由Redis Cluster集群引发的对几种算法的思考
Posted 敲代码的小小酥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由Redis Cluster集群引发的对几种算法的思考相关的知识,希望对你有一定的参考价值。
前言
对比几个相似算法,理解Redis Cluster集群所使用算法的原因。首先介绍一下单调性:
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
一、HASH取余算法
简单公式:
hash(object)%N
应用场景:
比如你有 N 个 cache 服务器(后面简称 cache ),那么如何将一个对象 object 映射到 N 个 cache 上呢,你很可能会采用类似下面的通用方法计算 object 的 hash 值,然后均匀的映射到到 N 个 cache ;
一切都运行正常,再考虑如下的两种情况;
1 一个 cache 服务器 m down 掉了(在实际应用中必须要考虑这种情况),这样所有映射到 cache m 的对象都会失效,怎么办,需要把 cache m 从 cache 中移除,这时候 cache 是 N-1 台,映射公式变成了 hash(object)%(N-1) ;
2 由于访问加重,需要添加 cache ,这时候 cache 是 N+1 台,映射公式变成了 hash(object)%(N+1) ;
1 和 2 意味着什么?这意味着突然之间几乎所有的 cache 都失效了。对于服务器而言,这是一场灾难,洪水般的访问都会直接冲向后台服务器;
再来考虑第三个问题,由于硬件能力越来越强,你可能想让后面添加的节点多做点活,显然上面的 hash 算法也做不到。
hash取余不满足单调性原则。
有什么方法可以改变这个状况呢,这就是 一致性hash。
二、一致性hash算法
consistent hashing 是一种 hash 算法,简单的说,在移除 / 添加一个 cache 时,它能够尽可能小的改变已存在key 映射关系,尽可能的满足单调性的要求。
在一致性hash算法中,将0到2^32-1区间的数字按顺时针形成一个圆环,如下图所示(图没有截全,请自行脑补):
在redis集群中,将集群服务器的ip或者服务器名称进行hash函数,然后对2^32取模,得到的数字在上述圆环中定位,得到服务器在圆环中的位置。
当在redis集群中存入key时,对key进行hash函数,然后进行2^32取模,得到的数值就是该key在hash环上的位置。然后从该位置起,顺时针沿着圆环走,走到第一个服务器的位置,就是该key存放的位置。如下图所示:
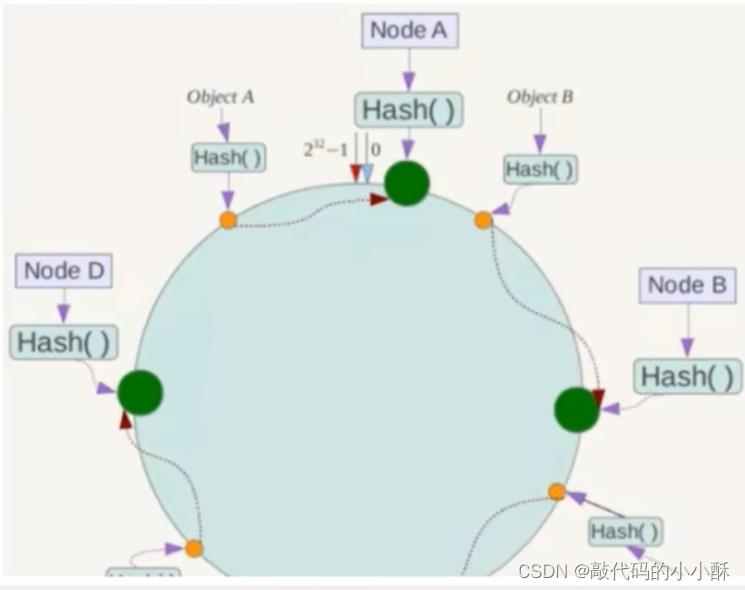
ObjectA通过hash()函数计算并进行2^32取模后,得到在hash环上的位置,然后顺时针找到第一个服务器位置,就是ObjectA存放的位置。ObjectB也是同样的道理。
这么设计有何好处呢?我们看下图:
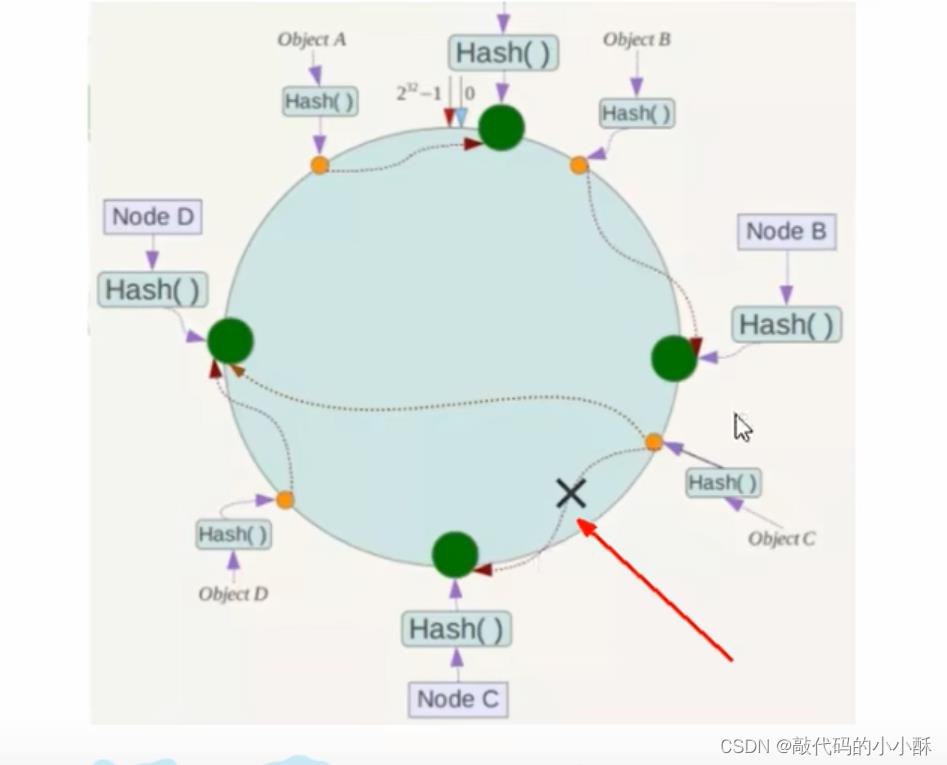
在上图中,假设C服务器宕机了,那么此时,C服务器中存放的key,会瞬移到D服务器中。同时,新加入的数据,通过计算得到在hash环上的位置后,顺时针查找服务器也会直接跳过C,存放到D中。如此一来,服务器宕机不会影响到全部服务器中数据存放。而是只影响了D服务器中数据的存放内容。这就避免了在hash取余中宕机一台服务器,分母就会变化而导致所有服务器中数据都要变化的情况出现。
同样的,当加入一台服务器时,也是在hash环中查找加入的位置,新的数据顺时针找到新加服务器后,会存入新加的服务器上,而不影响其他服务器的数据。可见,hash一致性算法满足了单调性原则。
那么hash一致性算法有何缺点呢?
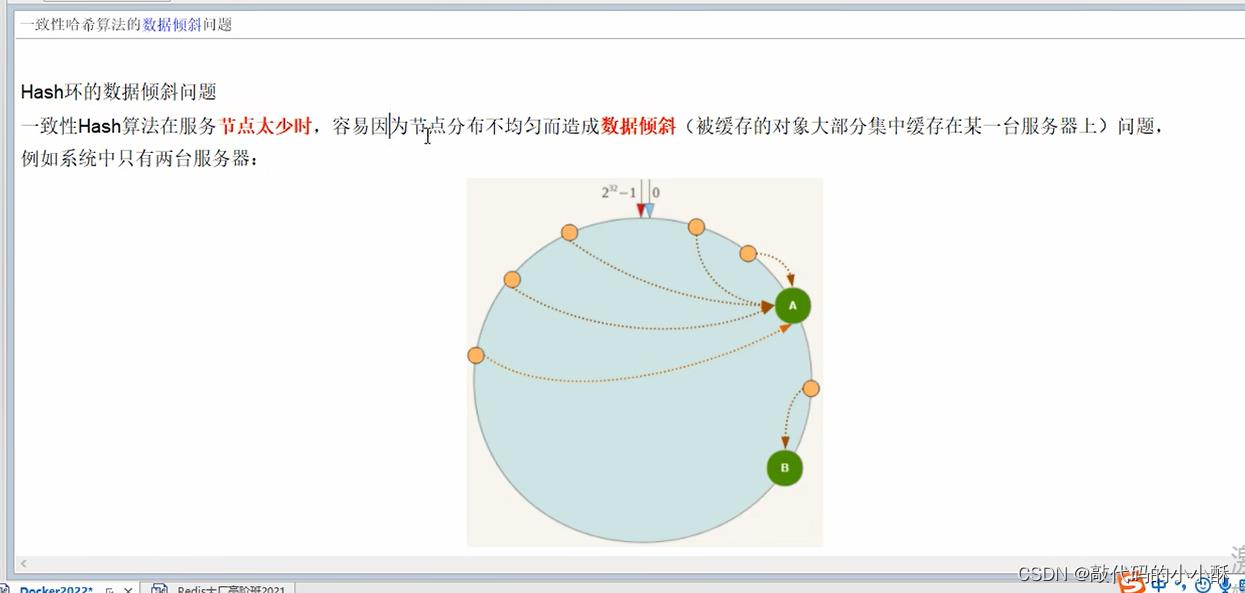
假如现在有三台服务器A、B和C,通过计算,A和B在hash环上位置比较近,B和C,C和A距离比较远。那么此时,顺时针落在C服务器和A服务器的数据概率就会变大。落在B服务器上的概率就小。这就出现了数据倾斜的问题。不能均匀分配数据。下图也是数据倾斜问题的一个体现:
三、hash槽位算法
针对一致性hash算法数据倾斜的问题,Reids Cluster进行了优化,衍生出了hash槽位算法。下面看是如何实现的。
redis集群中,有固定的槽位数:16384。redis会根据集群master数量,平均分配给每个master节点一定数量的槽位。redis会根据key进行hash计算,并对16384进行取模,得到的结果就是槽位数。这个槽位分配给了哪个服务器,那么这条数据就存放到哪个服务器上。
当发生redis集群扩容时,集群加入新节点后,需要执行reshard命令,进行重新hash分配。此时,redis会让用户输入分配新节点个数。一般就是16384个槽位/主节点数得到的值,对数据进行平分。选择平分后,是之前的节点的每个节点,分一些key出来,给到新节点,来凑够新节点的个数。因为redis的槽位总数是固定16384个,新加一个节点,rehash一次后,槽位数和节点的对应关系肯定会发生变化。就是原有节点拿出一部分槽位来,分给新加入节点。
因为新加入节点槽位是其他节点匀过来的,所以,其槽位数不是连续的,而是一段一段的。为何是其他节点匀过来,而不是全部重新分配一遍槽位呢,因为之前的节点已经存入数据了,如果全部重新分配,那么已经存入的key还需要重新整理,所以优先分配没有存入key值的槽位到新节点。
redis集群缩容就是将删除的槽位,平均分配给其他master节点来接收数据。
在redis cluster集群中,相当于是节点上放的是槽位,槽位里放的是数据。通过平均分配节点上的槽位,来避免一致性hash中数据倾斜的问题
以上是关于由Redis Cluster集群引发的对几种算法的思考的主要内容,如果未能解决你的问题,请参考以下文章