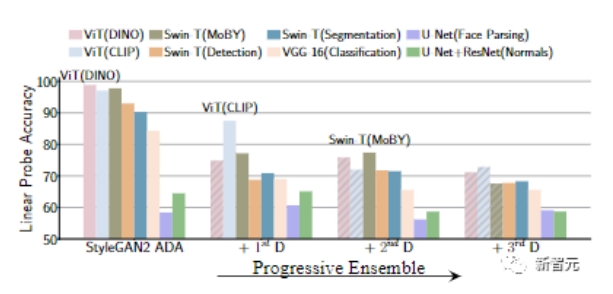
Training and validation accuracy w.r.t. training iterations for our DINO [11] based discriminator vs. baseline StyleGAN2-ADA discriminator on FFHQ 1k dataset.
Figure 3. Our discriminator based on pretrained features has higher accuracy on validation real images and thus shows better generalization. In the above training, vision aided adversarial loss is added at the 2M iteration.
此外,判别器可能会关注那些人类无法辨别但对机器来说很明显的伪装。
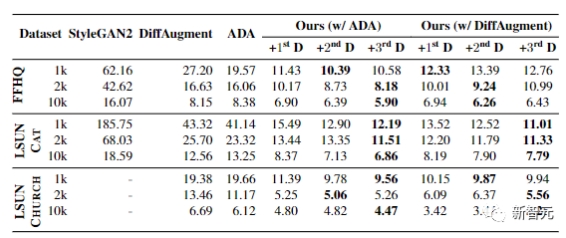
为了平衡判别器和生成器的能力,研究人员提出将一组不同的预训练模型的表征集合起来作为判别器。
Vision-aided GAN training.
Figure 1. The model bank F consists of widely used and state-of-the-art pretrained networks. We automatically select a subset from F, which can best distinguish between real and fake distribution. Our training procedure consists of creating an ensemble of the original discriminator D and discriminators based on the feature space of selected off-the-shelf models. is a shallow trainable network over the frozen pretrained features.

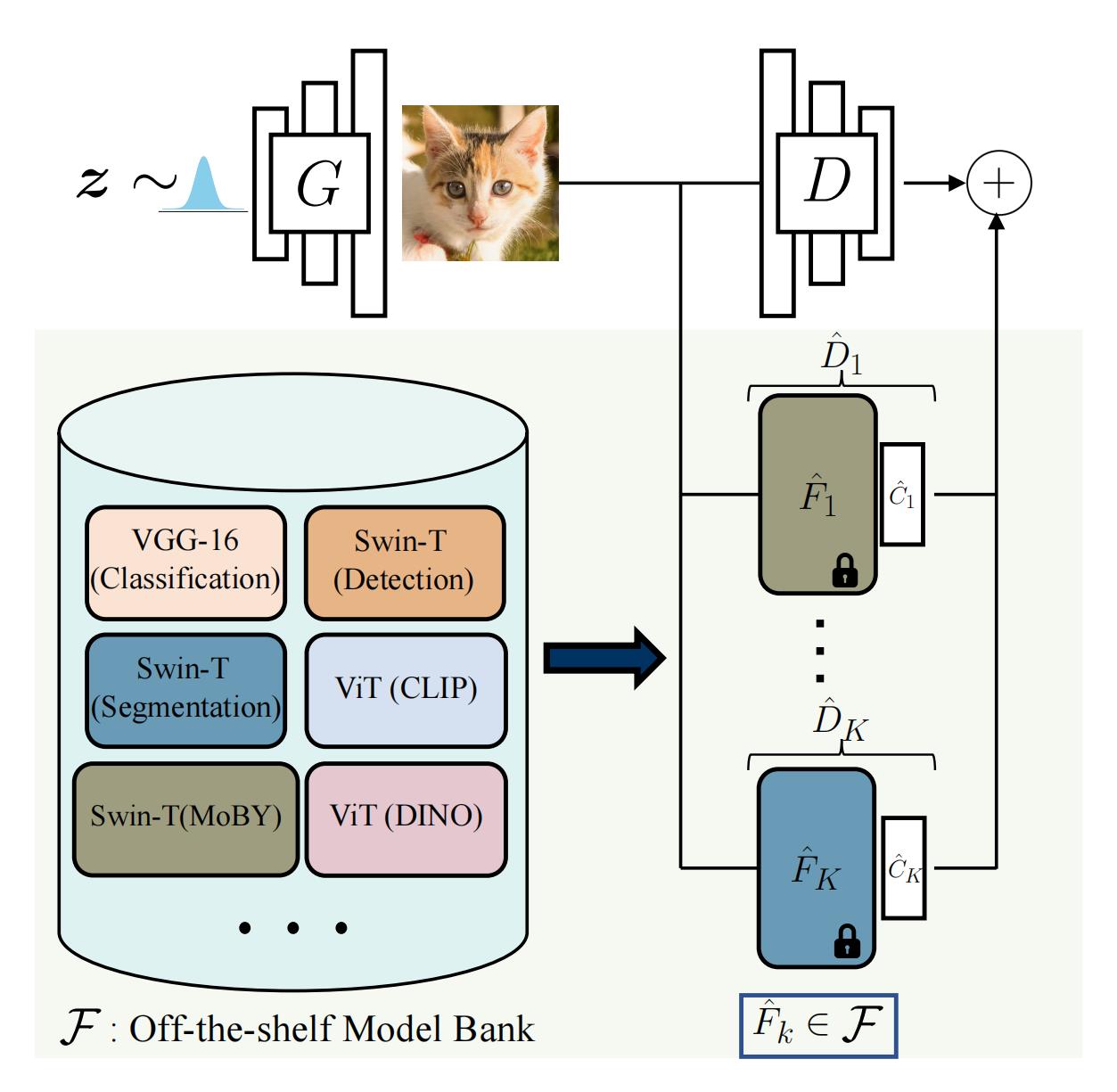
 from F, which can best distinguish between real and fake distribution.
from F, which can best distinguish between real and fake distribution.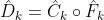 based on the feature space of selected off-the-shelf models.
based on the feature space of selected off-the-shelf models. is a shallow trainable network over the frozen pretrained features.
is a shallow trainable network over the frozen pretrained features.