Python第十二课 网络爬虫
Posted 笔触狂放
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python第十二课 网络爬虫相关的知识,希望对你有一定的参考价值。
本章主要讲的是基于Python语言的数据采集,该功能要讲起来可以单独作为一门课程来学习,因为这是一门很重要的课程,一般运用在大数据处理和人工智能上,该应用提供大量的数据。
12.1 urllib模块的学习
urllib模块是python提供给我们操作互联网的模块。接下来我们可以简单的操作一下,爬取一个网页的源代码,其实就是审查元素的操作。urllib中分为四部分:1.request 2.error 3.parse 4.robotparser
request是urllib中最重要的也是最复杂的。
# 网络爬虫
# 导入模块
import urllib.request as req
# 爬取该地址的网页源码
res=req.urlopen(r"https://www.baidu.com")
# 从爬取的内容中读取信息
html=res.read()
# 读取的信息是字节,需要通过编码格式的转换,才能获得和网页上审查元素的源代码一致
html=html.decode("UTF-8")
print(html)输出结果:

12.2 实战
12.2.1 爬取图片
这里我们来访问一下百度图片,其网站效果如图:
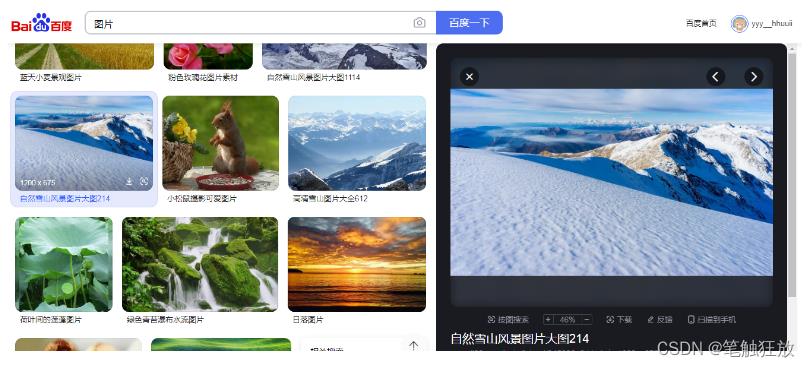
那我们一般想要某张图片,需要把鼠标移动到图片上点击右键,然后图片另存为……到我们电脑的指定的磁盘路径下。接下来看看我们python怎么通过代码来爬取想要的图片。我们先来看看这个图片对应的访问地址,右键复制图片访问地址,粘贴到地址上访问一下,是否能正常访问

即通过地址的访问,可以查看某一张图片,那么我们来通过python爬虫来爬取这张图片。
# 导入模块
import urllib.request as req
#指定猫的访问地址
res=req.urlopen("https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.jj20.com%2Fup%2Fallimg%2F1113%2F052420110515%2F200524110515-2-1200.jpg&refer=http%3A%2F%2Fimg.jj20.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1662537204&t=69f97612ad5cfcc28f60537007447873")
# 将猫图片读取,字节保存
cat_img=res.read()
# 指定一个本地路径,用于存储图片,并允许写入字节
f=open("cat_200_287.jpg","wb")
#将图片存储
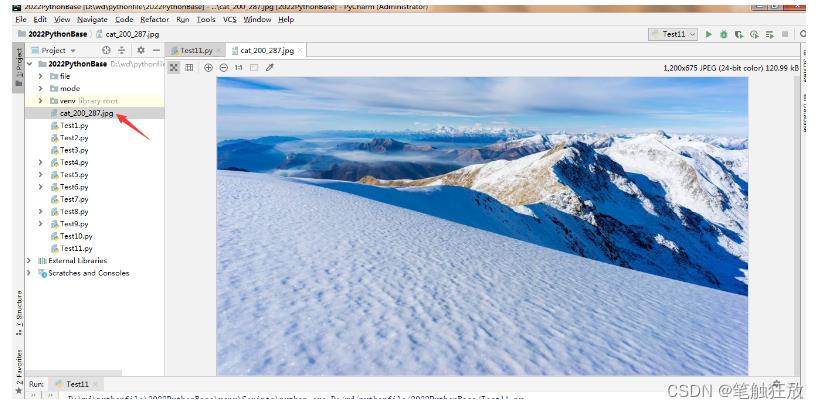
f.write(cat_img)执行完成后,可发现项目路径下已经将该图片爬取了。
12.2.2 在线文本翻译
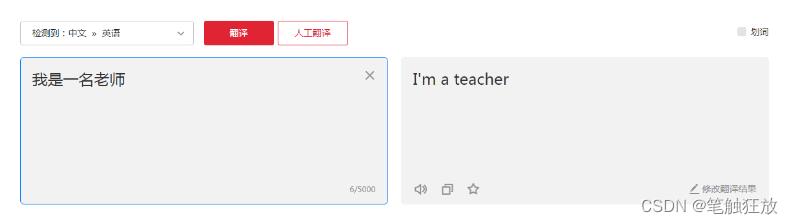
打开浏览器访问有道翻译的网站在线翻译_有道
接着我们右键审查元素,切换到network,查看其网络的请求和响应信息
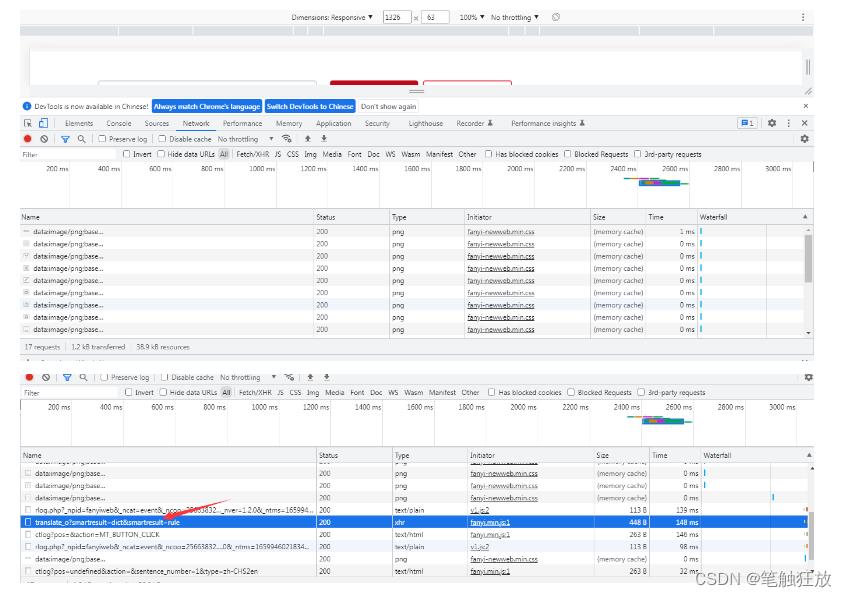
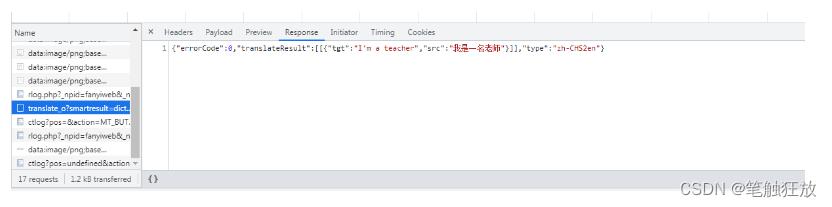
单击这个响应请求,查看其翻译信息
查看响应头信息

浏览器一般通过以下信息来判断是否是机器访问,而非人为正常操作。

如果使用python访问的该地址的话,User-Agent会被定义为Python-urllib/版本号
刚通过观察浏览器的返回结果:"errorCode":0,"translateResult":[["tgt":"I'm a teacher","src":"我是一名老师"]],"type":"zh-CHS2en"
那么这个格式是json格式,由和[]混合使用构建成,中间形成键值对并以冒号隔开key和value。
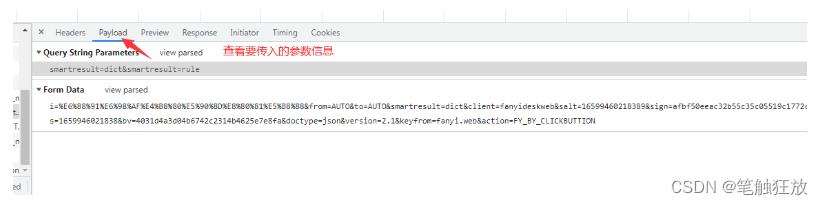
# -*- coding:utf-8 -*-
'''
使用 POST 方式抓取 有道翻译
urllib2.Request(requestURL, data=data, headers=headerData)
Request 方法中的 data 参数不为空,则默认是 POST 请求方式
如果 data 为空则是 Get 请求方式
"errorCode":50错误:
有道翻译做了一个反爬虫机制,就是在参数中添加了 salt 和 sign 验证,具体操作说明参考:
http://www.tendcode.com/article/youdao-spider/
'''
import urllib.request
import urllib.parse
import time
import random
import hashlib
import sys
# 字符串转 utf-8 需要重新设置系统的编码格式
def reload(sys):
sys.setdefaultencoding('utf8')
# 目标语言
targetLanguage = 'Auto'
# 源语言
sourceLanguage = 'Auto'
headerData =
'Cookie': 'OUTFOX_SEARCH_USER_ID=-2022895048@10.168.8.76;',
'Referer': 'fanyi.youdao.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
# 语言类型缩写
languageTypeSacronym =
'1': 'zh-CHS 》 en',
'2': 'zh-CHS 》 ru',
'3': 'en 》 zh-CHS',
'4': 'ru 》 zh-CHS',
# 翻译类型
translateTypes = [
'中文 》 英语',
'中文 》 俄语',
'英语 》 中文',
'俄语 》 中文'
]
def startRequest(tanslateWd):
requestURL = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
client = 'fanyideskweb'
timeStamp = getTime()
key = 'ebSeFb%=XZ%T[KZ)c(sy!'
sign = getSign(client, tanslateWd, timeStamp, key)
data = 'i': tanslateWd,
'from':sourceLanguage,
'to':targetLanguage,
'client':client,
'doctype':'json',
'version':'2.1',
'salt':timeStamp,
'sign':sign,
'keyfrom':'fanyi.web',
'action':'FY_BY_REALTIME',
'typoResult':'true',
'smartresult':'dict'
data = urllib.parse.urlencode(data).encode(encoding="utf-8")
request = urllib.request.Request(requestURL, data=data, headers=headerData)
resonse = urllib.request.urlopen(request)
print(resonse.read().decode("utf-8"))
# 生成时间戳
def getTime():
return str(int(time.time() * 1000) + random.randint(0, 10))
# 生成 Sign
def getSign(client, tanslateWd, time, key):
s = client + tanslateWd + time + key
m = hashlib.md5()
m.update(s.encode('utf-8'))
return m.hexdigest()
def getTranslateType(translateType):
global sourceLanguage, targetLanguage
try:
if translateType:
l = languageTypeSacronym[translateType].split(' 》 ')
sourceLanguage = l[0]
targetLanguage = l[1]
except:
print('翻译类型选择有误,程序将使用 Auto 模式为您翻译')
if __name__ == '__main__':
print('翻译类型:')
for i, data in enumerate(translateTypes):
print('%d: %s' %(i + 1, data))
translateType = input('请选择翻译类型:')
getTranslateType(translateType)
tanslateWd = input('请输入要翻译的消息:')
startRequest(tanslateWd)以上是关于Python第十二课 网络爬虫的主要内容,如果未能解决你的问题,请参考以下文章