TorchServe部署HuggingFace文本生成模型
Posted Alex_996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TorchServe部署HuggingFace文本生成模型相关的知识,希望对你有一定的参考价值。
模型训练完毕后,为了能够让前后端调用,都需要部署上线,提供一个可调用的Restful接口。
最近正好在做一个中文文本生成的模型,效果还不错,打算上线,本来研究了半天的TensorFlow Serving,但是最后实在没搞定,太麻烦了,今天换了TorchServe,一天就搞定了,PyTorch yyds!!!
模型准备
本次演示用的模型为IDEA开源的 闻仲-GPT2-100M,这个是一个用于文本生成的模型,能够根据提供的句子进行续写。

训练与保存
一般为了能够让模型更好的应用到不同业务场景,都需要使用专业的数据进行微调,然后重新保存。
from transformers import GPT2Tokenizer, GPT2LMHeadModel
hf_model_path = "IDEA-CCNL/Wenzhong-GPT2-110M"
tokenizer = GPT2Tokenizer.from_pretrained(hf_model_path)
model = GPT2LMHeadModel.from_pretrained(hf_model_path)
# 假设经过了微调
model.save_pretrained("./saved_model/")
经过微调之后,保存到当前目录的saved_model文件夹下,可以发现生成了两个文件:

请求处理
然后我们需要编写一个请求处理文件handler.py:
class TransformersGpt2Handler(BaseHandler, ABC):
def initialize(self, ctx):
pass
def preprocess(self, requests):
pass
def inference(self, data, *args, **kwargs):
pass
def postprocess(self, inference_output):
pass
这个文件主要包含四个部分,首先initialize函数用于初始化,配置device、加载tokenizer、加载模型等工作,其次preprocess函数用于处理http请求,拿到请求体内容,进行编码等操作,然后inference就是用于模型推理的函数,最后postprocess函数用于处理模型推理的结果,比如进行解码等操作。
模型打包
编写完了处理函数之后,我们就需要将这模型文件和处理文件通过torch-model-archiver打包成Torch模型存档文件(.mar文件)。
torch-model-archiver --model-name gpt2 --version 1.0 --serialized-file saved_model/pytorch_model.bin --handler ./torchserve_handler.py --extra-files "saved_model/config.json"
mkdir model_store && mv gpt2.mar model_store
这一步大概需要几分钟的时间,并不是卡住了。
OK,到现在为止,所有的模型准备工作就完成了,接下来就要通过TorchServe部署了。
Docker TorchServe部署
获取TorchServe镜像
首先就是要拉一下TorchServe的镜像嘛,我这用的是GPU版本:
docker pull pytorch/torchserve:latest-gpu
Docker镜像的详细内容可以参考TorchServe的的官网文档。
加载模型
然后就是将模型加载到TorchServe容器中并且运行起来即可。
docker run --rm -it -d --name gpt2 --gpus '"device=4"' -p 18080:8080 -p 18081:8081 -v $pwd/model_store:/home/model-server/model-store pytorch/torchserve:latest-gpu
这里指定了使用第4块GPU,然后将模型文件映射进去,还有端口的对应也制定好了。
但现在容器内还没有安装transformers,直接请求会报错,所以还需要手动安装一下:
docker exec gpt2 pip install transformers
注册模型
此时已经将模型映射到容器内了,但是还没有注册到TorchServe,还需要通过两个命令注册一下模型。
curl -X POST "http://localhost:18081/models?url=gpt2.mar"
curl -X PUT "http://localhost:18081/models/gpt2?min_worker=1"
请求模型
这样我们的模型就部署完啦,直接请求试试。
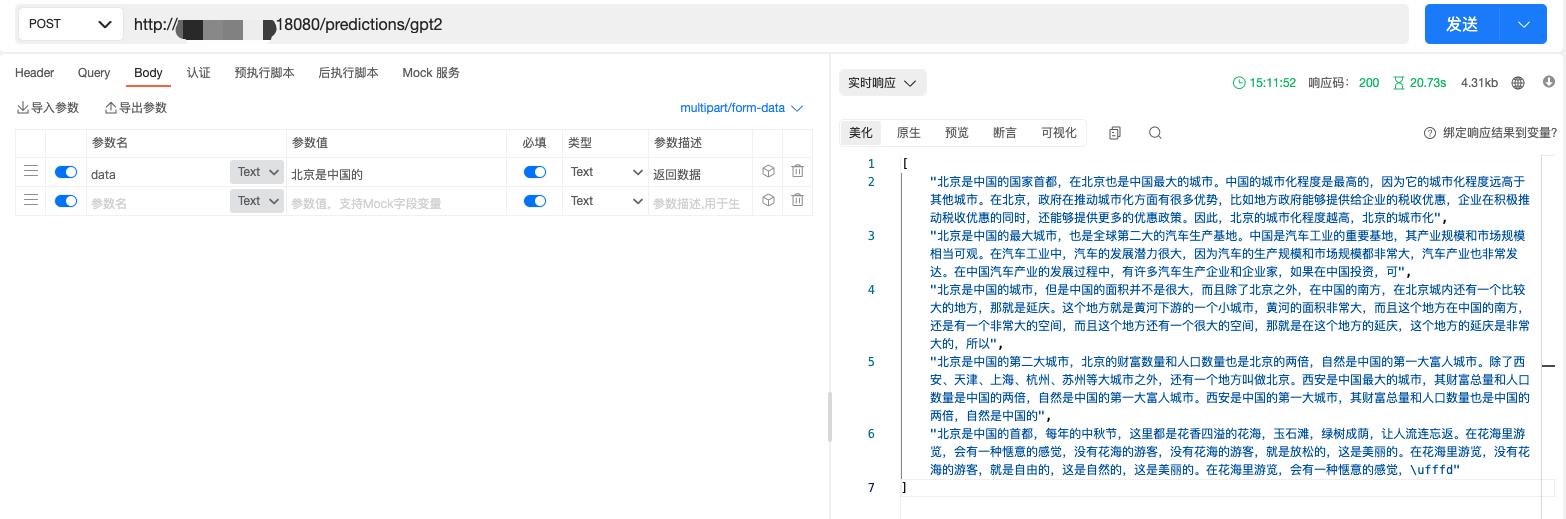
以上是关于TorchServe部署HuggingFace文本生成模型的主要内容,如果未能解决你的问题,请参考以下文章