Redis_13_Redis集群实现RedisCluster应对大数据量
Posted 毛奇志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis_13_Redis集群实现RedisCluster应对大数据量相关的知识,希望对你有一定的参考价值。
文章目录
一、前言
问题:单机Redis会有瓶颈,那你们是怎么解决这个瓶颈的?
回答:集群(永远的永远,处理单机的性能瓶颈就是分布式集群架构,Redis也是这样)
解释:在Redis中,使用的集群的部署方式也就是Redis cluster,并且是主从同步读写分离,类似mysql 的主从同步,Redis cluster 支撑 N 个 Redis master node,每个master node都可以挂载多个 slave node。这样整个 Redis 就可以横向扩容了。如果你要支撑更大数据量的缓存,那就横向扩容更多的 master 节点,每个 master 节点就能存放更多的数据了。
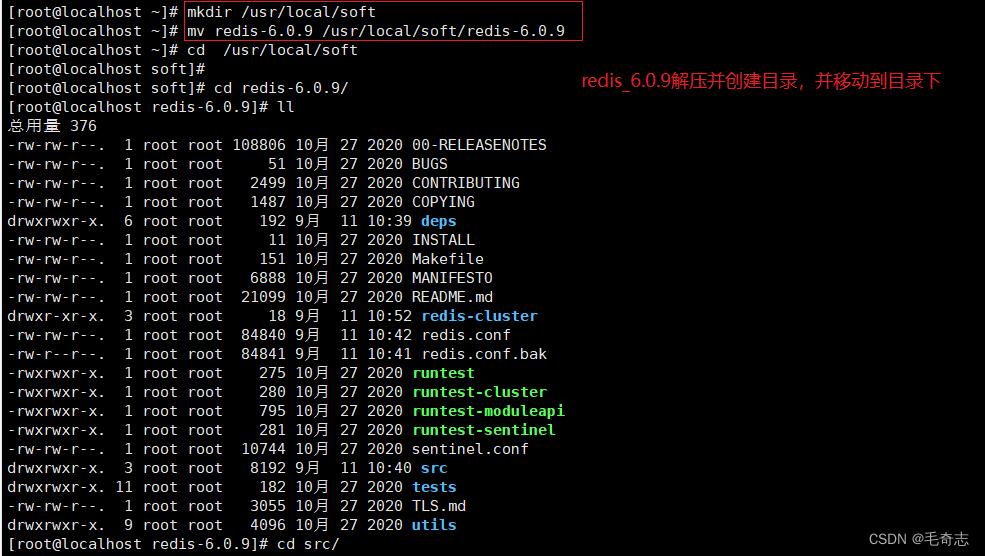
二、CentOS 7 单机安装Redis Cluster6.0.9(3主3从伪集群)
2.1 CentOS 7 单机安装Redis Cluster6.0.9(3主3从伪集群)
为了节省机器,我们直接把6个Redis实例安装在同一台机器上(3主3从),只是使用不同的端口号。
机器IP 192.168.100.138
可以跟单机的redis安装在同一台机器上,因为数据目录不同,没有影响。
cd /usr/local/soft/redis-6.0.9
mkdir redis-cluster
cd redis-cluster
mkdir 7291 7292 7293 7294 7295 7296
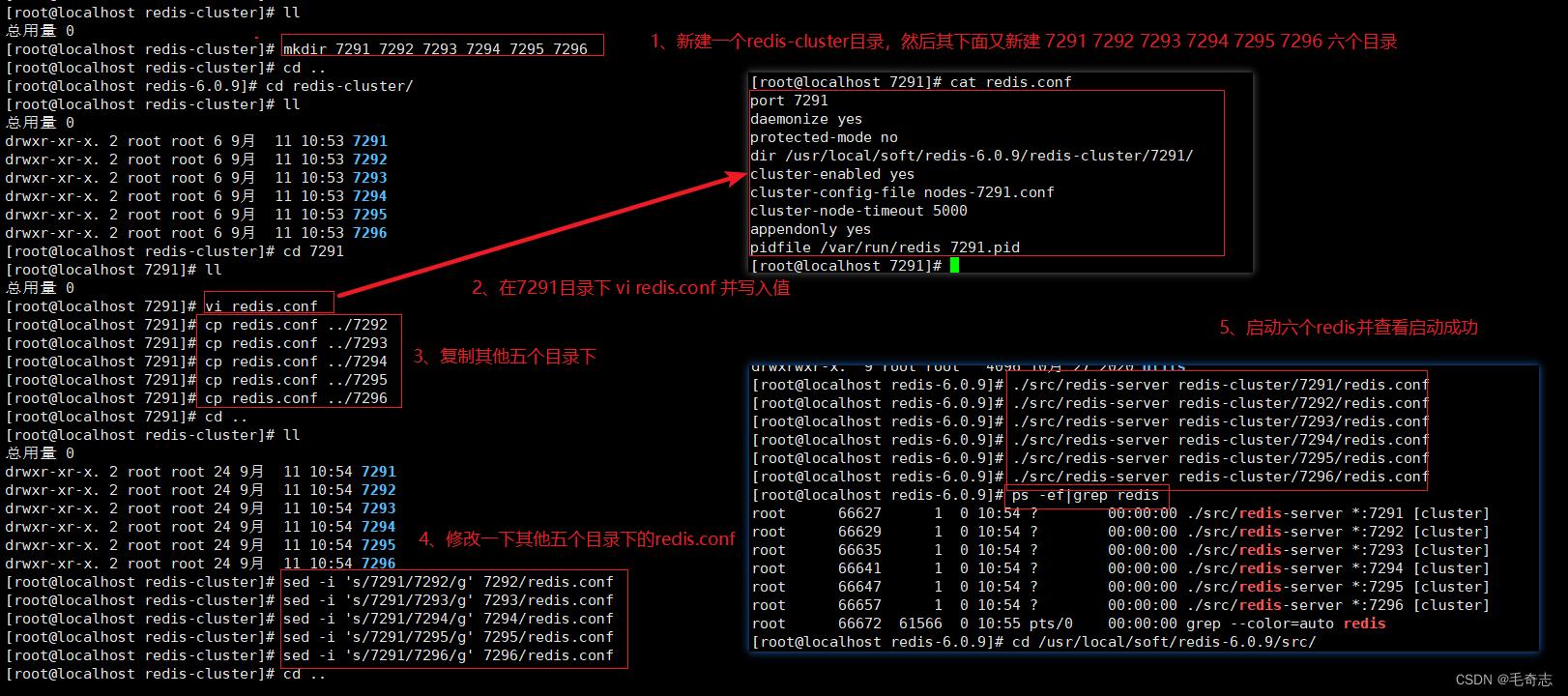
复制redis配置文件到7291目录
cp /usr/local/soft/redis-6.0.9/redis.conf /usr/local/soft/redis-6.0.9/redis-cluster/7291
修改7291的redis.conf配置文件,内容:
cd /usr/local/soft/redis-6.0.9/redis-cluster/7291
vim redis.conf
port 7291
daemonize yes
protected-mode no
dir /usr/local/soft/redis-6.0.9/redis-cluster/7291/
cluster-enabled yes
cluster-config-file nodes-7291.conf
cluster-node-timeout 5000
appendonly yes
pidfile /var/run/redis_7291.pid
注意,外网集群要添加这个配置(如果是自己vmware安装就不需要):
# 实际给各节点网卡分配的IP(公网IP)
cluster-announce-ip 47.xx.xx.xx
# 节点映射端口
cluster-announce-port $PORT
# 节点总线端口
cluster-announce-bus-port 1$PORT
把7291下的redis.conf复制到其他5个目录。
cd /usr/local/soft/redis-6.0.9/redis-cluster/7291
cp redis.conf ../7292
cp redis.conf ../7293
cp redis.conf ../7294
cp redis.conf ../7295
cp redis.conf ../7296
批量替换内容
cd /usr/local/soft/redis-6.0.9/redis-cluster
sed -i 's/7291/7292/g' 7292/redis.conf
sed -i 's/7291/7293/g' 7293/redis.conf
sed -i 's/7291/7294/g' 7294/redis.conf
sed -i 's/7291/7295/g' 7295/redis.conf
sed -i 's/7291/7296/g' 7296/redis.conf
启动6个Redis节点
cd /usr/local/soft/redis-6.0.9/
./src/redis-server redis-cluster/7291/redis.conf
./src/redis-server redis-cluster/7292/redis.conf
./src/redis-server redis-cluster/7293/redis.conf
./src/redis-server redis-cluster/7294/redis.conf
./src/redis-server redis-cluster/7295/redis.conf
./src/redis-server redis-cluster/7296/redis.conf
是否启动了6个进程
ps -ef|grep redis
六个进程都启动起来了,但是现在它们六个都是独立运行的,需要将他们关联起来,三主三从结构
redisCluster的引入解决了 高并发、高可用、大数据量 三个问题。
三主结构:使用三个机器来存放所有数据,保证大数据量水平扩展
三主就有三从:一个主节点就带有一个从节点,保证了主从复制/读写分离,保证高并发
三主就有三从:一个主节点就带有一个从节点,主节点宕机后从节点顶上,保证高可用
六个节点变成了三主三从是因为 redis-cli --cluster create 命令中,指定 --cluster-replicas 1 表示一个主节点只有一个从节点,所以 6 /2 = 3个主节点
cd /usr/local/soft/redis-6.0.9/src/
redis-cli --cluster create 192.168.100.138:7291 192.168.100.138:7292 192.168.100.138:7293 192.168.100.138:7294 192.168.100.138:7295 192.168.100.138:7296 --cluster-replicas 1
注意执行
redis-cli --cluster create命令的时候,用绝对IP,不要用127.0.0.1
Redis会给出一个预计的方案,对6个节点分配3主3从,如果认为没有问题,输入yes确认
批量写入值
cd /usr/local/soft/redis-6.0.9/redis-cluster/
vim setkey.sh
脚本内容
#!/bin/bash
for ((i=0;i<20000;i++))
do
echo -en "helloworld" | redis-cli -h 192.168.44.181 -p 7291 -c -x set name$i >>redis.log
done
chmod +x setkey.sh
./setkey.sh
连接到客户端
redis-cli -p 7291
redis-cli -p 7292
redis-cli -p 7293
每个节点分布的数据
127.0.0.1:7291> dbsize
(integer) 6652
127.0.0.1:7292> dbsize
(integer) 6683
127.0.0.1:7293> dbsize
(integer) 6665
2.2 实践:redisCluster 安装


执行完创建集群之后,就往这个三主三从的集群里面插入数据,如下:


2.3 redisCluster管理命令
cluster管理命令
其他命令,比如添加节点、删除节点,重新分布数据:
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
check host:port
--cluster-search-multiple-owners
info host:port
fix host:port
--cluster-search-multiple-owners
reshard host:port
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
rebalance host:port
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg>
--cluster-simulate
--cluster-pipeline <arg>
--cluster-threshold <arg>
--cluster-replace
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
del-node host:port node_id
call host:port command arg arg .. arg
set-timeout host:port milliseconds
import host:port
--cluster-from <arg>
--cluster-copy
--cluster-replace
help
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
附录:
(在redis客户端执行)

集群命令
cluster info :打印集群的信息
cluster nodes :列出集群当前已知的所有节点(node),以及这些节点的相关信息。
节点命令
cluster meet :将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
cluster forget <node_id> :从集群中移除 node_id 指定的节点(保证空槽道)。
cluster replicate <node_id> :将当前节点设置为 node_id 指定的节点的从节点。
cluster saveconfig :将节点的配置文件保存到硬盘里面。
槽slot命令
cluster addslots [slot …] :将一个或多个槽(slot)指派(assign)给当前节点。
cluster delslots [slot …] :移除一个或多个槽对当前节点的指派。
cluster flushslots :移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
cluster setslot node <node_id> :将槽 slot 指派给 node_id 指定的节点,
如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
cluster setslot migrating <node_id> :将本节点的槽 slot 迁移到 node_id 指定的节点中。
cluster setslot importing <node_id> :从 node_id 指定的节点中导入槽 slot 到本节点。
cluster setslot stable :取消对槽 slot 的导入(import)或者迁移(migrate)。
键命令
cluster keyslot :计算键 key 应该被放置在哪个槽上。
cluster countkeysinslot :返回槽 slot 目前包含的键值对数量。
cluster getkeysinslot :返回 count 个 slot 槽中的键
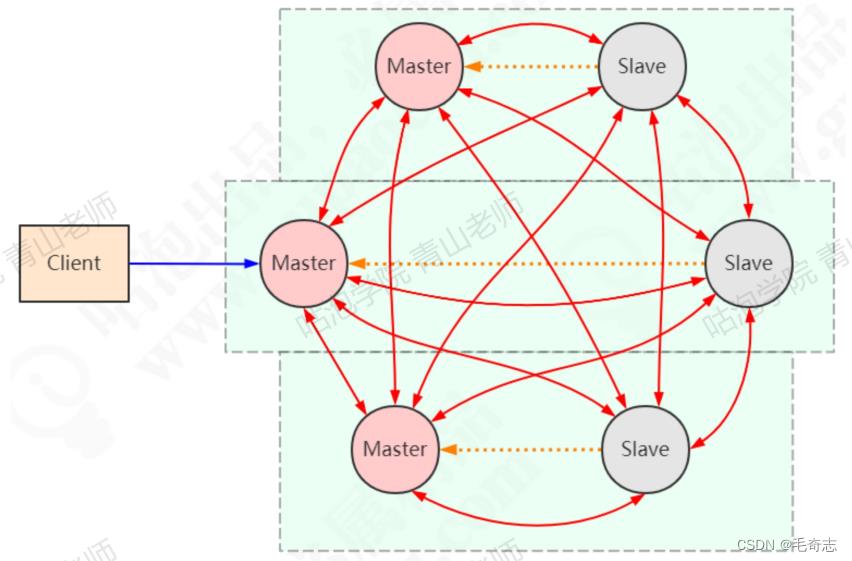
三、Redis Cluster原理
3.1 Redis Cluster架构
Redis Cluster 可以看到是由多个 Redis 实例组成的数据集合。客户端不需要关注数据的自己到底存储在哪个节点,只需要关注这个集合整体。以三主三从为例,节点之间两两交互,共享数据分片、节点状态等信息。
3.2 数据分布
Redis 既没有用哈希取模,也没有用一致性话下,而是通过虚拟槽来实现的。
Redis 创建了 16384 个槽slot,每个节点负责一个区间的 slot 。比如节点1负责 0 -5460 ,Node2 负责 5461 - 10922 ,Node3 负责 10923 - 16383.

当然一个Redis Group节点也不一定是 1主1从,可以是 1主N从 ,如下:
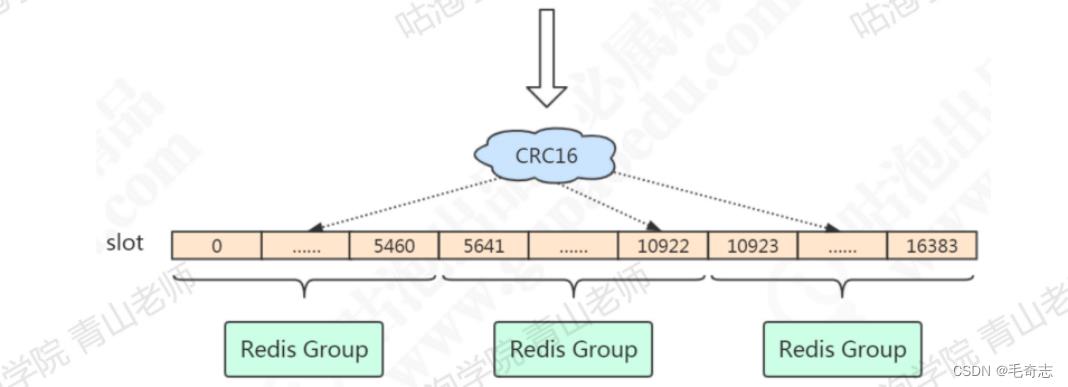
对象分布到 Redis 节点的时候,对 key 使用 CRC16算法计算再 % 16384,得到一个slot的值,数据就落到负责这个slot的redis节点上。
Redis 的每个master节点都会维护自己负责的slot。用一个bit序列实现,比如:序列的第0位是1,就代表第一个slot是它负责的;序列的第1位是0,就代表第二个slot不是它负责的。对于开发者来说,在redis-cli 连接的时候,需要指定连接那个端口,因为有了六个redis,如下:
./redis-cli -p 7291
./redis-cli -p 7292
./redis-cli -p 7293
三者联系:节点时实际使用的机器(个数),slot是16384固定不会改变,N个节点平均的管理 16384 个slot,key是通过算法直接分配到 slot 上,然后间接分配到节点上的。
三者联系
查看一个节点下管理哪些slot?redis-cli cluster create 命令就可以看到
查看一个节点下管理哪些key?key * 可以看到所有键,dbsize 可以看到键的数量。
查看一个key下在哪个slot?在redis-cli中,使用 cluster keyslot keyname 就可以得到了。

注意:就算是节点/机器增加和减少,slot的个数是不会改变的,“key通过CRC运算然后取模16384得到槽序号”这个算法也是不会改变的,所以,三者联系中,key和slot的关系是永远不会改变,某个key永远只分配到某个slot上去(无论这个key的value如何改变,除非这个key的名称发生改变,但是没有这种操作),某个slot永远只管理某些key。但是,slot和节点的关系是会发生改变,如果节点新增或减少,但是slot的数量 16384 是不变的,从而 slot 会迁移,所以一个key会从一个机器上到了另外一个机器上。
slot对开发者不可见,开发者可见的只有 key 和 节点/机器,所以节点增加后减少,对于开发者而言,还需需要关注 一个key会从一个机器上到了另外一个机器上。
3.3 RedisCluster让相关的数据落到同一个节点上
问题:RedisCluster中,如何让相关的数据落到同一个节点上?这也是现实的业务需求,比如有一些 multi key 操作是不能跨节点的,例如用户 2673 的基本信息和金融信息?
回答:在 key 里面加入hash tag 即可。Redis 在计算槽编号时候,只会获取 之间字符串进行槽编号计算,这样由于上面两个不同的键, 里面的字符串是相同的,因此他们可以被计算出相同的槽。实践如下:

3.4 客户端重定向
问题:客户端怎么知道应该连接到哪台机器上?如果访问的数据不在当前节点上,怎么办?
127.0.0.1:7293> set aa aa1
(error) MOVED 1180 192.168.100.138:7291
回答:服务端返回MOVED,也就是根据 key 计算出来是slot不归当前端口管理,而是归属于 7591 端口管理,这个时候客户端应该更换连接端口,用 ./redis-cli -p 7291 操作,才会返回 OK。但是这样的会就需要客户端连接两次服务端。
其实,Jedis 等客户端会在本地维护一份(slot,node)的映射关系。大部分时间不需要重定向,所以叫 smart jedis (需要客户端的支持)。
Redis最常用的三个客户端:Jedis Lettuce Redission
其中,使用redisTemplate的就是三种中选择一个使用,根据redisTemplate的不同版本选择不同的。
3.5 数据迁移
问题:新增或下线了Master节点,数据怎样迁移(就是重新分配slot)?
回答:因为key和slot的关系是永远不变的,当新增了节点的时候,需要把原有的slot分配给新的节点负责,并将相关的数据迁移过来(就是将相关的key迁移过来),内部的迁移 redis 的设计者搞好了的,其实对于开发者来说,就是一行命令的事,如下:
# 步骤1:新增一个7297端口的redis(先启动一个7297端口的redis,再使用下面这条命令加入到 RedisCluster 即可)
./redis-cli --cluster add-node 127.0.0.1:7291 127.0.0.1:7297
# 步骤2:由于新增一个7297端口的redis还没有任何哈希槽,不能分布数据,所以在原来的人一个节点上执行
./redis-cli --cluster reshard 127.0.0.1:7291
# 输入需要分配的哈希槽的数据(比如500),和哈希槽的来源节点(可以输入all或者id),就是这500个槽从之前哪个节点拿来。
3.6 Redis Cluster 故障转移/高可用
问题:只有主节点可以写操作,如果一个主节点宕机,从节点怎样变成主节点?
回答:当从节点发现自己的主节点变成 fail 状态的时候,便尝试进行 failover,期望自己成为新的主节点。由于挂掉的主节点可能有多个从节点,从而存在多个从节点竞争成为主节点的过程,过程如下:
1.slave发现自己的master变为FAIL
2.将自己记录的集群currentEpoch1,并广播FAILOVER_AUTH_REQUEST信息
3.其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个epoch只发送一次ack
4.尝试failover的slave收集FAILOVER_AUTH_ACK
5.超过半数后变成新Master
6.广播Pong通知其他集群节点。
小结:RedisCluster既能是实现主从复制,又能实现主从切换,相当于集成Replication 和Sentinel 的功能。
3.7 Redis Cluster 特点
Redis Cluster 特点
- 无中心架构。
- 数据按照slot存储分布在多个节点,节点间数据共享,可动态调整数据分布。
- 可扩展性,可线性扩展到1000个节点(官方推荐不超过1000个),节点可动态添或删除。
- 高可用性,部分节点不可用时,集群仍可用。通过增Slave做standby数据副本,能够实现故障自动failover,节点之间通过gossip协议交换状态信息,用投票机制完成Slave到Master的角色提。
- 降低运维成本,提高系统的扩展性和可用性。
四、尾声
redisCluster的引入解决了 高并发、高可用、大数据量 三个问题。
三主结构:使用三个机器来存放所有数据,保证大数据量水平扩展;
三主就有三从:一个主节点就带有一个从节点,保证了主从复制/读写分离,保证高并发;
三主就有三从:一个主节点就带有一个从节点,主节点宕机后从节点顶上,保证高可用。
以上是关于Redis_13_Redis集群实现RedisCluster应对大数据量的主要内容,如果未能解决你的问题,请参考以下文章
Redis_10_Redis集群实现RedisCluster应对大数据量
Redis_12_Redis集群实现Sentinel哨兵应对高可用
Redis_09_Redis集群实现Sentinel哨兵应对高可用