深度学习——深度学习中的梯度计算
Posted 格格巫 MMQ!!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习——深度学习中的梯度计算相关的知识,希望对你有一定的参考价值。
梯度下降在【机器学习基础】中已经总结了,而在深度学习中,由于模型更加复杂,梯度的求解难度更大,这里对在深度学习中的梯度计算方法进行回顾和学习。
本节主要是了解深度学习中(或者说是tensorflow中)梯度的计算是怎么做的。
- 计算图
在学习tensorflow中,我们知道tensorflow都是基于图来进行计算的,那么什么是计算图呢?
所谓计算图就是将一个function利用图的结构来进行表示。如图所示:

上面的图就表示a=f(b,c)这样一个方程,而图的节点表示变量,图的边表示操作(operation)。
再比如方程f=f(g(h(x)))这样一个方程,用计算图来表示:

之所以用计算图来表示方程,是因为图能够使得方程的结构更加清晰,计算顺序上一目了然,同时为后面的梯度提供了很大的便利性。接着往后看。
有了计算图,根据一个计算式,我们就可以构建出一张图出来,比如:
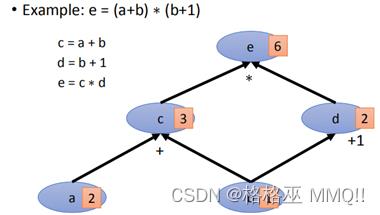
根据所建立的图,给定a=2,b=1,则可以顺着图结构顺利求出e。
- 计算图的链式求导法则
例子1:函数z=h(g(x)),按照上面的做法,将其变成计算图如图所示:
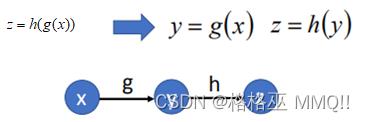
根据链式求导求dz/dx,z先对y求导,然后y再对x求导得到:

例子2:另一个更复杂的z=k(g(s), h(s))这样一个函数,求dz/ds,首先建立一张计算图:

根据链式求导法则,s和x、y均有关系,因此z对x求导,x再对s求导是一条路,然后z对y求导,y再对s求导另一条路,两条路相加得到:

上面就是链式求导法则,那么链式求导法则在图计算中如何应用呢,继续使用上面那个e=(a+b)*(b+1):
根据我们建立的计算图和链式求导法则,求de/db:
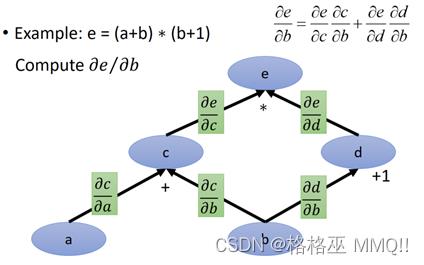
然后分别对每个边的导数进行计算:
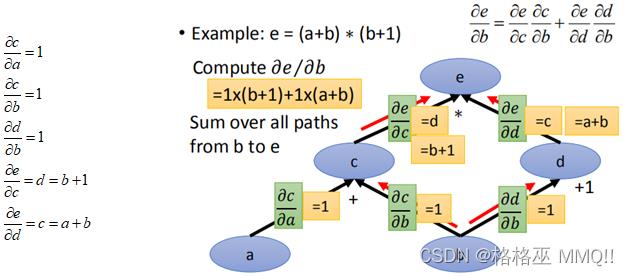
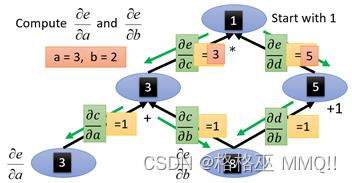
那么假如a=3,b=2,求e对b的导数,a、b代进上面的每条边上,将所要求的导数记为1,从1开始出发:

那么最后沿着红色的箭头一路计算b到e的路径就可以了(这里可以不用管节点的值):
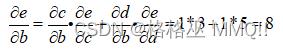
从这里可以看到,图计算在求导数的计算中非常便利且清晰。
那么这么对于梯度的求解有什么好处呢?我们可以用reverse mode,利用图计算,从顶端开始,向底部走:
还是如果求e对b的导数,这次从e开始走,e=1,然后向下走能够到达b的每一条路:
也就是图中绿色的箭头的方向,即为reverse mode。需要求e对a的导数,则就从e一路走到a就可以了
这里注意,反向的路径箭头必须是反向的,也就是只能沿着绿色的箭头能够到达a的路径,因此从e到a只有一条路:
下面再举一个例子:
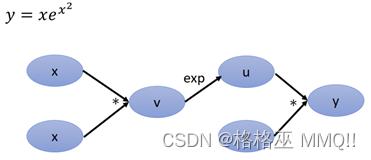
建立计算图后,然后为每个边补上对应的导数,这里需要注意,v=x2,那v对x的导数应该是2x,但是这里x*x相当于是两个变量,要区分对待,当做x1、x2:
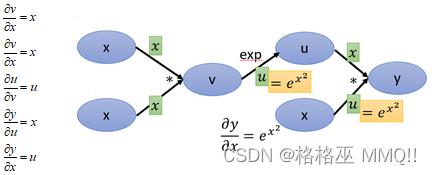
接下来求y对x的导数,沿着红色的箭头,一共有3条路径:

- 深度学习中的梯度计算
有了上面的计算图和反向求导,以及几个示例的说明,对于深度学习中的梯度计算就有了一个初步的雏形了。不过是在深度学习中的方程更加复杂而已。
我们只需要能够画出深度学习中的计算图,那么计算梯度也就水到渠成。
3.1 全连接网络的梯度计算
首先来看全连接神经网络,在【机器学习基础】中对反向传播的过程进行了描述,分为前向和后向两个方面:
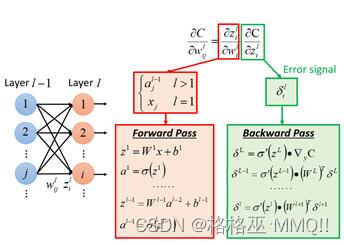
红色框中的正向传播用于求z对w的导数,绿色框的反向传播用于求loss对z的导数,二者相乘最终得到loss对w的导数。
而反向传播像是从loss开始,向输出层传递的一种“正向传播”过程:

根据全连接网络的正向传播过程,整个网络的从输入到输出的方程为:

于是,按照上面这个方程,全连接网络的计算图表示如下(假设只有2个隐藏层):

最终得到的y与真实的yhat计算loss,那么按照上面计算图以及导数计算的方法,则有:
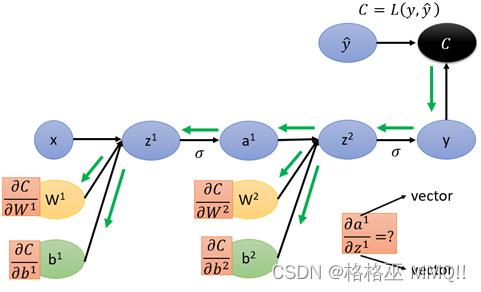
在计算每一部分导数之前,由于网络的输入和中间变量均为矩阵,这里需要了解Jacobian Matrix(雅克比矩阵):

y是21的矩阵,x是31的矩阵,那么y对x的导数:

行数是y原来的size,列数为原来x的size。比如:
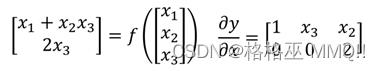
接下来回到全连接的计算图的梯度计算,使用reverse mode,从后向前一部分一部分来看:
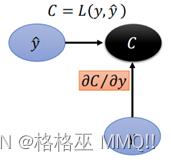
首先是loss C对y的导数,在计算loss时,采用cross entropy:
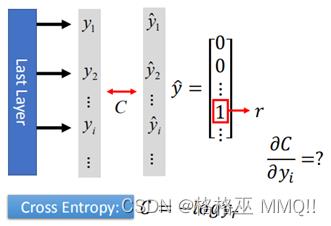
C是一个数,y是一个m1矩阵(m表示类别数量),那么根据Jacobian Matrix 知道C对y的导数为1m。
假设样本属于第r类,那么第r维=1,其他为0,因此用矩阵的形式计算:
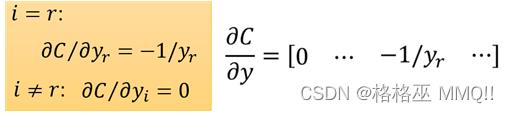
接下来看下一层:

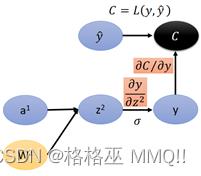
y对z2的导数,首先可以确定y对z2导数的形状,y为101,z2经过σ激活函数,形状不变,一次z2也是101的矩阵,那么y对z2的导数为一个方形;
而y=σ(z2),那么根据Jacobian Matrix,当yi是由zi求出来的元素才有值,其他y不是由z计算得来的那些都为0(因为二者根本没有关系)。

因此y对z2的导数是一个方形的对角矩阵。
然后继续到下一层:
z1是由w2和a1得到的:

首先看z2对a1的导数,a1是前一层的输出,那么有:
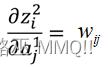
因此,z2对a1的导数就是W2。
然后是z2对W2的导数,z2是1m的矩阵,W2是一个mn的矩阵(n为上一层的输出维度),那么导数就是这样的:
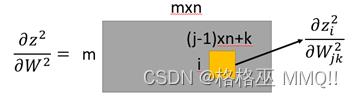
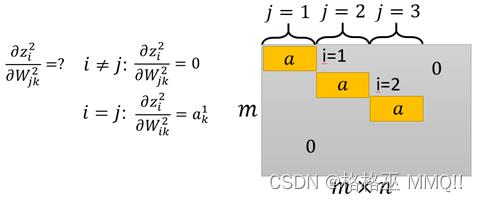
这个可以理解为矩阵中元素依旧是矩阵的形式,而其中当i=j时,z2(i)对w2(j)的导数为a1,i≠j时,z2i与w2j没有关系, 到时为0。于是:
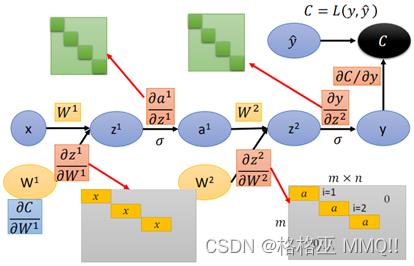
网络再继续往前,跟上述的过程基本一致,那么最后得到计算图的每一边上的导数:
那么此时可以求loss对任意参数的导数:
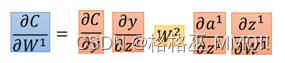
3.2 RNN中的梯度计算
RNN的梯度计算也一样是根据计算图来一步一步地对每一部分求导,然后再用reverse mode计算loss对各个参数的导数。RNN的基本结构如下:

对于每一部分,按照计算图的形式,正常的计算图应该是这样的:
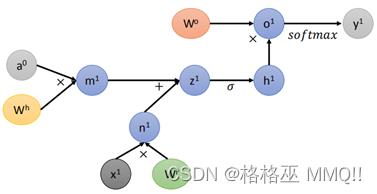
为方便计算和图的简洁性,将上图改为下面这样:

那么对于整个RNN网络的结构的计算图:

每一个时刻都要计算一个loss C,然后对于一个样本,要将所有时刻的C相加得到最终的loss。
有了计算图,然后计算每个边上的导数:
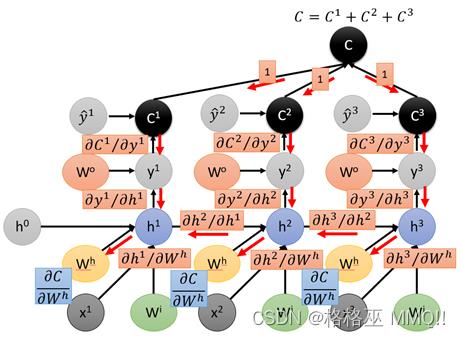
这里对于每条边的具体计算过程就不再展开了,接下来就可以求C对wh和C对wi的导数了:

这里需要注意的是,wh有3个,因此也是由三部分相加,而对于每一个wh,又有可能有多条路径,如①号wh,一共有三条路径:
C→C1→y1→h1→wh
C→C2→y2→h2→h1→wh
C→C3→y3→h3→h2→h1→wh
②号wh只有两条路径,③号wh有一条路径。注意这里的路径都是只能沿着红色箭头的方向行进到达wh的路径。
最终得到三部分wh的导数,然后进行相加:

这样就完成了RNN的梯度的计算。在tensorflow中就是这么运作的。
以上是关于深度学习——深度学习中的梯度计算的主要内容,如果未能解决你的问题,请参考以下文章