29.安全集合
Posted 纵横千里,捭阖四方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了29.安全集合相关的知识,希望对你有一定的参考价值。
我们知道HashMap是线程不安全的,而HashTable是线程安全的。HashTable的线程安全体现在将put和get等操作都加了synchronized关键字,这样虽然能保证安全性,效率自然也不高。那HashMap为什么线程不安全呢?如何才能设计安全的HashMap呢?本章我们就来研究一下。
6.1 为什么HashMap线程不安全
HashMap不安全主要是在插入和扩容的时候发生的,造成死循环、数据覆盖,也导致部分数据丢失。
先看插入元素的时候,由于多线程对HashMap进行put操作,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A找到位置尚未插入元素时由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,并完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
在扩容的时候,某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据已经被改变,此时导致执行的混乱,造成死循环、数据丢失等情况。 我们可以看一下如下图示:
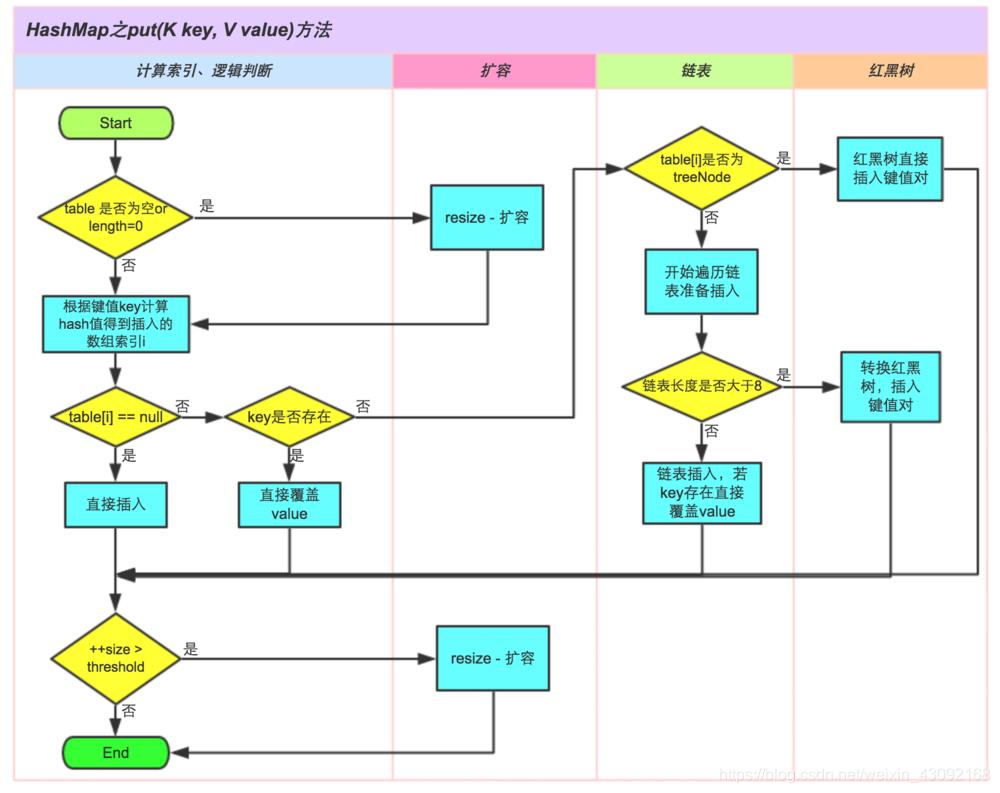
上图为HashMap的PUT方法的详细过程.其中造成线程不安全的方法主要是插入的时候和resize(扩容)方法. 情况一: 假设现在有线程A 和线程B 共同对同一个HashMap进行PU操作,假设A和B插入的Key-Value中key的hashcode是相同的,这说明该键值对将会插入到Table的同一个下标的,也就是会发生哈希碰撞,此时HashMap按照平时的做法是形成一个链表(若超过八个节点则是红黑树),现在我们插入的下标为null(Table[i]==null)则进行正常的插入,此时线程A进行到了这一步正准备插入,这时候线程A堵塞,线程B获得运行时间,进行同样操作,也是Table[i]==null , 此时它直接运行完整个PUT方法,成功将元素插入. 随后线程A获得运行时间接上上面的判断继续运行,进行了Table[i]==null的插入(此时其实应该是Table[i]!=null的操作,因为前面线程B已经插入了一个元素了),这样就会直接把原来线程B插入的数据直接覆盖了,如此一来就造成了线程不安全问题. 情况二: 这种情况是resize的时候造成的.现在假设HashMap中的Table情况如下:

线程A和线程B要对同一个HashMap进行PUT操作.插入后Table变为:
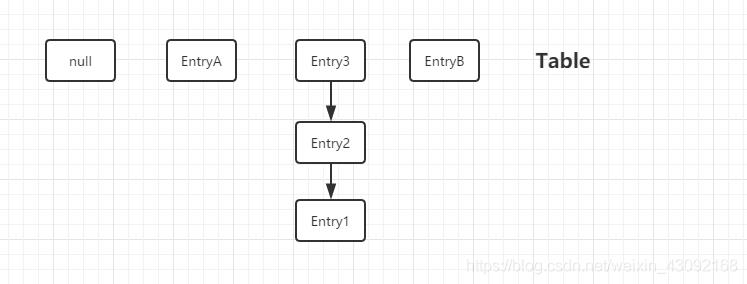
此时,线程A和B都需要对HashMap进行扩容. 假设线程A没有堵塞过,顺利完成resize后Table如下(这里的元素位置都是假设的):

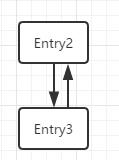
如果线程B的resize是在Entry3的时候堵塞的,那么当它再次执行的时候就会造成上图红框处形成一个循环链表,当进行get操作时候可能陷入死循环,原因是: 线程B获得CPU时e = Entry3 ,next = Entry 2 ;正常赋值,然后进行下一次循环遍历时要注意,此时HashMap已经被线程A resize 过得了,那么就有 e = Entry 2 , next = Entry3 ; 头插法插入此时:
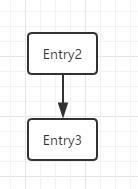
接着循环,e = Entry 3 ,next = Entry3.next = null (看图) ,此时再用头插法的时候头插法就会形成循环链表了:
6.2 ConcurrentHashMap介绍
先看一下使用ConcurrentHashMap的例子:
public class ConcurrentHashMapTest
public static void main(String[] args)
Map<String, String> map = new ConcurrentHashMap<String, String>();
map.put("1", "1");
map.put("2", "2");
map.put("3", "3");
map.put("4", "4");
// map.keySet().iterator();
Iterator<String> it = map.keySet().iterator();
while (it.hasNext())
String key = it.next();
System.out.println(key + "," + map.get(key));
if (key.equals("3"))
map.put(key + "key", "3");
那ConcurrentHashMap是如何实现线程安全的呢?其机制在JDK7和8中有所不用。
JDK1.7中 将一个大的HashMap分成16个segetment,每个segement其实就是一个Hashtable。如果出现冲突会采用线性方式连接。

而JDK1.8中取消了segemnt,加锁粒度更小,如下图所示:

如果当单个节点的元素比较多时会该节点对应的链改造成红黑树结构。如下图:
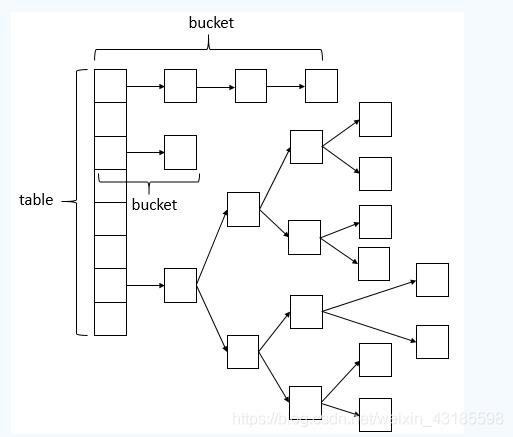
这里我们要注意扩容和转换成红黑树的条件分别是什么:
扩容的条件:数组长度小于等于64,并且单个结点的链表长度大于8。
转换成红黑树的条件:数组长度大于64,并且单个结点的链表长度大于8。
如何佐证上述结论呢?我们看几个源码:
我们追踪代的入口是:
Map<String, String> map = new ConcurrentHashMap<String, String>();
map.put("1", "1");从put进入,最终到达ConcurrentHashMap的putValue(),这个方法还是比较复杂的,我们看几个关键点。
final V putVal(K key, V value, boolean onlyIfAbsent)
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;)
Node<K,V> f; int n, i, fh;
//初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null)
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
//如果发现当前map正在进行扩容,则协助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else //正常插入元素
V oldVal = null;
synchronized (f)
if (tabAt(tab, i) == f)
//如果当前结构是链表,则插入
if (fh >= 0)
binCount = 1;
for (Node<K,V> e = f;; ++binCount)
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek))))
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
Node<K,V> pred = e;
if ((e = e.next) == null)
pred.next = new Node<K,V>(hash, key,
value, null);
break;
else if (f instanceof TreeBin)
//如果当前结构是红黑树,则执行红黑树插入
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null)
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
if (binCount != 0)
//如果当前位置处元素个数大于TREEIFY_THRESHOLD=8了,则执行扩容操作
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
addCount(1L, binCount);
return null;
上面的代码中有几个关键位置:
bitCount表示的就是Hash里每个位置构造的链表有几个元素,如果超过了TREEIFY_THRESHOLD=8,则执行扩容。我们继续看treeifyBin()方法:
private final void treeifyBin(Node<K,V>[] tab, int index)
Node<K,V> b; int n, sc;
if (tab != null)
//如果当前空间长度小于MIN_TREEIFY_CAPACITY=64则只扩大Map容量
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
//否则就改造成红黑树
else if ((b = tabAt(tab, index)) != null && b.hash >= 0)
synchronized (b)
if (tabAt(tab, index) == b)
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next)
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
setTabAt(tab, index, new TreeBin<K,V>(hd));
上面的TreeNode就是红黑树结点:
static final class TreeNode<K,V> extends Node<K,V>
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
.....
ConcurrentHashMap在设计过程中要考虑性能和安全性两个方面的问题,采取了很多高级的设计,主要有以下几种:
1.分段锁设计。
2.多个线程协助实现并发扩容
3.高低位迁移设计。
4.链表与红黑树转换。
5.降低锁的粒度。
但是上述代码读起来味同嚼蜡、晦涩难懂,以后再研究吧。
以上是关于29.安全集合的主要内容,如果未能解决你的问题,请参考以下文章