数据挖掘百度机器学习-数据挖掘-自然语言处理工程师 2023届校招笔试详解
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘百度机器学习-数据挖掘-自然语言处理工程师 2023届校招笔试详解相关的知识,希望对你有一定的参考价值。
笔试时间;2022年9月13日
1 不定项选择题
1、算法分析之常用符号大O、小o、大Ω符号、大Θ符号、w符号
O: 表示上界,小于等于的意思。渐进上界
o:表示上界,小于的意思。表示一个函数渐进地小于另一个函数,没有等于
Ω \\Omega Ω:表示下界,大于等于的意思。渐进下界
Θ \\Theta Θ:等于的意思。是大O符号和大Ω符号的结合,既是上界也是下界相当于两者的结合
ω \\omega ω:表示下界,大于的意思。
2、java类之间的关系
依赖、关联、聚合、组合、继承、实现
3、不属于抽样的是
A. 渐进抽样
B.单纯随机抽样
C. 分层抽样
D. 忘了
答案:D
解析:
常见的抽样方法:
1 有放回的简单随机抽样2 无放回的简单随机抽样
3 分层抽样
4 渐进抽样:在抽样方法中,当合适的样本容量很难确定时,可以使用的抽样方法是渐进抽样。
举个例:
比如,使用渐进抽样学习一个预测模型,预测模型的准确率会随着样本容量的增加而增大,直到某一点之后趋于稳定,此时的样本容量为适合的样本容量,我们可以选取接近当前容量的其它样本,估计出与稳定点的接近程度,从而停止抽样。
4、 素数的判断,代码
bool isprime(int a)
if (a == 2)return true;
//这一行是题目要求填写的
if (a % 2 == 0) return false;
int x = sqrt(a);
for (int i = 2; i <= x; ++i)
if (a%i == 0)return false;
return true;
5、KMP 算法初始化Next数组,主串S= ‘aaab’,则next是?
答案:0 1 2 2
解析:
next数组的值是代表着字符串的前缀与后缀相同的最大长度,(不能包括自身)
举例理解,模式串: ABABAA

6、相关系数是描述变量之间的什么量
线性相关程度的量
7、不属于基于回归文本检测的方法是
A. EAST
B.textbox
C.CTPN
D. MSR
答案:D
解析:
基于回归的文本检测方法:TextBoxes、 CTPN、TextBoxes++、EAST、MOST、CTD、LOMO、Contournet、PCR
基于分割的文本检测方法:Pixellink、MSR、PSNET、Seglink++、PAN、PCENet、DBNet
参考:http://t.csdn.cn/SOVHT
8、 11位号码,前10位正确,最后一位不确定,则三次都没有播通的概率是多少?
答案:0.7
解析:
P = 9 10 × 8 9 × 7 8 = 0.7 \\frac910×\\frac89×\\frac78 = 0.7 109×98×87=0.7
9、如果程序中没有显式使用可见性修饰符,允许某包P中的类C访问的有?
A、P中的。。。
答案:
解析:
四个可⻅性修饰符:private 、protected 、internal 和public。如果没有显式指定修饰符的话,默认可⻅性是 public
如果你声明为 private,它只会在声明它的文件内可⻅
如果你声明为 internal,它会在相同模块内随处可⻅
protected 不适用于顶层声明
10、F检验F值越大,以下哪个正确?
A. 相关系数越小
B. 随机误差越大
C.因变量与自变量之间的关系越大
D. 至少有一个自变量与因变量关系显著
答案:C,D
解析
F值表示回归模型的方差与残差的比值,即F越大表示残差越小,模拟的精度越高,相关系数越大,随机误差越小。
回归模型的总体显著性检验,就是检验全部解释变量对被解释变量的共同影响是否显著。F检验不显著时,就要考虑非线性的模型了。
11、基于像素进行分组反映出文本的语义信息,是什么方法?
答案:基于图像像素分割的文本检测方法
Pixellink采用分割的方法解决文本检测问题,分割对象为文本区域,将同属于一个文本行(单词)中的像素链接在一起来分割文本,直接从分割结果中提取文本边界框,无需位置回归就能达到基于回归的文本检测的效果。
12、查看已经安装了ssh服务相关的所有软件包 命令
rpm -qa | grep ssh
13、在数据搜集部分 ,需要执行哪些任务?
14、选择排序21,89,35,47,74,三趟排序后的结果是?
答案:21,35,47,89,74
解析:
选择排序是每趟选择最小的进行排序。
15、有集合S= D,R ,D= 甲,乙,丙,丁,戊,求表示顺序栈的关系集合为?
16、MLP中,输入层10个神经元,隐藏层5个神经元,输出层一个神经元,则输入输出的矩阵大小是?
答案:10×5,5×1
17、页面走向为:4,3,2,1,4,3,5,4,3,2,1,5,使用最佳置换策略,计算缺页率,分配的物理块数量为4
最初 n 个物理块为空时,依次插入的 n 次页面也算作缺页
访问页面的总数即为题目给出的页面走向的总个数
OPT算法:被换出的页面将是最长时间内不再被访问(往后看)
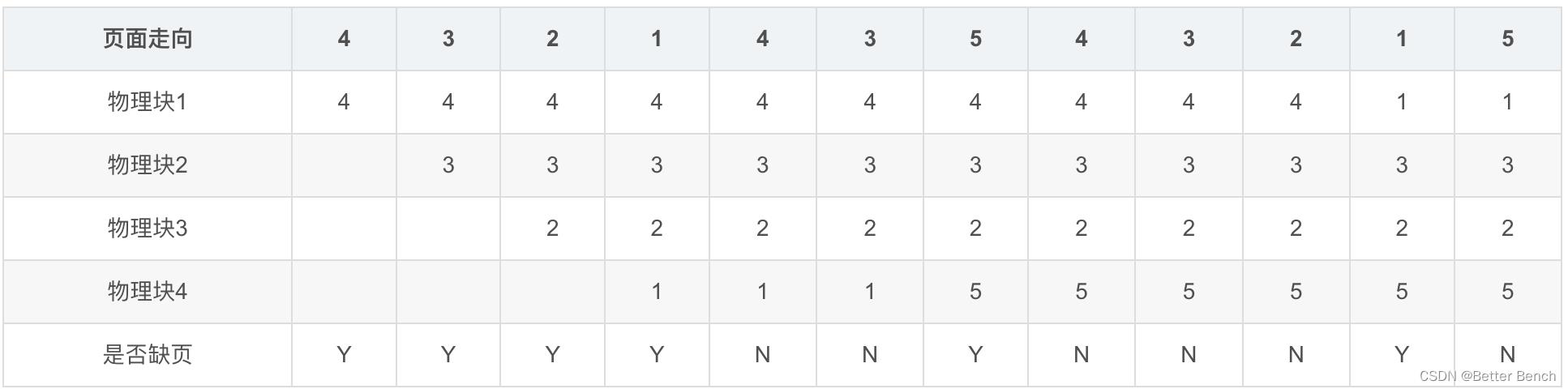
缺页次数为6次,访问页面的总数为12,缺页率为6/12
18、java中math.random()的范围是多少?
答案:[0,1),左闭右开
19、UDP中传输层的作用是?
答案:传输层提供逻辑连接的建立、传输层寻址、数据传输、传输连接释放、流量控制、拥塞控制、多路复用和解复用、崩溃恢复等服务。
20、哈希表中,使用链地址法解决冲突,关键字列表为6,1,10,14,68,7,84,27,55,24,23,79,哈希表长16,key=13时解决冲突的次数是多少?
答案:0次
解析:没有哪个关键字的key%16的余数是13。
注意:平均查找长度为(每个元素的链表长度之和除以总的元素个数)
21、如图所示,特征值较大的特征向量是?
A.横轴
B.纵轴
C.红色的线
D.蓝色的线
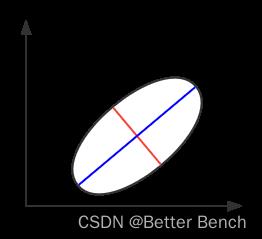
我猜是PCA降维的知识点
2 编程题
1、购买两款游戏,第一款游戏中共有n个关卡,通过第i关需要花费a_j的时间,第二款游戏共有m个关卡,通过第i关需要b_j的时间,两款游戏都不允许跳过关卡,必须通过第i关,才能继续挑战第i+1关,在游戏时长不超过t的情况下,最多可以通过多少关
第一行三个整数,n,m.t
第二行,输入n个数,a_1,…,a_n
第三行,输入m个数,b_1,…,b_m
输出最多能通过的关卡数
示例:
5 3 15
1 3 2 9 1
4 6 1
输出5
没有做出来
2、小明小红玩排序游戏,共有n个士兵,拍成一列,第i个士兵的战斗力为 h i h_i hi,两个人给他们排序
小明,小红二人共进行了m次操作,小明的每次操作都选择一个数,将前k个士兵按战斗力从小到大排序,小红的每次操作选择一个数k,将前k个士兵按战斗力从大到小排序
问所有操作结束后,从前往后每个士兵的战斗力是多少?
输入
第一行两个整数n,m,士兵数量和操作次数
第二行n个整数,代表从前往后每个士兵的战斗力
接下来m行按顺序给出所有操作,每行有两个整数,t.k,t=1代表是小明的操作,,否则是小红的操作,k代表对前K个士兵进行排序
输出n个整数,代表操作后的战斗力
在本地调试通过,但是在线上没有通过,通过率为0
n,m = input().split()
ss = input()
s = [int(i) for i in ss.split()]
for i in range(int(m)):
name,k = input().split()
tmp = s[0:int(k)]
if name =='1':
tmp.sort()
else:
tmp.sort(reverse=True)
s = tmp+s[int(k):]
print(s)
以上是关于数据挖掘百度机器学习-数据挖掘-自然语言处理工程师 2023届校招笔试详解的主要内容,如果未能解决你的问题,请参考以下文章
书单|机器学习数据挖掘和自然语言处理,机器学习工程师和数据科学家最应该读的16本书