:PySpark库
Posted 黑马程序员官方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了:PySpark库相关的知识,希望对你有一定的参考价值。
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。下面就带大家来学习今天的内容!
往期内容:
- Spark基础入门-第一章:Spark 框架概述
- Spark基础入门-第二章:Spark环境搭建-Local
- Spark基础入门-第三章:Spark环境搭建-StandAlone
- Spark基础入门-第四章:Spark环境搭建-StandAlone-HA
- Spark基础入门-第五章:环境搭建-Spark on YARN
一、框架 VS 类库

二、什么是PySpark
我们前面使用过bin/pyspark 程序, 要注意, 这个只是一个应用程序, 提供一个Python解释器执行环境来运行Spark任务 我们现在说的PySpark, 指的是Python的运行类库, 是可以在Python代码中:import pyspark
PySpark 是Spark官方提供的一个Python类库, 内置了完全的Spark API, 可以通过PySpark类库来编写Spark应用程序, 并将其提交到Spark集群中运行.
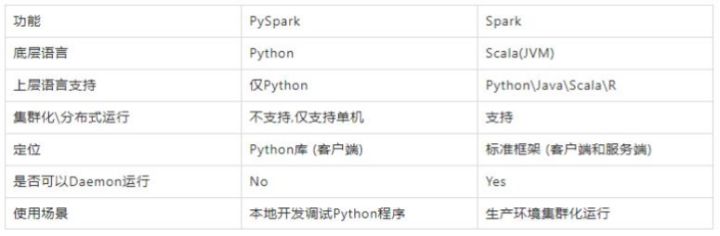
下图是PySpark类库和标准Spark框架的简单对比:
三、Anaconda的安装
Anaconda是Python语言的一个发行版.
内置了非常多的数据科学相关的Python类库, 同时可以提供虚拟环境来供不同的程序使用.
本次课程基于Anaconda3来获得Python运行环境.
Anaconda的安装参考<<spark部署文档.doc>>
四、PySpark安装
PySpark是Python标准类库, 可以通过Python自带的pip程序进行安装或者Anaconda的库安装(conda),
在合适的虚拟环境下(课程使用pyspark这个虚拟环境), 执行如下命令即可安装:
pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple或者conda install pyspark,推荐使用pip。
以上是关于:PySpark库的主要内容,如果未能解决你的问题,请参考以下文章