(已解决)多卡训练时报错RuntimeError: grad can be implicitly created only for scalar outputs
Posted CSU迦叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(已解决)多卡训练时报错RuntimeError: grad can be implicitly created only for scalar outputs相关的知识,希望对你有一定的参考价值。
背景
博主第一次使用多卡训练,在程序中添加了如下代码
# 包装为并行风格模型
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = '0,1,2,3'
device_ids = [0, 1, 2, 3]
model.to("cuda:0")
model = torch.nn.DataParallel(model, device_ids=device_ids)报错关键信息
1. UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
分析: 使用model = torch.nn.DataParallel(model, device_ids=device_ids)导致
2. loss.backward()
3. raise RuntimeError("grad can be implicitly created only for scalar outputs")
问题出在反向传播时数据的格式标量向量不一致(具体怎样还没搞清楚)
解决办法
将loss.backward()改为loss.backward(torch.ones(loss.shape).to("cuda:0"))
效果
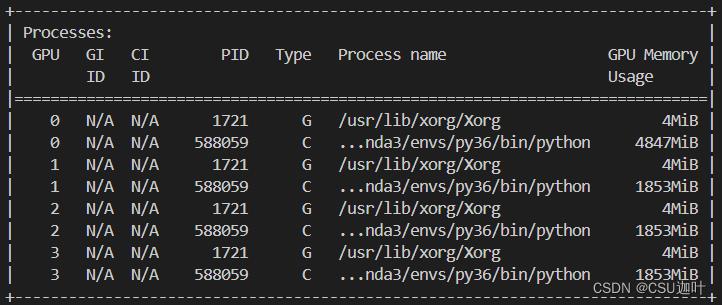
在命令行输入watch -n 1 nvidia-smi可以看到四张卡都在使用,但是第一站明显占显存多于其余三张
以上是关于(已解决)多卡训练时报错RuntimeError: grad can be implicitly created only for scalar outputs的主要内容,如果未能解决你的问题,请参考以下文章