SPADE(GauGAN)算法笔记
Posted AI之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SPADE(GauGAN)算法笔记相关的知识,希望对你有一定的参考价值。
论文:Semantic Image Synthesis with Spatially-Adaptive Normalization
论文链接:https://arxiv.org/abs/1903.07291
代码链接:https://github.com/NVlabs/SPADE
项目主页链接:https://nvlabs.github.io/SPADE/
图像生成领域最近今年有不少出色的作品,比如英伟达在GTC 2019上展示的GauGAN,随后很多AI公众号都推送了相关文章,且大部分文章中将这个算法(GauGAN)称之为神笔马良,这是因为GauGAN可以根据用户画的简单图像(如Figure1最上面一行的4张图像所示)得到合成的实际图像(如Figure1右下角的12张图所示),在合成时用户还可以选择合成图像的风格(如Figure1最左边的3张图像所示),因此可以得到非常多样的合成结果。

虽然在GTC和大部分的介绍文章中都将这篇论文提出的算法称之为GauGAN,不过在这篇论文中作者将这个算法简称为SPADE,和论文名中的Spatially-Adaptive Normalization对应,接下来我们就都称之为SPADE了,大家知道本质上和GauGAN是一个算法就行了。
SPADE发表在CVPR 2019的Oral文章,CVPR 2019上还有一篇令人印象深刻的图像生成论文:StyleGAN,获得了最佳论文提名,在我看来这2篇文章都非常值得细细品读。这2篇论文的大部分作者都来自英伟达,不得不说英伟达在图像生成领域确实做除了非常多有意思和影响力的工作。
回到这篇论文,我们知道图像生成是一个非常广的领域,比如pix2pix、CycleGAN是图像翻译领域的代表作。SPADE研究的是:在给定一张语义分割图时合成对应的实际图像,英文名为semantic image synthesis。因为语义分割图一般都是由简单的线条组成,因此绘画起来比较容易,这也是为什么这个算法被称之为神笔马良的原因。
那么Spatially-Adaptive Normalization的出发点是什么呢?我们知道pix2pix(参考博客)和pix2pixHD(参考博客)是图像到图像翻译领域的经典算法,尤其pix2pixHD和这篇要介绍的SPADE算法都是基于语义分割图生成实景图。作者发现像pix2pixHD这样的算法中都是将语义分割图直接作为生成网络的输入进行计算,而这些生成网络中常用的传统归一化层(BN)容易丢失输入语义图像中的信息, 如Figure3所示,因此提出了新的归一化层:Spatially-Adaptive Normalization来解决这个问题。

Spatially-Adaptive Normalization是在BN的基础上做了修改,修改内容就在于γ和β计算的不同,如下图所示。在BN中γ和β的计算是通过网络训练得到的,而Spatially-Adaptive Normalization中γ和β是通过语义图像计算得到的。当然, 这种计算方式并非Spatially-Adaptive Normalization首次提出的,这就牵扯到另一个名词:conditional normalization,比如AdaIN(adaptive instance normalization),这重归一化层的γ和β都不是通过传统的网络训练得到的,而是通过额外的数据计算得到的,这类归一化层最早是应用在图像风格迁移算法中,用来编码图像风格信息,感兴趣的同学可以看看相关文章(A learned representation for artistic style(ICLR2017),Arbitrary style transfer in realtime with adaptive instance normalization(ICCV2017)),这里不展开了。Spatially-Adaptive Normalization和BN除了γ和β的计算方式不同外,γ和β维度的也不一样,请看下面的公式。
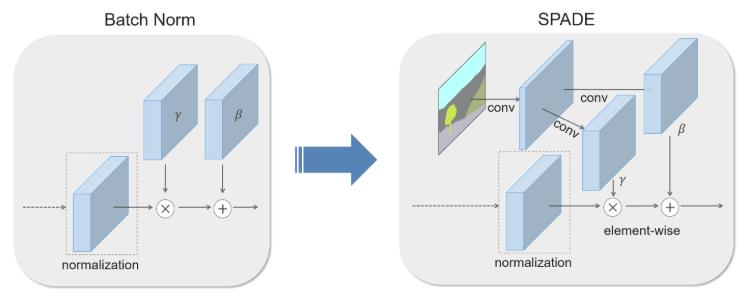
Spatially-Adaptive Normalization的计算过程如公式1所示,在BN中,γ和β是向量(也就是一维),其中每个值对应输入特征图的每个通道(channel),而在Spatially-Adaptive Normalization中,γ和β是三维矩阵,除了通道维度外,还有宽和高维度,因此公式1中γ和β下标包含c,y,x三个符号,这也是spatially-adaptive的含义,翻译过来就是在空间上是有差异的,或者叫自适应的。假如是BN,那么γ和β的下标只有c,也就是通道,显然,BN这种不区分空间维度的计算方式容易丢失输入图像的信息。
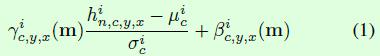
公式1中的均值μ和标准差σ的计算如公式2所示,这部分和BN中的计算一样。
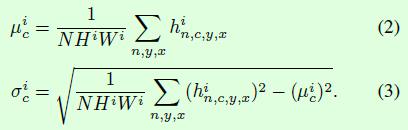
接下来看看网络结构方面的设计。
Figure4是SPADE算法中生成器的网络结构示意图,生成器采用堆叠多个SPADE ResBlk实现(Figure4右图),其中每个SPADE ResBlk的结构如Figure4左图所示,Spatially-Adaptive Normalization层中的γ和β参数通过输入的语义图像计算得到。
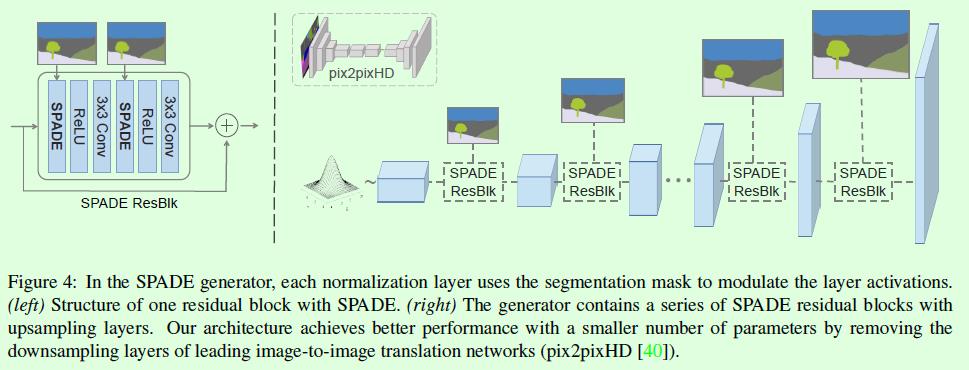
更详细的生成器结构图如下,从左到右分别表示局部层的细节展示。

判别器方面和pix2pixHD算法一样采用常见的Patch-GAN形式,如Figure13所示。

最后要介绍下关于SPADE算法是如何实现多样化输出的。Figure15是SPADE算法的整体示意图,生成器的输入是一个向量,这个向量可以是随机值,这样生成的图像也是随机的;同样,这个向量也可以通过一个编码网络(image encoder)和一张风格图像计算得到,编码网络将输入图像编码成向量,这个向量就包含输入图像的风格,这样就能得到Figure1中所展示的效果了。
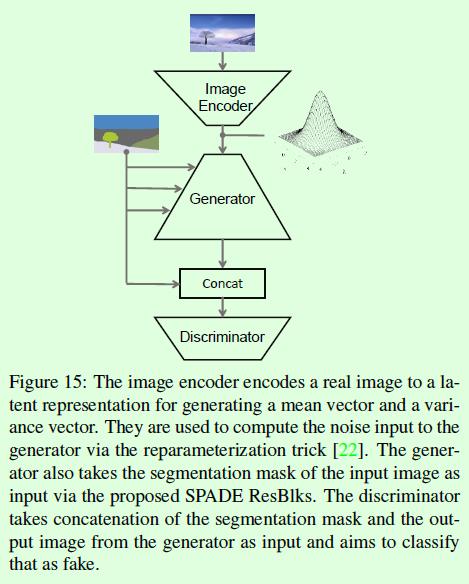
Figure14是编码网络(image encoder)的构成,可以看到主要是一些卷积层的堆叠,最后通过2个全连接层输出均值和方差值,这样就得到了一个数据分布,基于这个数据分布得到的向量就包含了输入图像的风格信息。

实验结果:
Figure6是SPADE算法和其他图像合成算法的对比。

Figure7是SPADE算法生成的风景图样例,非常真实。

以上是关于SPADE(GauGAN)算法笔记的主要内容,如果未能解决你的问题,请参考以下文章