多表数据增量导入详细文档
Posted Z-hhhhh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多表数据增量导入详细文档相关的知识,希望对你有一定的参考价值。
案例是两个表增量同步到一张表,
当然也可以单表 或 多表增量同步。
kettle安装
1)安装 jdk,版本建议1.8及以上
2)下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可
3)双击Spoon.bat,启动图形化界面工具,就可以直接使用了
mysql驱动连接
将对5.1.37版本的mysql连接驱动放到kettle 安装目录下面的lib文件夹下,然后重启kettle 的客户端Spoon
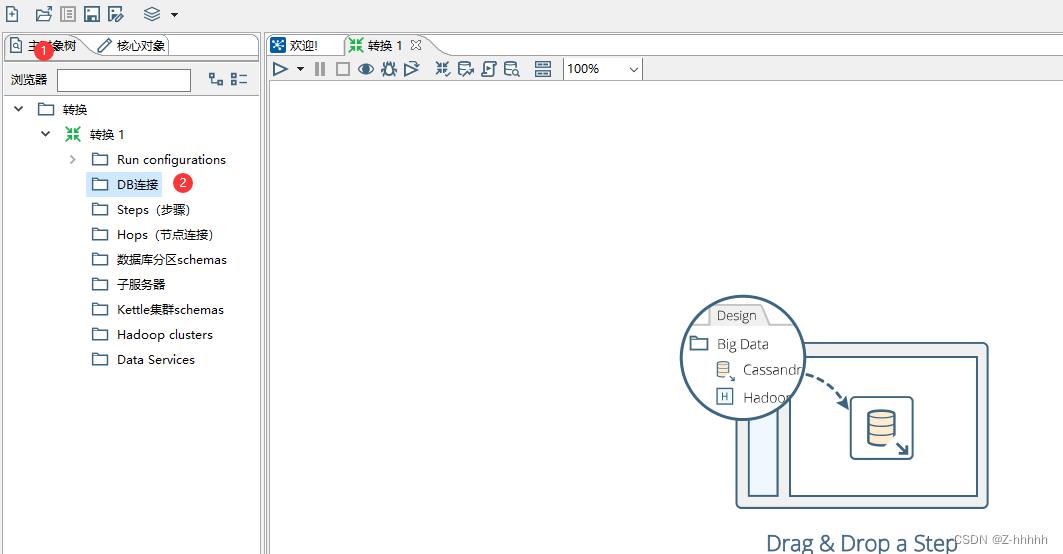
新建
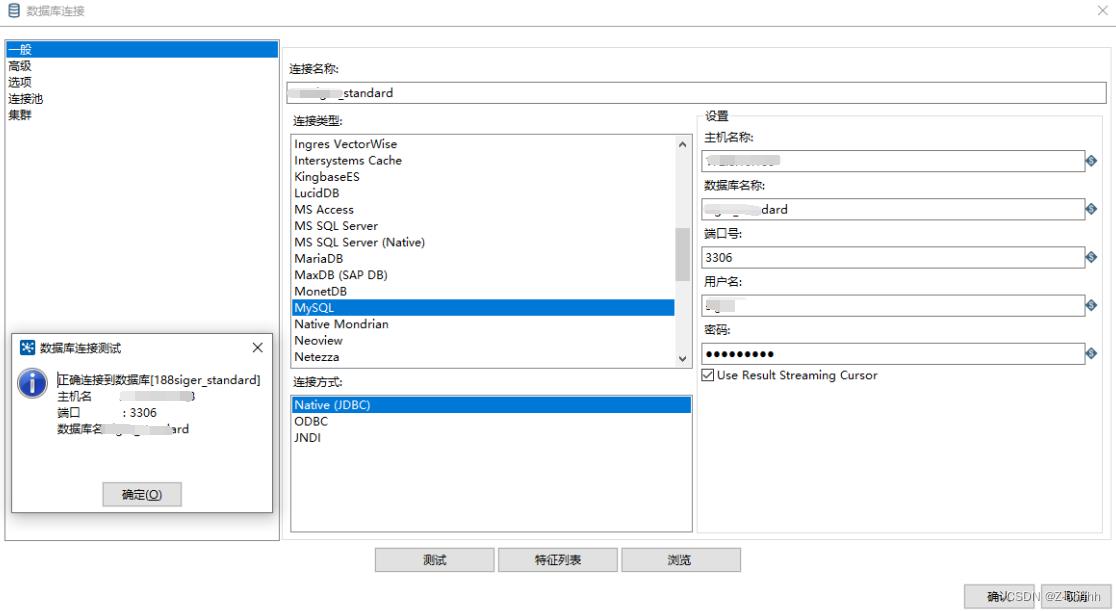
数据库连接默认只对本转换有效,换一个转换以后,这个连接就没法用了,还需要新建数据库连接,所以我们需要将建好的这个数据库连接进行共享下,共享以后,其他的转换也能用我们提前建好的这个数据库连接了。
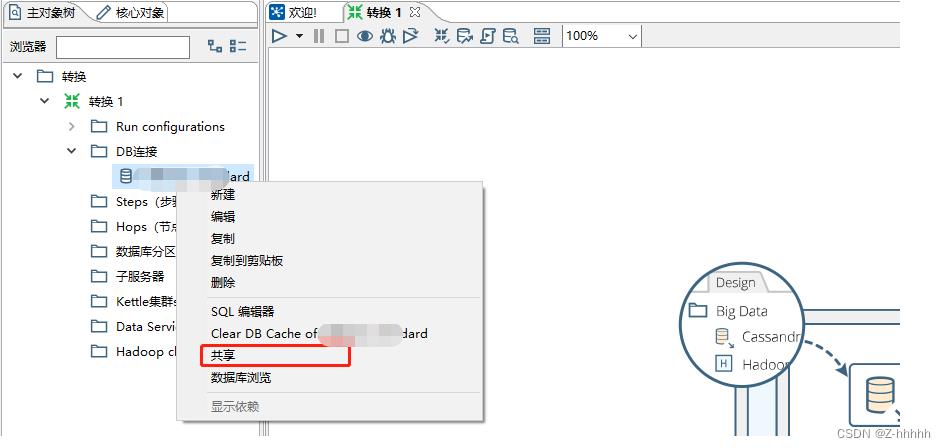
同上,建第二个连接,并共享(黑色加粗)
新建mergeInfo表
本表用来存merge的时间戳的,每次用时间进行对比,即可用于增量导入数据
建表语句如下(示例放在了上述中的一个库里)
CREATE TABLE `mergeInfo` (
`Id` int NOT NULL AUTO_INCREMENT,
`dataBaseName` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`tableName` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`lastMergeTime` datetime NOT NULL,
PRIMARY KEY (`Id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='增量导入时间戳';
其中 lastMergeTime 字段就是用来记录上一次增量导入的时间
插入第一次的时间
INSERT INTO siger_standard.mergeInfo
(`dataBaseName`, tableName, lastMergeTime)
VALUES('xxxdbName', 'xxxxtableName', '2000-07-01 18:14:13');
-- 第一次的时间写的尽量早一些,比源表中最小的时间还要小
-- 如果源表采用的是时间戳格式,可以在后面增量插入时加一个函数转换,或者 mergeInfo 表加一个字段为timestamp,与此处的lastMergeTime类似
整体思路
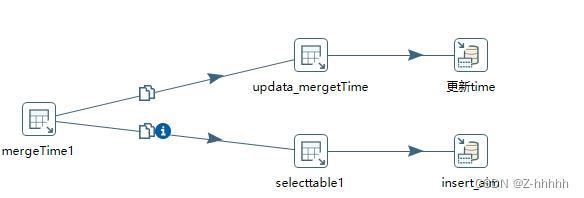
① 先说上分支,从mergeInfo中获取源表A增量导入到目标表C的上一次时间,然后获取源表A的最后时间,作为下一次增量导入的开始时间
②下面的分支,拿到上次时间后,查询源表A中所有时间>刚才的数据,插入到目标表C中
③另外一张源表B 再增加一个上述任务,由于mergeInfo中有dataBaseName和tableName,所以互不影响,能够完成多表增量导入到统一表中
具体案例
案例为数据库DB1中源表A,导入到 DB1中目标C, 操作时灵活替换。
新建转换一
右击转换,新建一个转换,ctrl+s保存,命名如DB1_tableA
- 增加表输入
核心对象-输入-表输入,直接拖到右侧的操作台
- 双击,进入编辑,编辑如下内容
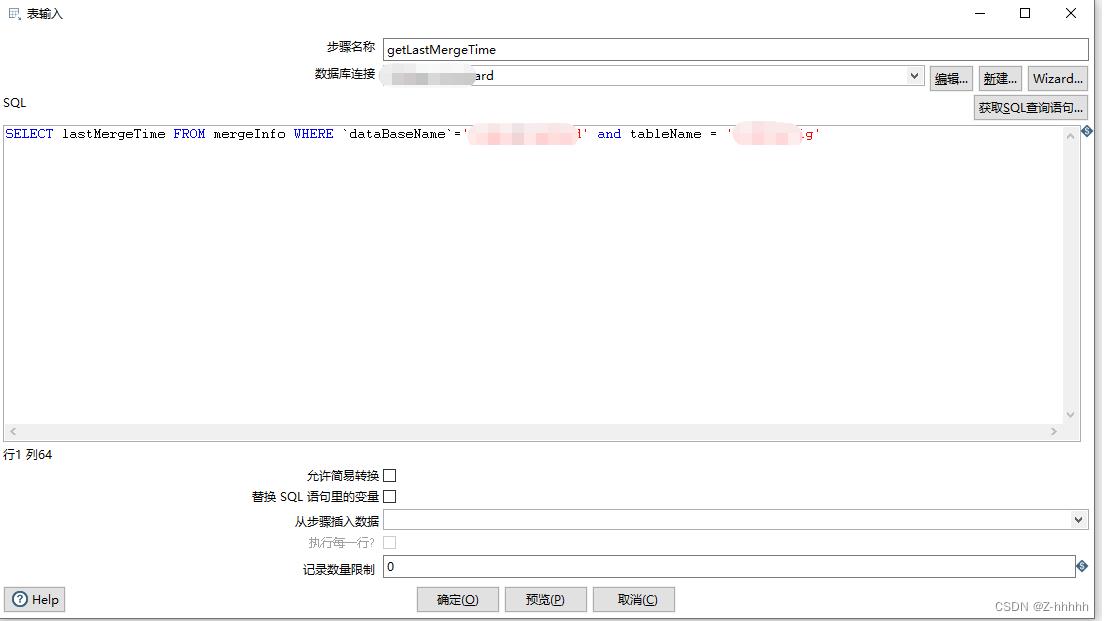
-
增加表输入2
按住shift 不松开,单机前一个表输入, 再点一下后一个表输入,松开shift,把他们连起来,后面每加节点就要和前面的连起来,连接方式相同,不再赘述。
编辑如下内容

-
增加输出
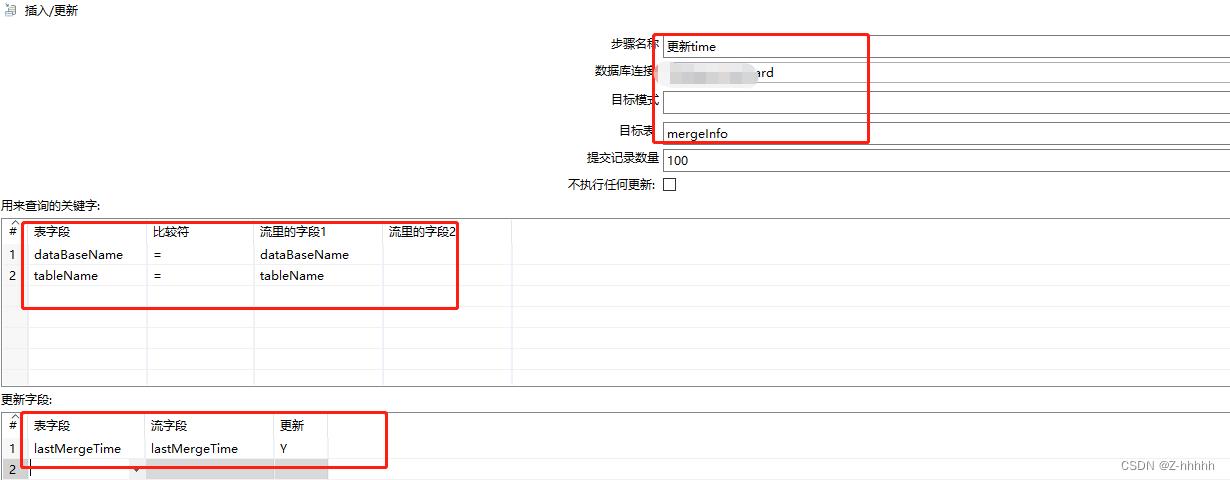
核心对象-输出-插入/更新
编辑如下
其中红色框的地方需要特别注意
- 加一个表输入
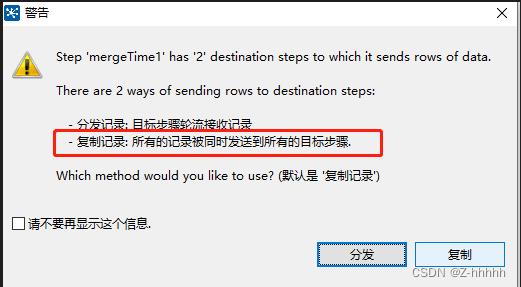
用最开始的getLastMergeTime指向这个新增的表输入,会出现如下的弹窗,选择 【复制】 。
编辑以下内容
sql内容就是源表A所有的字段,WHERE是用来比较的时间,?是从上一个导入的

-
增加输出
和上一个输出一样的 【插入/更新】
编辑以下内容

右边的获取字段 是可以直接获取的,比自己写省事多了。
最后效果如下:

最后把这个转换保存
- 执行测试
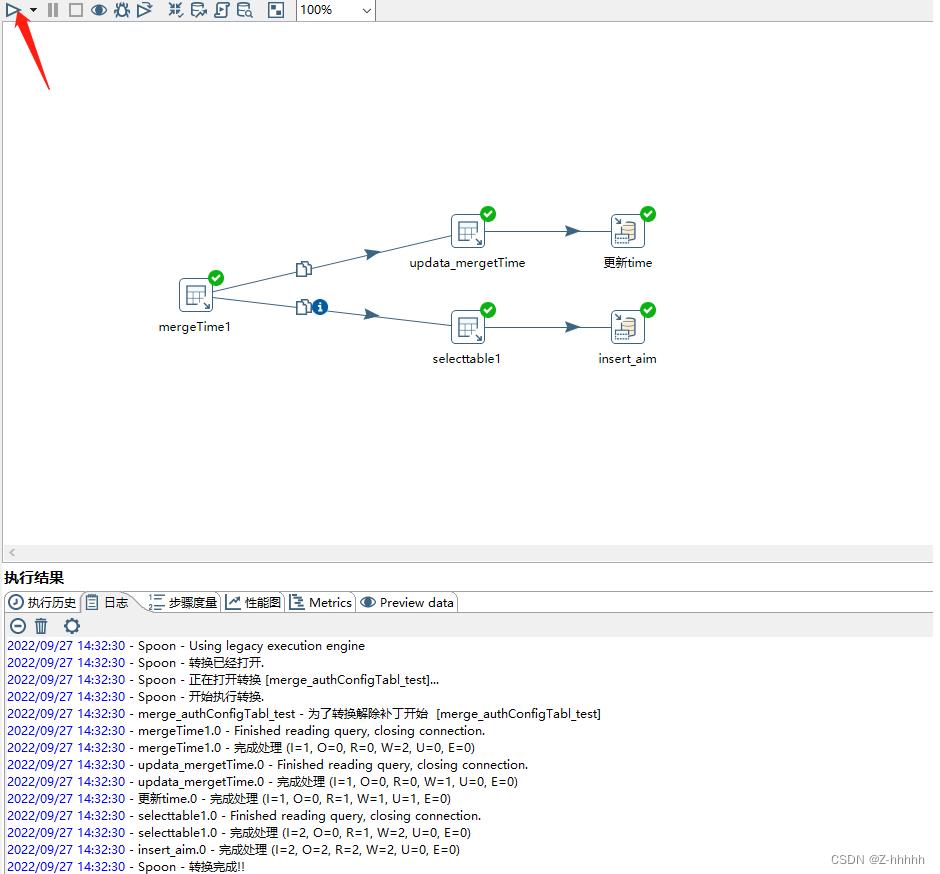
如上图,即为成功,若未成功,请检查操作与上述步骤是否一致。
上图步骤度量 可以看到 每次执行的数据量有多少
新建转换二
新建方式同上,只需要改把源表A改成源表B即可,不再赘述。
新建定时job
- 新建作业(job)
-
添加开始

-
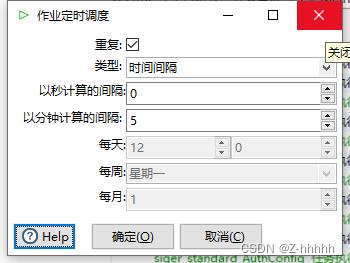
设置时间
编辑时间间隔,图示 是五分钟执行一次。
[记得把重复勾选上]
-
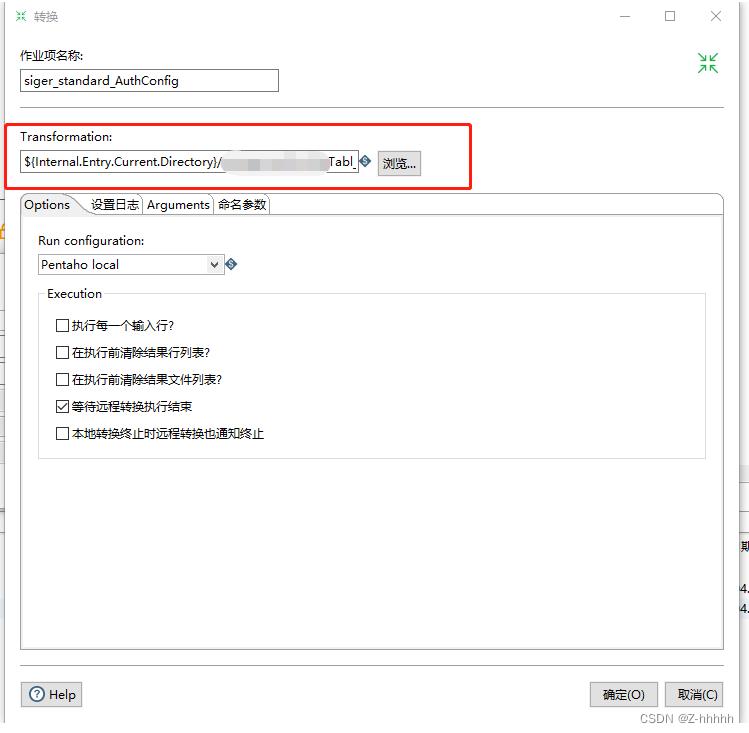
设置转换
设置如下图
作业名自定义,红框内选择转换一的文件。同理设置第二个转换。
-
保存此job
效果如下

- 测试执行
左上角 执行(run)
按照示例,五分钟之后开始执行任务,每五分钟执行一次。
执行如下图:

补充:
- kjb格式是kettle的job, ktr格式是转换
使用注意项
参数
kettle使用的是Java,可以手动修改JVM的参数
在spoon.sh中 [ PENTAHO_DI_JAVA_OPTIONS ]
-Xms1024m : 设置JVM最大可用内存为1024M
-Xmx1024m : 设置JVM促使内存为1024m。此值可以设置与:Xmx相同、以避免每次垃圾回收完成后JVM重新分配内存。
若报错
启动时报错ignoring option MaxPermSize=256M
JDK8中,MaxPermSize已不再支持。
提交记录数据量
可以根据数据量大小来设置Commitsize:1000~50000
连接池
连接较多时可以使用连接池。
DB连接——编辑已建好的连接——连接池
根据需求设置连接池参数
以上是关于多表数据增量导入详细文档的主要内容,如果未能解决你的问题,请参考以下文章