技术分析 | 浅析MySQL与ElasticSearch的组合使用
Posted 老叶茶馆_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术分析 | 浅析MySQL与ElasticSearch的组合使用相关的知识,希望对你有一定的参考价值。
* GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
1. 导入
2. ElasticSearch入门
2.1. ElasticSearch介绍
2.2. ElasticSearch的安装
2.3. ElasticSearch概念入门
2.4. ElasticSearch简单操作
2.5. mysql与ElasticSearch的实际应用
3. 小结
1. 导入
假设有一业务场景:现有一电子商务系统需要具备让用户准确的找到自己想要商品的功能,因此怎么也绕不开的就是商品信息的检索了
可以来分析一下,对于一个电商系统而言,商品可能是由一个商品整体描述SPU对应不同的销售单元SKU来构成,同时商品还有对应的品牌信息、商品分类信息等,这些信息都有可能有对应的关联关系
此时,如果用户通过这个电商系统去查找商品,服务器就要根据用户的查找内容去构建对应检索数据的语句,这条语句往往是多表查询的,模糊查询的操作,十分耗费系统资源,更何况是在一些并发情况下,系统的性能就很低了,流程可见下图:

此外,数据库处理分词操作较为吃力,比如检索词为“白色”、“苹果手机”这些词汇,MySQL会将这些词汇与对应检索的数据库表的属性进行匹对得出结果集,但如果是“白色的64GB苹果手机”这样的组合词汇,需要得到的结果往往不能检索。因此,可以使用ElasticSearch全文检索引擎来解决这个问题,使得TB级数据在毫秒级就能返回检索结果,该引擎使用倒排索引,流程优化如下图:
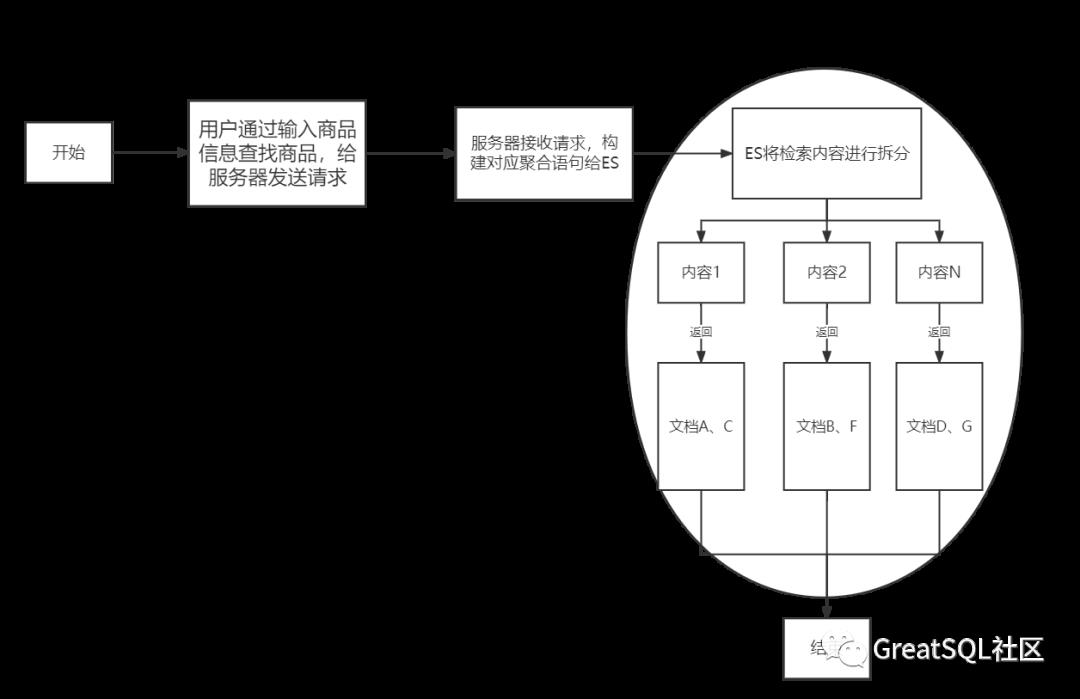
2. ElasticSearch入门
2.1. ElasticSearch介绍
Elasticsearch 是一个分布式的免费开源搜索和分析引擎,适用于包括文本、数字、地理空间、结构化和非结构化数据等在内的所有类型的数据。

Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、php、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。官方文档:(https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html)
2.2. ElasticSearch的安装
环境准备:CentOS 7
工具:Java 1.8、MySQL 8.0、ElasticSearch 7.4.2、kibana 7.4.2
下载ElasticSearch和kibana(可视化检索)
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2基础配置
# 将docker里的目录挂载到Linux的/mydata目录中
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
# 设置EalasticSearch可以被什么机器访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
# 递归更改权限,EalasticSearch需要访问
chmod -R 777 /mydata/elasticsearch/启动ElasticSearch,9200是用户交互端口
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \\
-e "discovery.type=single-node" \\
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \\
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \\
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \\
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \\
-d elasticsearch:7.4.2启动kibana
# kibana需要指定ElasticSearch交互端口,9200
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://服务器或虚拟机地址:9200 -p 5601:5601 -d kibana:7.4.2
# 设置开机启动kibana
docker update kibana --restart=always如图:

2.3. ElasticSearch概念入门
ElasticSearch有一个优势在于入门简单:
从同类型产品上看:市面上除了
ElasticSearch外,还有很多检索引擎,最为熟悉的例如Lucene,但是没法直接用Lucene,必须自己写代码去调用它的。ElasticSearch是Lucene的封装,提供了REST API的操作接口,开箱即用从学习使用角度上看:
ElasticSearch的许多概念与数据库一一对应,如Index(索引)在名词角度相对于MySQL的DataBase,动词角度相对于SQL的Insert语句。具体如下表:
| ElasticSearch | MySQL | 描述 |
|---|---|---|
| Index(索引) | DataBase | 做名词 |
| Index(索引) | Insert语句 | 做动词 |
| Type(类型) | Table | ES索引中可定义一个或多个Type |
| Document(文档) | Row 行 | 对应Index的某个Type的数据Document,JSON存放 |
| Field(字段) | Columns 列 | 一个Document是由一个或多个Field构成 |
2.4. ElasticSearch简单操作
接下来做一些简单的使用吧,例如现在我想看一下当前ES中全部的索引,通过 REST API 的方式可以,使用浏览器请求的方式:
http://ES部署位置IP地址:port/_cat/indices?v浏览器会返回如下内容:
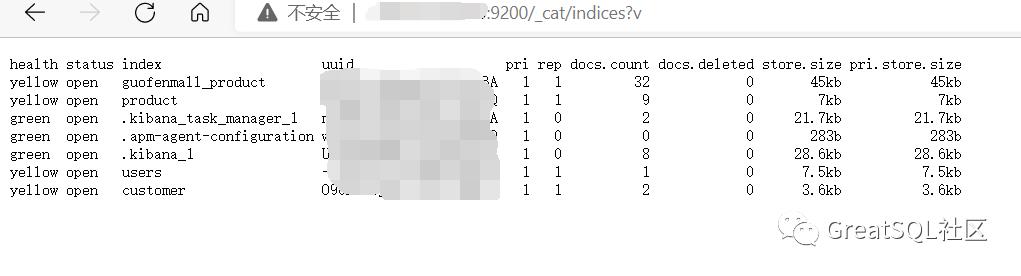 ES 中会默认存在一个名为.kibana和.kibana_task_manager的索引,返回信息中记录了索引的名字、状态等信息,具体如下:
ES 中会默认存在一个名为.kibana和.kibana_task_manager的索引,返回信息中记录了索引的名字、状态等信息,具体如下:
| 字段名 | 含义说明 |
|---|---|
| health | green(集群完整);yellow(单点正常、集群不完整);red(单点不正常) |
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主节点几个 |
| rep | 从节点几个 |
| docs.count | 索引中的文档数 |
| docs.deleted | 文档被删了多少 |
| store.size | 整体占空间大小 |
| pri.store.size | 主节点占空间大小 |
在确保kibana正常运行的时候,就可以使用更加便捷的可视化方式进行交互,通过部署的地址和端口接入kibana,即可进行操作,如下图:
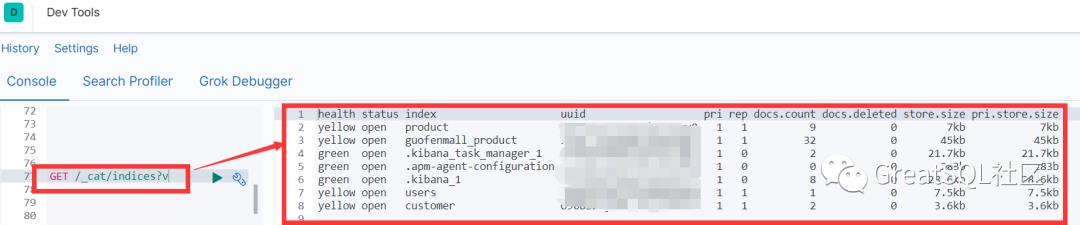 接着就可以对索引进行操作了:
接着就可以对索引进行操作了:
# 创建一个索引test01
PUT /test01
# 创建一个索引test02,指定分片及副本,默认分片为3,副本为2
PUT /test02
"settings":
"number_of_shards": 3,
"number_of_replicas": 2
# 查看索引test01的具体信息
GET /test01
# 删除索引test01
DELETE /test01有了索引,就可以为索引添加内容了,为索引添加内容之前要进行索引的映射,简单来说,映射就是定义文档的过程,文档包含哪些字段,这些字段是否保存,是否索引,是否分词等,格式如下:
PUT /索引库名/_mapping/类型名称
"properties":
"字段名":
"type": "类型",
"index": true,
"store": true,
"analyzer": "分词器"
# 类型名称:上文提到的Type
# 字段名:类似于列名,properties下可以指定许多字段具体字段对应属性如下表:
| 属性 | 描述 |
|---|---|
| type | 类型,例如:text、long、short、date、integer、object等 |
| index | 是否索引,默认为true |
| store | 是否存储,默认为false |
| analyzer | 分词器,这里使用ik分词器:ik_max_word或者ik_smart |
紧接着就可以增加索引里面的数据了:
POST /test01/ty01/_bulk
"index":
"_id":1
"testtitle":"test",
"test_attr":
"test_attr_1": "test",
"test_attr_2": "test"
最后可以进行查询:
GET /索引库名/_search
"query":
"查询类型":
"查询条件":"查询条件值"
# query代表一个查询对象,里面可以有不同的查询属性,可以是match_all,match,term,range等检索返回内容:
took:查询花费时间,单位是毫秒
time_out:是否超时
_shards:分片信息
hits:搜索结果总览对象
_index:索引库
_type:文档类型
_id:文档id
_score:文档得分
_source:文档的源数据
total:搜索到的总条数
max_score:所有结果中文档得分的最高分
hits:搜索结果的文档对象数组,每个元素是一条搜索到的文档信息
具体用法可以参照官方手册,这里不多做赘述了(https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html)
2.5. MySQL与ElasticSearch的实际应用
首先,要确定目前生产环境中DataBase中有什么表以及表内的什么数据需要放到ElasticSearch索引中,需要进行分析,分析后根据需求建立索引:
PUT product
"mappings":
"properties":
"skuId":
"type": "long"
,
"spuId":
"type": "keyword"
,
"skuTitle":
"type": "text",
"analyzer": "ik_smart"
,
"skuPrice":
"type": "keyword"
,
"skuImg":
"type": "keyword",
"index": false,
"doc_values": false
,
"brandName":
"type": "keyword",
"index": false,
"doc_values": false
接着进行环境的搭建,本文使用Java进行整合:
(1)在pom文件中引入依赖:
<dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependencies>(2)ES基础配置:
spring.elasticsearch.rest.uris=http://ip地址:9200
spring.data.elasticsearch.repositories.enabled=true
spring.data.elasticsearch.client.reactive.endpoints=ip地址:9200(3)ES配置类:
@Configuration
public class ElasticSearchConfig
public static final RequestOptions COMMON_OPTIONS;
/**
* 通用设置项
*/
static
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
COMMON_OPTIONS = builder.build();
@Bean
public RestHighLevelClient esRestClient()
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("ip", port, "http")));
return client;
(4)MySQL配置:
spring:
datasource:
username: username
password: password
url: jdbc:mysql://ip:3306/databasename?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver(5)构建对应的实体类(Vo):
@Data
public class EsVo
private Long skuId;
private Long spuId;
private String skuTitle;
private BigDecimal skuPrice;
private String skuImg;
private String brandName;
(6)建MySQL中的数据取出封装成EsVo,同时编写保存索引数据的业务实现:
@Service("EsSaveService")
public class EsServiceimpl implements EsSaveService
@Autowired
private RestHighLevelClient esRestClient;
@Override
public boolean productStatusUp(List<EsVo> esVos) throws IOException
// 在ES中保存这些数据
BulkRequest bulkRequest = new BulkRequest();
for (EsVo esVo : esVos)
//构造保存请求
IndexRequest indexRequest = new IndexRequest("test01");
indexRequest.id(skuEsModel.getSkuId().toString());
String jsonString = JSON.toJSONString(esVo);
indexRequest.source(jsonString, XContentType.JSON);
bulkRequest.add(indexRequest);
BulkResponse bulk = esRestClient.bulk(bulkRequest, ElasticSearchConfig.COMMON_OPTIONS);
boolean hasFailures = bulk.hasFailures();
List<String> collect = Arrays.asList(bulk.getItems()).stream().map(item ->
return item.getId();
).collect(Collectors.toList());
return hasFailures;
3. 小结
本文介绍了MySQL与ElasticSearch的应用方式,当然关于ES的应用还有很多,比如通过安装不同的分词器达到对一些网络上新出现的词汇进行准确拆分的效果。同时ES还包含强大的聚合语句,通过聚合语句可以让我们极其方便的实现对数据的统计、分析。聚合的类型也有很多,如:桶(bucket)、度量(metrics)等,详细都可以参照官方文档进行学习(https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html)
Enjoy GreatSQL :)
《深入浅出MGR》视频课程
戳此小程序即可直达B站
https://www.bilibili.com/medialist/play/1363850082?business=space_collection&business_id=343928&desc=0
文章推荐:
想看更多技术好文,点个“在看”吧!
以上是关于技术分析 | 浅析MySQL与ElasticSearch的组合使用的主要内容,如果未能解决你的问题,请参考以下文章