Python采集《惊奇先生》, 下载你想看的高质量漫画
Posted 搬砖python中~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python采集《惊奇先生》, 下载你想看的高质量漫画相关的知识,希望对你有一定的参考价值。
前言
大家早好、午好、晚好吖~

知识点:
-
爬虫基本流程
-
保存海量漫画数据
-
requests的使用
-
base64解码
开发环境:
-
版 本:python 3.8
-
编辑器:pycharm
-
requests: pip install requests
-
parsel: pip install parsel
如何安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
实现代码:
-
发送请求
-
获取数据
-
解析数据
-
保存数据
代码
源码、教程 点击 蓝色字体 自取 ,我都放在这里了。
import base64
import requests
import re
import json
import parsel
import os
# 伪装
headers =
# 用户信息
'cookie': '__AC__=1; tvfe_boss_uuid=bb88930a5ac8406d; iip=0; _txjk_whl_uuid_aa5wayli=55a33622e35c40e987c810022a8c40c6; pgv_pvid=6990680204; ptui_loginuin=1321228067; RK=Kj3JwrkEZn; ptcz=42d9e016607f032705abd9792c4348479e6108da38fd5426d9ecaeff1088aa19; fqm_pvqid=d77fc224-90eb-4654-befc-ab7b6d275fb4; psrf_qqopenid=4F37937E43ECA9EAB02F9E89BE1860E2; psrf_qqaccess_token=2B1977379A78742A0B826B173FB09E92; wxunionid=; tmeLoginType=2; psrf_access_token_expiresAt=1664978634; psrf_qqrefresh_token=03721D80236524B49062B95719F2F8B4; psrf_qqunionid=FAEE1B5B10434CF5562642FABE749AB9; wxrefresh_token=; wxopenid=; euin=oKoAoK-ANens7z**; o_cookie=3421355804; ts_refer=www.baidu.com/link; ts_uid=6545534402; readLastRecord=%5B%5D; pac_uid=1_3421355804; luin=o0210105510; lskey=00010000d1fa763dc45458abb8932a1377e83940e9f5148497289242137055f80e361f8e6eea4b3e2393f866; nav_userinfo_cookie=; ac_wx_user=; Hm_lvt_f179d8d1a7d9619f10734edb75d482c4=1661602022,1664001338; pgv_info=ssid=s6096813906; theme=dark; roastState=2; _qpsvr_localtk=0.07137748820842615; readRecord=%5B%5B511915%2C%22%E4%B8%AD%E5%9B%BD%E6%83%8A%E5%A5%87%E5%85%88%E7%94%9F%22%2C1%2C%22%E4%BC%A0%E8%AF%B4%22%2C1%5D%2C%5B629440%2C%22%E6%AD%A6%E7%82%BC%E5%B7%85%E5%B3%B0%22%2C7%2C%22%E6%92%9E%E7%A0%B4%E5%8D%97%E5%A2%99%E4%B8%8D%E5%9B%9E%E5%A4%B4%EF%BC%88%E4%B8%89%EF%BC%89%22%2C4%5D%2C%5B531040%2C%22%E6%96%97%E7%A0%B4%E8%8B%8D%E7%A9%B9%22%2C58%2C%2249%EF%BC%88%E4%B8%8B%EF%BC%89%22%2C58%5D%2C%5B645332%2C%22%E6%88%91%E4%B8%BA%E9%82%AA%E5%B8%9D%22%2C3%2C%22%E7%A9%BF%E8%B6%8A%E4%BA%86%EF%BC%8C%E6%8E%89%E8%BF%9B%E5%A6%96%E5%A5%B3%E7%AA%9D%22%2C1%5D%2C%5B644270%2C%22%E5%A4%A7%E8%B1%A1%E6%97%A0%E5%BD%A2%22%2C30%2C%22%E7%AC%AC%E4%BA%8C%E5%8D%81%E4%BA%94%E7%AB%A0%2F%E5%91%BD%E6%95%B0%E4%B8%8B%22%2C25%5D%2C%5B531616%2C%22%E8%88%AA%E6%B5%B7%E7%8E%8B%EF%BC%88%E7%95%AA%E5%A4%96%E7%AF%87%EF%BC%89%22%2C1%2C%22%E7%95%AA%E5%A4%961%20%E8%8D%89%E5%B8%BD%E5%89%A7%E5%9C%BA%3A%E6%B5%B7%E7%9A%84%E9%9F%B3%E4%B9%90%E4%BC%9A%22%2C1%5D%2C%5B505430%2C%22%E8%88%AA%E6%B5%B7%E7%8E%8B%22%2C7%2C%22%E7%AC%AC6%E8%AF%9D%20%E7%AC%AC%E4%B8%80%E4%B8%AA%E4%BA%BA%22%2C6%5D%2C%5B530876%2C%22%E6%8E%92%E7%90%83%E5%B0%91%E5%B9%B4%EF%BC%81%EF%BC%81%22%2C2%2C%22%E7%AC%AC1%E8%AF%9D%20%E7%BB%93%E6%9D%9F%E4%B8%8E%E5%BC%80%E5%A7%8B%22%2C1%5D%2C%5B17114%2C%22%E5%B0%B8%E5%85%84%EF%BC%88%E6%88%91%E5%8F%AB%E7%99%BD%E5%B0%8F%E9%A3%9E%EF%BC%89%22%2C3%2C%22%E7%AC%AC1%E9%9B%86%22%2C1%5D%2C%5B650998%2C%22%E5%A4%A7%E7%8C%BF%E9%AD%82%EF%BC%88%E8%A5%BF%E8%A1%8C%E7%BA%AA%E7%B3%BB%E5%88%97%EF%BC%89%22%2C1011%2C%22%E3%80%8A%E5%A4%A7%E7%8C%BF%E9%AD%82%E3%80%8B%E5%BA%8F%E7%AB%A0%22%2C1%5D%5D; ts_last=ac.qq.com/ComicView/index/id/511915/cid/1; Hm_lpvt_f179d8d1a7d9619f10734edb75d482c4=1664021694',

select = parsel.Selector(requests.get(main_url, headers=headers).text)
title_list = select.css('.chapter-page-all.works-chapter-list li a::text').getall()
link_list = select.css('.chapter-page-all.works-chapter-list li a::attr(href)').getall()
for title, link in zip(title_list, link_list):
url = 'https://ac.qq.com' + link
title = title.strip()
if not os.path.exists(f'中国惊奇先生/title'):
os.makedirs(f'中国惊奇先生/title')
# 1. 发送请求
response = requests.get(url=url, headers=headers)
print(title, url)
# 2. 获取数据
html_data = response.text
# 3. 解析数据
DATA = re.findall("var DATA = '(.*?)'", html_data)[0]
for i in range(len(DATA)):
try:
json_str = base64.b64decode(DATA[i:].encode("utf-8")).decode("utf-8")
json_str = re.findall('"picture":(\\[.*?\\])', json_str)[0]
# 字符串 转 字典/列表
json_list = json.loads(json_str)
count = 1
for imgInfo in json_list:
imgUrl = imgInfo['url']
print(imgUrl)
# 4. 保存数据
img_data = requests.get(url=imgUrl).content
with open(f'中国惊奇先生/title/count.jpg', mode='wb') as f:
f.write(img_data)
count += 1
break
except:
pass
效果
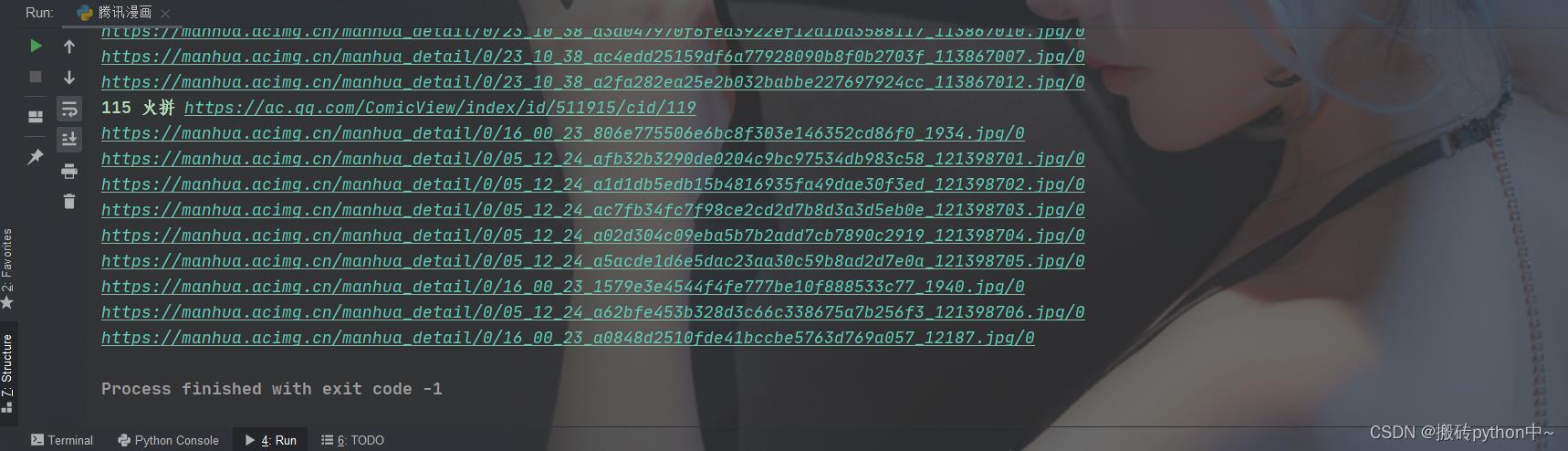
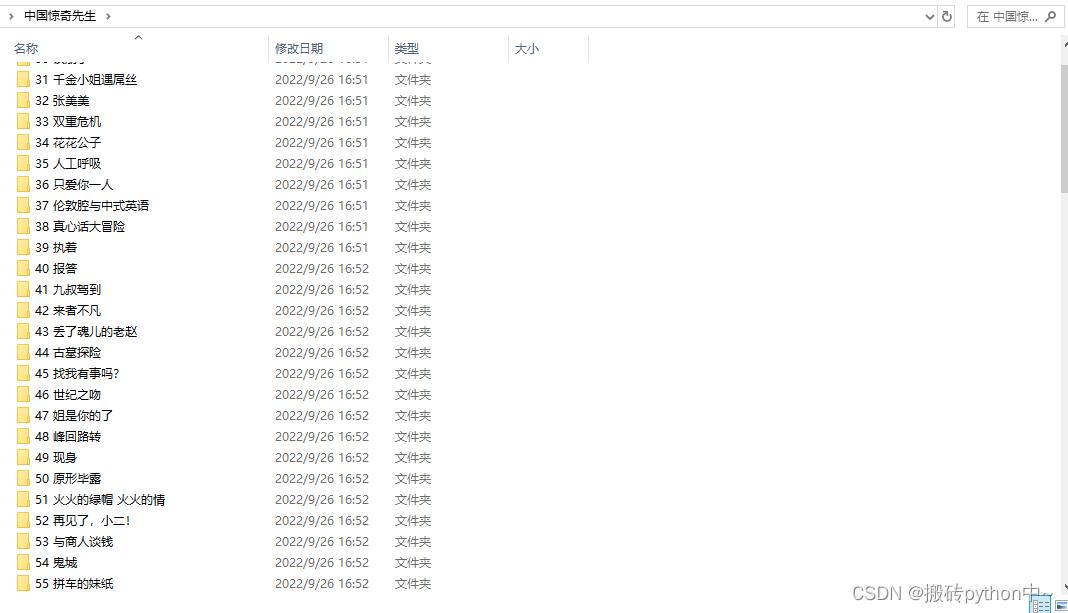
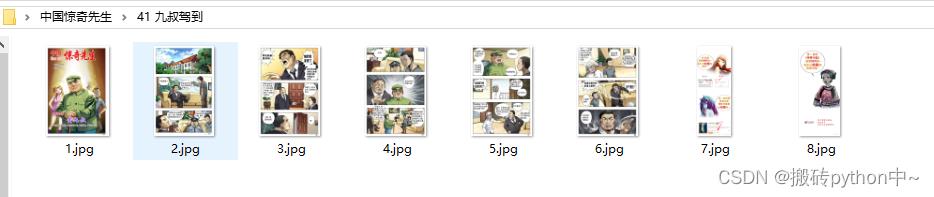
文章看不懂,我专门录了对应的视频讲解,本文只是大致展示,完整代码和视频教程点击下方蓝字
点击 蓝色字体 自取,我都放在这里了。
尾语 💝
好了,我的这篇文章写到这里就结束啦!
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!

以上是关于Python采集《惊奇先生》, 下载你想看的高质量漫画的主要内容,如果未能解决你的问题,请参考以下文章