讲清python开发必懂的8种数据结构
Posted 程序员石磊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了讲清python开发必懂的8种数据结构相关的知识,希望对你有一定的参考价值。

在解决现实世界的编码问题时,雇主和招聘人员都在寻找运行时和资源效率。
知道哪个数据结构最适合当前的解决方案将提高程序的性能,并减少开发所需的时间。出于这个原因,大多数顶级公司都要求对数据结构有很深的理解,并在编码面试中对其进行深入的考察。
下面是我们今天要讲的内容:
- 什么是数据结构?
- 在Python中数组
- 队列在Python中
- 栈在Python中
- Python中的链表
- Python中的循环链表
- Python种的树
- 图
- Python中的哈希表
- 接下来学什么
什么是数据结构?
数据结构是用于存储和组织数据的代码结构,使修改、导航和访问信息变得更加容易。数据结构决定了如何收集数据、我们可以实现的功能以及数据之间的关系。
数据结构几乎用于计算机科学和编程的所有领域,从操作系统到前端开发,再到机器学习。
数据结构有助于:
- 管理和利用大型数据集
- 从数据库中快速搜索特定数据
- 在数据点之间建立清晰的分层或关系连接
- 简化并加快数据处理
数据结构是高效、真实解决问题的重要构建模块。数据结构是经过验证和优化的工具,为您提供了一个简单的框架来组织您的程序。毕竟,你没有必要每次都重新制作轮子 (或结构)。
每个数据结构都有一个最适合解决的任务或情况。Python有4个内置的数据结构、列表、字典、元组和集合。这些内置数据结构带有默认方法和幕后优化,使其易于使用。
- List:类似数组的结构,允许将一组相同类型的可变对象保存为变量。
- 元组:元组是不可变的列表,意味着元素不能被更改。它是用圆括号声明的,而不是方括号。
- Set:集合是无序的集合,这意味着元素是没有索引的,并且没有集合序列。它们用花括号声明。
- 字典(dict):类似于其他语言中的hashmap或哈希表,字典是键/值对的集合。用空花括号初始化空字典,并用冒号分隔的键和值填充。所有键都是唯一的、不可变的对象。
现在,让我们看看如何使用这些结构来创建面试官想要的所有高级结构。
Arrays (Lists) in Python
Python没有内置数组类型,但您可以为所有相同的任务使用列表。数组是以相同名称保存的相同类型的值的集合。
数组中的每个值都被称为“元素”,索引表示其位置。您可以通过使用所需元素的索引调用数组名称来访问特定的元素。您还可以使用len()方法获取数组的长度。

不像Java这样的编程语言在声明后有静态数组,Python的数组在添加/减去元素时自动伸缩。
例如,可以使用append()方法在现有数组的末尾添加一个额外的元素,而不是声明一个新数组。
这使得Python数组特别易于使用和动态适应。
cars = ["Toyota", "Tesla", "Hyundai"]
print(len(cars))
cars.append("Honda")
cars.pop(1)
for x in cars:
print(x)
优势:
- 创建和使用数据序列简单
- 自动缩放以满足不断变化的尺寸要求
- 用于创建更复杂的数据结构
缺点:
- 未针对科学数据进行优化 (与NumPy的数组不同)
- 只能操作列表的最右边
应用:
- 相关值或对象的共享存储,即myDogs
- 通过循环访问
- 数据结构的集合,例如元组列表
Python中的常见数组面试问题
- 从列表中删除偶数整数
- 合并两个排序列表
- 在列表中找到最小值
- 最大总和子列表
- 打印所有元素
Python中的队列
队列是一种线性数据结构,以 “先进先出” (FIFO) 顺序存储数据。与数组不同,您不能按索引访问元素,而只能提取下一个最旧的元素。这使得它非常适合订单敏感任务,如在线订单处理或语音邮件存储。
你可以把在杂货店排队; 收银员不会选择下一个结账的人,而是会处理排队时间最长的人。
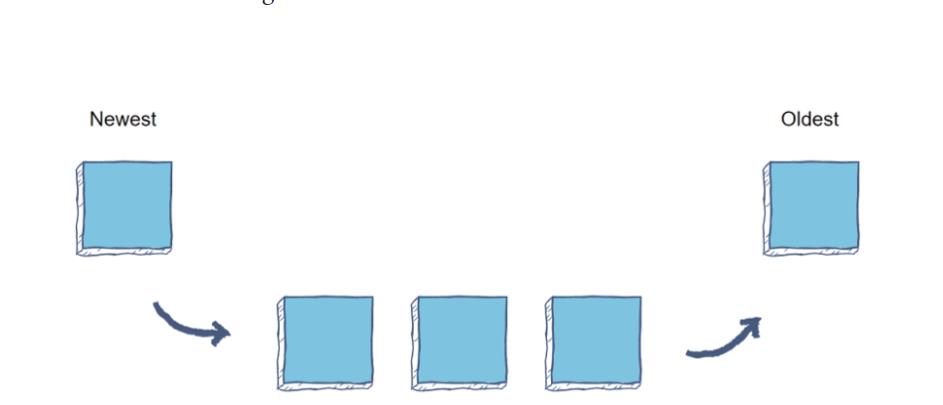
我们可以使用带有append()和pop()方法的Python列表来实现队列。然而,这是低效的,因为当您向开始添加新元素时,列表必须按一个索引移动所有元素。
相反,最好的做法是使用Python的collections模块中的deque类。deque对追加和弹出操作进行了优化。deque实现还允许创建双端队列,该队列可以通过popleft()和popright()方法访问队列的两端。
from collections import deque
# Initializing a queue
q = deque()
# Adding elements to a queue
q.append('a')
q.append('b')
q.append('c')
print("Initial queue")
print(q)
# Removing elements from a queue
print("\\nElements dequeued from the queue")
print(q.popleft())
print(q.popleft())
print(q.popleft())
print("\\nQueue after removing elements")
print(q)
# Uncommenting q.popleft()
# will raise an IndexError
# as queue is now empty
优点:
- 按时间顺序自动处理数据
- 根据数据量大小自动缩放
- deque类的时间效率高
缺点:
- 只能访问两端的数据
应用程序:
- 打印机或CPU核心等共享资源的操作
- 作为批处理系统的临时存储
- 为同等重要的任务提供一个简单的默认顺序
Python中的常见队列面试问题
- 反转队列的前k个元素
- 使用链表实现队列
- 使用队列实现堆栈
Python中的栈
栈是一种连续的数据结构,充当队列的后进先出(LIFO)版本。插入到堆栈中的最后一个元素被认为是堆栈的顶部,并且是唯一可访问的元素。要访问中间元素,必须首先删除足够多的元素,使所需的元素位于堆栈顶部。
许多开发者将堆栈想象成一堆餐盘;你可以把盘子加到或移到盘子堆的顶部,但必须移动整个盘子堆才能把一个放在底部。

添加元素称为push,删除元素称为pop。你可以在Python中使用内置的列表结构来实现栈。对于列表实现,推操作使用append()方法,弹出操作使用pop()。
stack = []
# append() function to push
# element in the stack
stack.append('a')
stack.append('b')
stack.append('c')
print('Initial stack')
print(stack)
# pop() function to pop
# element from stack in
# LIFO order
print('\\nElements popped from stack:')
print(stack.pop())
print(stack.pop())
print(stack.pop())
print('\\nStack after elements are popped:')
print(stack)
# uncommenting print(stack.pop())
# will cause an IndexError
# as the stack is now empty
优势:
- 提供应用程序无法实现的后进先出数据管理:
- 自动缩放和对象清理
- 简单可靠的数据存储系统
缺点:
- 堆栈内存有限
- 堆栈上的对象太多会导致堆栈溢出错误
应用:
- 用于开发高吞吐量的系统
- 内存管理系统首先使用堆栈来处理最近的请求
- 对括号匹配等问题有帮助
Python中的常见堆面试问题
- 使用栈实现队列
- 使用栈计算后缀表达式
- 使用栈获取下一个最大元素
- 使用栈创建min() 函数
Python中的链表
链表是数据的顺序集合,使用每个数据节点上的关系指针链接到列表中的下一个节点。
与数组不同,链表在列表中没有目标位置。相反,它们基于节点串联起来。
链表中的第一个节点称为头节点,最后一个节点称为尾节点,其中尾节点的next指向为null。
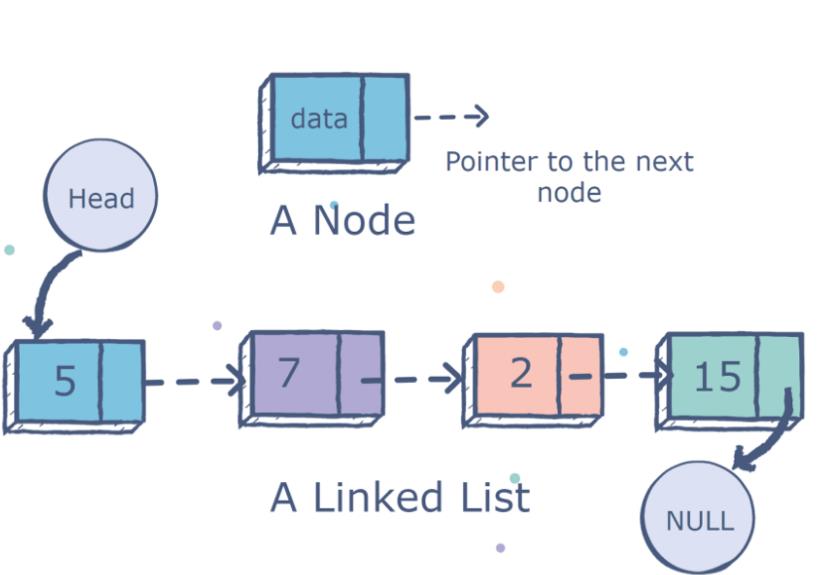
链表可以是单链,也可以是双链,这取决于每个节点是只有一个指向下一个节点的指针,还是还有一个指向前一个节点的指针。
你可以把链表想象成一条链;单个链接只与相邻的链接有一个连接,但所有链接一起形成一个更大的结构。
Python没有链表的内置实现,因此需要实现一个Node类来保存数据值和一个或多个指针。
class Node:
def __init__(self, dataval=None):
self.dataval = dataval
self.nextval = None
class SLinkedList:
def __init__(self):
self.headval = None
list1 = SLinkedList()
list1.headval = Node("Mon")
e2 = Node("Tue")
e3 = Node("Wed")
# Link first Node to second node
list1.headval.nextval = e2
# Link second Node to third node
e2.nextval = e3
优势:
- 新元素插入和删除更高效
- 比数组更易于重组
- 高级数据结构 (如图形或树)都是基于链表的
缺点:
- 每个数据点的指针存储增加了内存使用量
- 必须始终从头节点遍历链表以查找特定元素
应用:
- 高级数据结构的构建块
- 需要频繁添加和删除数据的解决方案
Python中的常见链表面试问题
- 打印给定链表的中间元素
- 从已排序的链表中删除重复元素
- 检查单链接列表是否为回文
- 合并K排序链表
- 查找两个链表的交点
Python中的循环链表
标准链表的主要缺点是,您总是必须从Head节点开始。循环链表通过将Tail节点的空指针替换为指向Head节点的指针来解决这个问题。当遍历时,程序将跟随指针,直到到达它开始的节点。
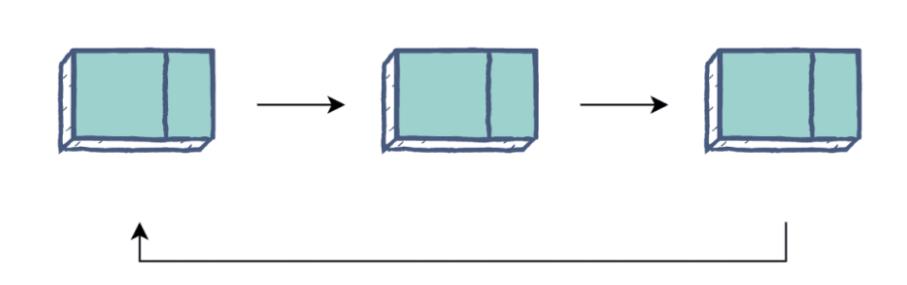
这种设置的优点是,您可以从任何节点开始遍历整个列表。它还允许您通过设置结构中所需的循环次数来使用链表作为一个可循环结构。循环链表对于长时间循环的进程非常有用,比如操作系统中的CPU分配。
优点:
- 可以从任何节点开始遍历整个列表
- 使链表更适合循环结构
缺点:
- 如果没有空标记,将更难找到列表的Head和Tail节点
应用:
- 定期循环解决方案,如CPU调度
Python中常见的循环链表面试问题
- 在链表中检测循环
- 反转循环链表
- 给定大小的组中的反向圆形链表
Python中的树形结构
树是另一种基于关系的数据结构,专门用于表示层次结构。与链表一样,它们也被Node对象填充,Node对象包含一个数据值和一个或多个指针,用于定义其与直接节点的关系。
每棵树都有一个根节点,所有其他节点都从根节点分支出来。根节点包含指向它正下方所有元素的指针,这些元素被称为它的子节点。这些子节点可以有它们自己的子节点。二叉树的节点不能有两个以上的子节点。
在同一层上的任何节点都称为同级节点。没有连接子节点的节点称为叶节点。
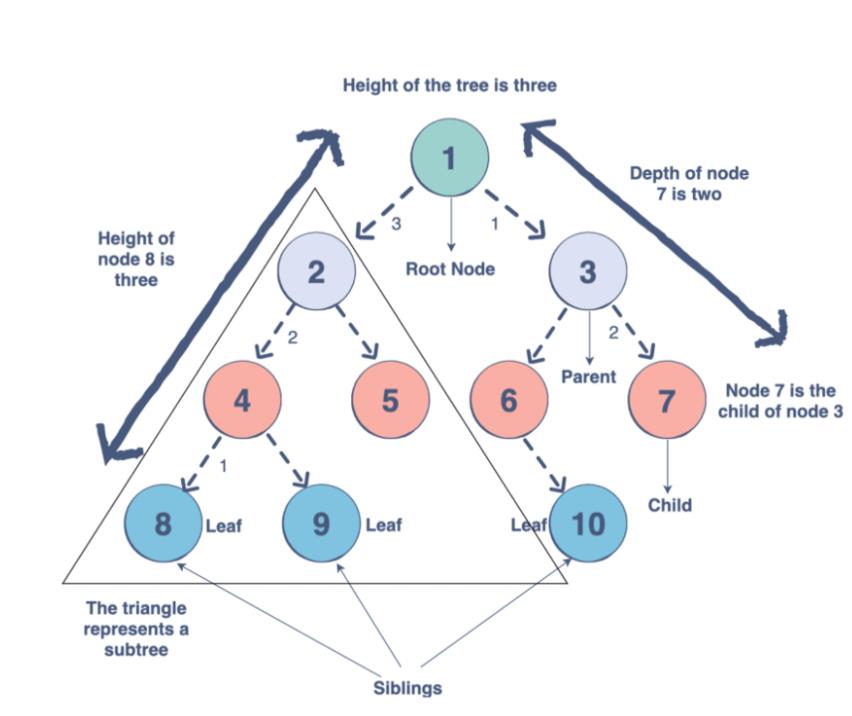
二叉树最常见的应用是二叉搜索树。二叉搜索树擅长于搜索大量的数据集合,因为时间复杂度取决于树的深度而不是节点的数量。
二叉搜索树有四个严格的规则:
- 左子树只包含元素小于根的节点。
- 右子树只包含元素大于根的节点。
- 左右子树也必须是二叉搜索树。他们必须以树的“根”来遵循上述规则。
- 不能有重复的节点,即不能有两个节点具有相同的值。
lass Node:
def __init__(self, data):
self.left = None
self.right = None
self.data = data
def insert(self, data):
# Compare the new value with the parent node
if self.data:
if data < self.data:
if self.left is None:
self.left = Node(data)
else:
self.left.insert(data)
elif data > self.data:
if self.right is None:
self.right = Node(data)
else:
self.right.insert(data)
else:
self.data = data
# Print the tree
def PrintTree(self):
if self.left:
self.left.PrintTree()
print( self.data),
if self.right:
self.right.PrintTree()
# Use the insert method to add nodes
root = Node(12)
root.insert(6)
root.insert(14)
root.insert(3)
root.PrintTree()
优点:
- 用于表示层次关系
- 动态大小,规模巨大
- 快速插入和删除操作
- 在二叉搜索树中,插入的节点被立即排序。
- 二叉搜索树的搜索效率高;长度只有O(高度)。
缺点:
- 修改或“平衡”树或从已知位置检索元素的时间开销为O(logn)
- 子节点在父节点上没有信息,并且很难向后遍历
- 仅适用于排序的列表。未排序的数据退化为线性搜索。
应用:
- 非常适合存储分层数据,如文件位置
Python中的常见树面试问题
- 检查两棵二叉树是否相同
- 实现一个二叉树的层次顺序遍历
- 打印二叉搜索树的周长
- 对路径上的所有节点求和
- 连接二叉树的所有兄弟
python中的图
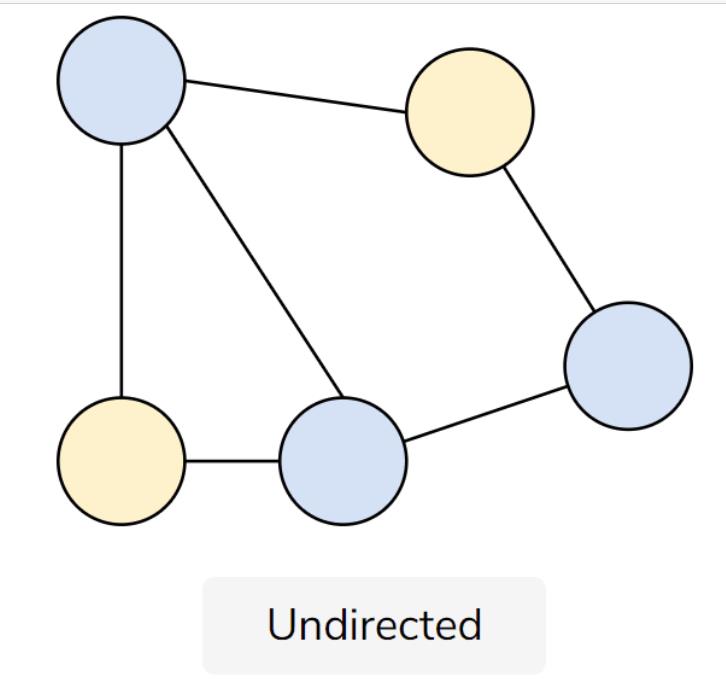
图是一种数据结构,用于表示数据顶点(图的节点)之间关系的可视化。将顶点连接在一起的链接称为边。
边定义了哪些顶点被连接,但没有指明它们之间的流向。每个顶点与其他顶点都有连接,这些连接以逗号分隔的列表形式保存在顶点上。
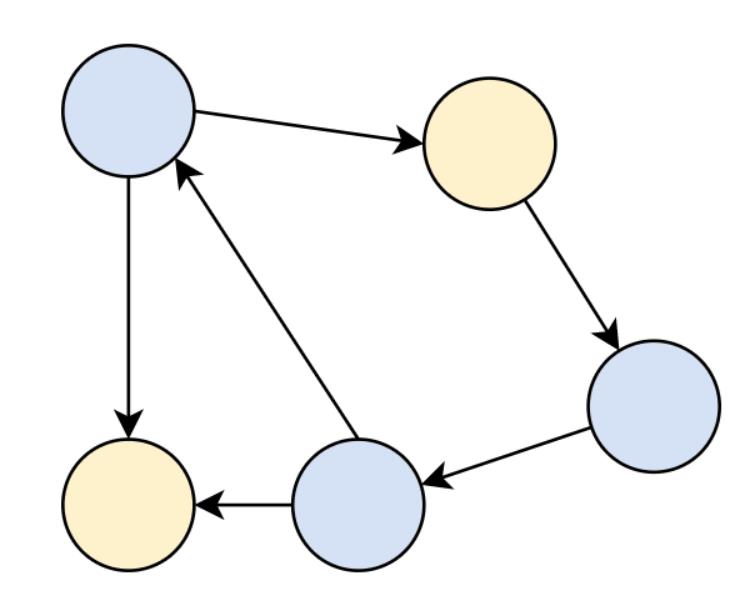
还有一种特殊的图叫做有向图,它定义了关系的方向,类似于链表。在建模单向关系或类似流程图的结构时,有向图很有帮助。
它们主要用于以代码形式传达可视化的网络结构网络。这些结构可以为许多不同类型的关系建模,比如层次结构、分支结构,或者只是一个无序的关系网络。图形的通用性和直观性使它们成为数据科学的宠儿。
当以纯文本形式编写时,图具有顶点和边的列表:
V = a, b, c, d, e
E = ab, ac, bd, cd, de
在Python中,图的最佳实现方式是使用字典,每个顶点的名称作为键,边列表作为值。
# Create the dictionary with graph elements
graph = "a" : ["b","c"],
"b" : ["a", "d"],
"c" : ["a", "d"],
"d" : ["e"],
"e" : ["d"]
# Print the graph
print(graph)
优点:
- 通过代码快速传达视觉信息
- 可用于建模广泛的现实世界问题
- 语法学习简单
缺点:
- 在大型图中很难理解顶点链接
- 从图表中解析数据的时间昂贵
应用:
- 非常适合网络或类似网络的结构建模
- 曾为Facebook等社交网站建模
Python中的常见图形面试问题
- 在有向图中检测周期
- 在有向图中找到一个“母顶点”
- 计算无向图中的边数
- 检查两个顶点之间是否存在路径
- 求两个顶点之间的最短路径
Python中的哈希表
哈希表是一种复杂的数据结构,能够存储大量信息并有效检索特定元素。
此数据结构使用键/值对,其中键是所需元素的名称,值是存储在该名称下的数据。
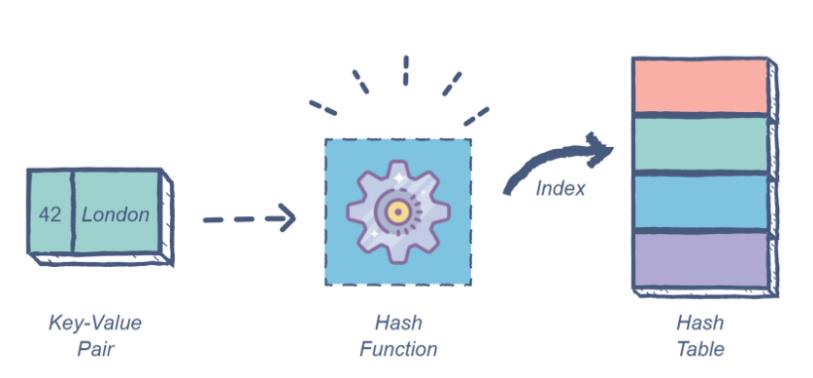
每个输入键都要经过一个哈希函数,该函数将其从初始形式转换为一个整数值,称为哈希。哈希函数必须始终从相同的输入产生相同的哈希,必须快速计算,并产生固定长度的值。Python包含一个内置的hash()函数,可以加速实现。
然后,该表使用散列来查找所需值(称为存储桶)的一般位置。然后,程序只需要在这个子组中搜索所需的值,而不必搜索整个数据池。
除了这个通用框架之外,根据应用程序的不同,哈希表也可能非常不同。有些可能允许来自不同数据类型的键,而有些可能有不同的设置桶或不同的散列函数。
下面是一个Python代码中的哈希表示例:
import pprint
class Hashtable:
def __init__(self, elements):
self.bucket_size = len(elements)
self.buckets = [[] for i in range(self.bucket_size)]
self._assign_buckets(elements)
def _assign_buckets(self, elements):
for key, value in elements: #calculates the hash of each key
hashed_value = hash(key)
index = hashed_value % self.bucket_size # positions the element in the bucket using hash
self.buckets[index].append((key, value)) #adds a tuple in the bucket
def get_value(self, input_key):
hashed_value = hash(input_key)
index = hashed_value % self.bucket_size
bucket = self.buckets[index]
for key, value in bucket:
if key == input_key:
return(value)
return None
def __str__(self):
return pprint.pformat(self.buckets) # pformat returns a printable representation of the object
if __name__ == "__main__":
capitals = [
('France', 'Paris'),
('United States', 'Washington D.C.'),
('Italy', 'Rome'),
('Canada', 'Ottawa')
]
hashtable = Hashtable(capitals)
print(hashtable)
print(f"The capital of Italy is hashtable.get_value('Italy')"
优点:
- 可以将任何形式的键隐藏为整数索引
- 对于大型数据集非常有效
- 搜索效率高
- 每次搜索的步骤数不变,添加或删除元素的效率不变
- 在Python 3中进一步优化
缺点:
- 哈希值必须是唯一的,两个键转换为相同的哈希值会导致冲突错误
- 碰撞错误需要对哈希函数进行全面修改
- 对于初学者来说很难构建
应用程序:
- 用于频繁查询的大型数据库
- 根据关键字检索的系统
Python中常见的哈希表面试问题
- 从头开始构建哈希表(不含内置函数)
- 找出两个加起来是k的数
- 为冲突处理实现开放寻址
- 使用哈希表检测列表是否循环
_学习愉快!
以上是关于讲清python开发必懂的8种数据结构的主要内容,如果未能解决你的问题,请参考以下文章