudRepository<Player, String>
5)调用
@RestController
public class TestController
@Autowired
PlayerDao playerDao;
@GetMapping("/")
public void getTest()
playerDao.save(new Player("ccc",19));
5、常用工具,开发方式
1.说明
Redis Desktop Manager是一款简单快速、跨平台的Redis桌面管理工具,也被称作Redis可视化工具;支持命令控制台操作,以及常用,查询key,rename,delete等操作。
2.安装
1、进入Redis Desktop Manager在git的发行版(免费版)页面 Release 0.9.3 · uglide/RedisDesktopManager · GitHub
新的版本收费
2、点击 redis-desktop-manager-0.9.3.817.exe ,下载
6、经验分享
1) key、value的定义
Key的最佳实践:
-
- 固定格式:[业务名]:[数据名]:[id],会有目录结构
- 不包含特殊字符
- 控制 key 的长度
Value的最佳实践:
-
- 合理的拆分数据,拒绝BigKey
- 选择合适数据结构
- Hash结构的entry数量不要超过1000
- 设置合理的超时时间
2) 缓存雪崩
指缓存中大批量数据到过期时间,同时查询数据量巨大,引起数据库压力过大甚至宕机。与缓存击穿不同的是,缓存击穿是围绕并发查询同一条数据,而缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库,解决方案:
1、设置缓存数据的过期时间随机,防止同一时间内大量数据发生过期。
2、设置热点数据过期时间更长或永久。
3) 缓存击穿
指缓存中没有数据,但数据库中有数据,一般是未做热加载或缓存过期导致,在某一刻由于并发查询同一条数据的请求特别多,读缓存无数据,因此同时去数据库查询数据,引起数据库压力瞬间增大,解决方案:
1、设置热点数据缓存过期时间更长或永久。
2、当查询缓存无数据时,使用互斥锁控制只允许一个线程 A 查询数据库,其余请求线程等待线程 A 加载数据到缓存,如Guava Cache在查询缓存无数据时,只允许一个线程加载。
4) 存储大小限制
String类型:一个String类型的value最大可以存储512M
List类型:list的元素个数最多为2^32-1个,也就是4294967295个。
Set类型:元素个数最多为2^32-1个,也就是4294967295个。
Hash类型:键值对个数最多为2^32-1个,也就是4294967295个。
Sorted set类型:跟Set类型相似。
5) 避免作为消息队列
Redis其实还能够支持消息队列的应用,但其读写效率是不及其他MQ如Kafka、RabbitMQ等。且由于其结构的设置,不太能够支撑
MQ的一些主要特性,所以应当避免使用。
6) 你在使用 Redis 时,要把它当做缓存来使用,而不是数据库。
7) 批量命令代替单个命令
当你需要一次性操作多个 key 时,你应该使用批量命令来处理。
批量操作相比于多次单个操作的优势在于可以显著减少客户端、服务端的来回网络 IO 次数
7、扩展阅读
1)redis 持久化方式哪些?
RDB,全称 Redis Database,在指定的时间间隔内将内存中的数据集以快照的方式写入磁盘,实际操作过程是 fork 一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储,在恢复数据时将快照文件直接读到内存里。
优点:
- RDB 快照是压缩后的二进制文件,文件的大小会很小,比较适合使用全量复制与备份的场景。
- 相比于 AOF 机制,如果数据集很大,RDB 的恢复效率会更高。
缺点:
- 如果想保证数据的高可用性,即最大限度的避免数据丢失,那么 RDB 不是一个很好的选择,因为系统一旦在定时持久化之前出现宕机现象,没有来得及写入磁盘的数据都将丢失。
- 由于每次生成 RDB 快照都需要 fork 子进程生成全量数据的快照,占用 CPU 与磁盘资源,不适合于频繁执行。
- 兼容问题,不同版本的 redis 生成的快照可能不兼容。
AOF,全称为 Append Only File,将操作命令与数据以格式化的方式追加到操作日志文件的尾部,在 append 操作返回后(已经写入到文件或者即将写入),才进行实际的数据变更,日志文件保存了历史所有的操作过程,当 redis server 需要恢复数据时,可直接重放该日志文件,即可还原所有的操作过程。
在 redis 中提供每秒同步、每次修改同步、不同步3 种同步策略。实际每秒同步是异步完成的,其效率高,一旦系统出现宕机,则这一秒内修改的数据将会丢失。
每次修改同步,即每次发生的数据变化都会被立即记录到磁盘中,可想而至,这种同步方式效率是最低的。
优点:
- AOP 机制提供更高的数据安全性,即数据持久性。
- AOF 持久化方式包含一个格式清晰、易于理解的日志内容,用于记录所有的修改操作。
- 对于写入了一半数据后出现了系统崩溃的现象,redis 能通过 redis-check-aof 工具帮助解决数据一致性的问题。
- 当日志文件过大时,redis 会启动 rewrite 机制,可以删除其中的某些命令。
缺点:
- 对相同数量的数据而言,AOF 文件通常要大于 RDB 文件,AOF 的恢复数据的速度要比 RDB 效率低。
- 根据同步策略的不同,AOF 在运行效率上通常会慢于 RDB,但每秒同步策略的效率是比较高的,禁用同步策略的效率和 RDB 效率类似。
对于选择哪种持久化方式,可根据系统能否接受部分性能的牺牲,通过 AOF 方式换取更高的数据一致性,或者禁用 RDB 备份换取更高的性能,待请求量或流量少的时间点再定时执行 save 命令做快照备份,但目前生产环境接触的更多都是二者结合使用的。
2)redis 部署方式有哪些
单机模式,即只有一个 redis 实例,所有的服务都连接到该实例上,该模式不适用于生产环境,若 redis 实例发生宕机或内存不足等,将导致所有服务都受影响。
哨兵模式,redis 官方推荐的高可用性方案,在 master 宕机后,redis 本身不具备自动主备切换的功能,而 redis-sentinel 是一个独立运行的进程,它能监控多个 master-slave 集群,发现 master 宕机后能自动选举新的 master。
集群模式,随着业务和数据量剧增,已达到单节点性能瓶颈,垂直扩容受机器限制,水平扩容涉及对业务的影响,及数据迁移时存在数据丢失的风险。
因此在 redis 3.0 推出 cluster 分布式集群方案,当遇到单节点内存、并发、流量瓶颈时,可采用cluster 方案实现负载均衡,该方案主要解决分片问题,把整个数据按照规则分成多个子集存储在多个不同 redis 节点上,每个节点各自负责整个数据的一部分。
3)redis 过期数据清除机制
被动删除:当操作读/写一个已过期的 key 时,会触发惰性删除策略,直接删除过期 key 并且返回NIL。
主动删除:由于惰性删除策略无法保证冷数据被及时删掉,因此 redis 会定期主动淘汰清除已过期的 key。
4)redis 内存淘汰策略
当前已用内存超过 redis 配置的 maxmemory 限定时,会触发主动清理策略,策略如下:
- noeviction :不进行数据淘汰,当缓存被写满后,Redis不提供服务直接返回错误。
- volatile-random :在设置过期时间的键值对中随机删除。
- volatile-ttl :在设置过期时间的键值对,基于过期时间的先后进行删除,越早过期的越先被删除。
- volatile-lru:基于LRU(Least Recently Used) 算法筛选设置了过期时间的键值对, 最近最少使用的原则筛选数据。
- volatile-lfu:使用 LFU( Least Frequently Used ) 算法选择设置了过期时间的键值对, 使用频率最少的原则筛选数据
- allkeys-random:从所有键值对中随机选择并删除数据。
- allkeys-lru:使用 LRU 算法在所有数据中进行筛选。
- allkeys-lfu:使用 LFU 算法在所有数据中进行筛选。
点赞,转发,评论,感谢支持!!!
以上是关于redis 技术分享的主要内容,如果未能解决你的问题,请参考以下文章