猿创征文|机器学习实战——集成学习
Posted WHJ226
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了猿创征文|机器学习实战——集成学习相关的知识,希望对你有一定的参考价值。
目录
如果我们聚合一组预测器的预测,得到的预测结果会比最好的单个预测器要好,这样的一组预测器,我们称为集成,这种技术也被称为集成学习。例如,我们可以训练一组决策树分类器,每一棵树都基于训练集不同的随机子集进行训练。做出预测时,我们只需要获得所有树各自的预测,然后给出得票最多的类别作为预测结果,这样一组决策树的集成被称为随机森林。
常规模块的导入以及图像可视化的设置:
# Common imports
import numpy as np
import os
# to make this notebook's output stable across runs
np.random.seed(42)
# To plot pretty figures
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)1 投票分类器
假设我们已经训练好了一些分类器,这时,要创建一个更好的分类器,最简单的办法就是聚合每个分类器的预测,然后将得票最多的结果作为预测类别。这种大多数投票分类器被称为硬投票分类器。
下面我们创建并训练一个投票分类器,采用的是卫星数据集:
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=500, noise=0.30, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
log_clf = LogisticRegression(solver="liblinear", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42)
svm_clf = SVC(gamma="auto", random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='hard')
voting_clf.fit(X_train, y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))运行结果如下:
LogisticRegression 0.864
RandomForestClassifier 0.872
SVC 0.888
VotingClassifier 0.896从结果来看,投票分类器比其他分类器预测结果较好。
如果所有分类器都能估算出类别的概率(即predict_proba()方法),那么我们可以将概率在所有单个分类器上平均,然后让Scikit-Learn给出平均概率最高的类别作为预测,这称为软投票法。通常来说,软投票法表现最优,因为它给与那些高度自信的投票更高的权重。而所有我们需要做的就是用 voting="soft" 代替 voting="hard" ,并确保所有分类器都可以估算出概率。默认情况下,SVC类是不行的,我们需要将其超参数 probability 设置为 True (这也会导致SVC使用交叉验证来估算类别概率,减慢训练速度,并会添加predict_proba()方法)。下面我们尝试对代码修改进行软投票法预测:
log_clf = LogisticRegression(solver="liblinear", random_state=42)
rnd_clf = RandomForestClassifier(n_estimators=10, random_state=42)
svm_clf = SVC(gamma="auto", probability=True, random_state=42)
voting_clf = VotingClassifier(
estimators=[('lr', log_clf), ('rf', rnd_clf), ('svc', svm_clf)],
voting='soft')
voting_clf.fit(X_train, y_train)
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test, y_pred))运行结果如下:
LogisticRegression 0.864
RandomForestClassifier 0.872
SVC 0.888
VotingClassifier 0.9122 bagging and pasting
我们知道,获得不同种类分类器的方法之一是使用不同的训练算法,另外还有一种方法是每个预测器使用的算法相同,但是在不同的训练集随机子集上进行训练。采样时,我们如果将样本放回,该种方法叫做bagging(自举汇聚法);采样时样本不放回,这种方法叫做pasting。
一旦预测器训练完成,集成就可以通过简单地聚合所有预测器的预测,来对新实例做出预测。聚合函数通常是统计法用于分类,或是平均法用于回归。每个预测器单独的偏差都高于在原始训练集上训练的偏差,但是通过聚合,同时降低了偏差和方差。
Scikit-Learn中可以用 BaggingClassifier 类进行 bagging 和 pasting(或BaggingRegressor用于回归)。下面的代码训练了一个包含500个决策树分类器的集成,每次随机从训练集中采样100个训练实例进行训练(max_ssamples可以在0.0到1.0之间灵活设置,而每次采样的最大实例数量等于训练集的大小乘以max_ssamples),然后放回(bagging的一个示例,如果我们想要使用pasting,只需要设置bootstrap=False即可)。参数n_jobs用来表示Scikit-Learn用多少CPU内核进行训练和预测。
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1, random_state=42)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
y_pred_tree = tree_clf.predict(X_test)
from matplotlib.colors import ListedColormap
def plot_decision_boundary(clf, X, y, axes=[-1.5, 2.5, -1, 1.5], alpha=0.5, contour=True):
x1s = np.linspace(axes[0], axes[1], 100)
x2s = np.linspace(axes[2], axes[3], 100)
x1, x2 = np.meshgrid(x1s, x2s)
X_new = np.c_[x1.ravel(), x2.ravel()]
y_pred = clf.predict(X_new).reshape(x1.shape)
custom_cmap = ListedColormap(['#fafab0','#9898ff','#a0faa0'])
plt.contourf(x1, x2, y_pred, alpha=0.3, cmap=custom_cmap)
if contour:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1, x2, y_pred, cmap=custom_cmap2, alpha=0.8)
plt.plot(X[:, 0][y==0], X[:, 1][y==0], "yo", alpha=alpha)
plt.plot(X[:, 0][y==1], X[:, 1][y==1], "bs", alpha=alpha)
plt.axis(axes)
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel(r"$x_2$", fontsize=18, rotation=0)
plt.figure(figsize=(11,4))
plt.subplot(121)
plot_decision_boundary(tree_clf, X, y)
plt.title("Decision Tree", fontsize=14)
plt.subplot(122)
plot_decision_boundary(bag_clf, X, y)
plt.title("Decision Trees with Bagging", fontsize=14)
plt.show()运行结果如下:
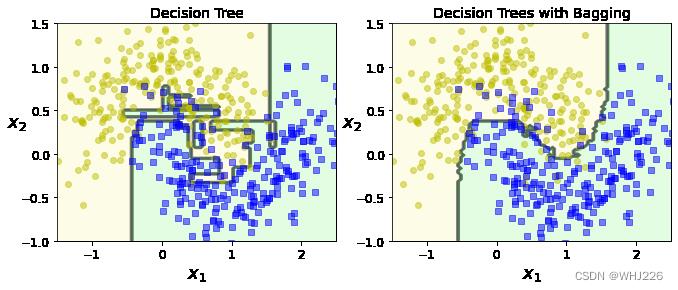
图中比较了两种决策边界,一个是单个的决策树,一个是由500个决策树组成的bagging集成,均在卫星数据集上训练完成。二者偏差相近,但是集成的方差更小。并且集成的决策边界更规则。
我们再来看一下准确率:
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred),accuracy_score(y_test, y_pred_tree)运行结果如下:
(0.904, 0.856)如果基础分类器能够估算类别概率(也就是具备predict_proba()方法),比如决策树分类器,那么BaggingClassifier 自动执行的就是软投票法而不是硬投票法。
由于自助法给每个预测器的训练子集引入更高的多样性,所以最后bagging比pasting的偏差略高,但这也意味着预测器之间的关联度更低,所以集成的方差降低。总之,bagging生成的模型通常更好。
3 包外评估
对于任意给定的预测器,使用bagging,有些实例可能会被采样多次,而有些实例则可能根本不被采样。BaggingClassifier 默认采样m个训练实例,然后放回样本(bootstrap=True),m是训练集的大小。这意味着对于每个预测器来说,平均只对63%的训练实例进行采样(随着m的增长,这个比率接近63%)。剩余37%未被采样的训练实例称为包外实例。既然预测器在训练的时候从未见过这些包外实例,正好可以用这些实例进行评估,从而不需要单独的验证集或是交叉验证。将每个预测器在其包外实例上的评估结果进行平均,我们就可以得到对集成的评估。
在Scikit-Learn中,创建 BaggingClassifier 时,设置oob_score = True ,我们就可以请求在训练结束后自动进行包外评估,且通过变量oob_score_ 可以得到最终的评估分数:
bag_clf = BaggingClassifier(
DecisionTreeClassifier(random_state=42), n_estimators=500,
bootstrap=True, n_jobs=-1, oob_score=True, random_state=40)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_运行结果如下:
0.8986666666666666
我们再看一下该 BaggingClassifier 分类器在测试集上的准确率:
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)运行结果如下:
0.912两个结果比较接近。
其实,每个训练实例的包外决策函数我们也可以通过 oob_decision_function_ 来获得。返回的是每个实例的类别概率。例如下面的代码:
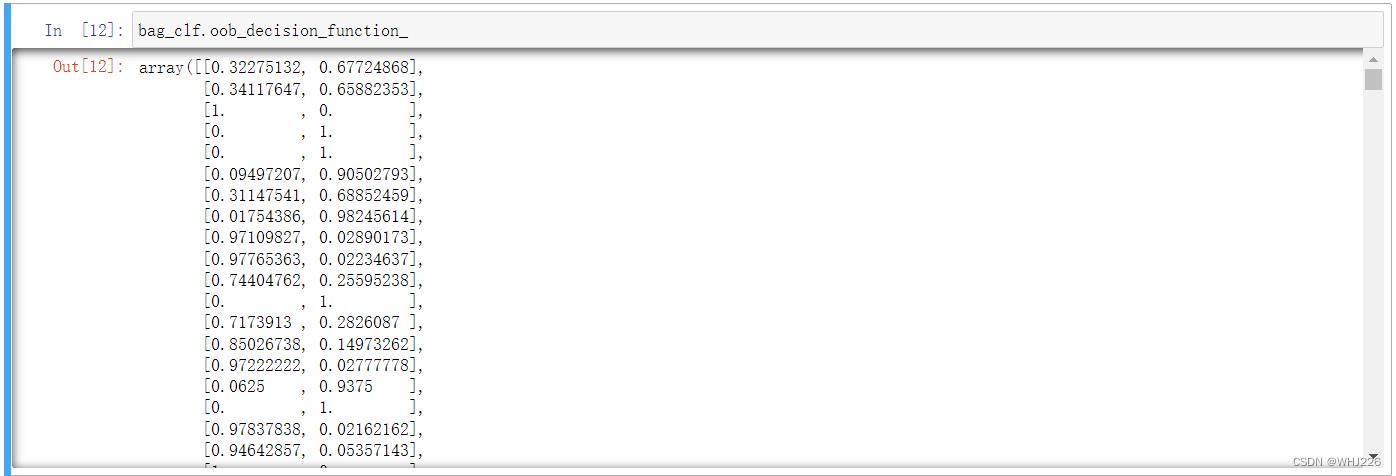
结果中,第一个训练实例(第一行) 有32.3%的概率属于正类,67.7%的概率属于负类。
4 疑问解答
- 如果我们已经在完全相同的训练集上训练了几个不同的模型,并且这几个模型都达到了90%多的准确率,那么我们是否还需要结合这些模型来获得更好的结果呢?
答:我们可以尝试把他们组成一个投票集成,这样效果可能更优。如果模型之间非常不同或者是在不同的训练实例上完成的训练,那么我们将会取得更好的效果。
- 硬投票和软投票分类器的区别。
答:硬投票分类器只是统计每个分类器的投票,然后挑选出得票最多的类别。软投票分类器将计算出每个类别的平均估算概率,然后挑选出概率最高的类别。软投票表现效果更优,但是它要求每个分类器都能够估算出类别概率才可以正常工作。
- 包外评估的好处。
答:包外评估可以对 bagging 集成中的每个预测器使用未经训练的实例进行评估。且不需要额外的验证集,就可以集成实时相当公正的评估。所以,如果训练使用的实例越多,集成的性能可以略有提升。
学习笔记——《机器学习实战:基于Scikit-Learn和TensorFlow》
以上是关于猿创征文|机器学习实战——集成学习的主要内容,如果未能解决你的问题,请参考以下文章
猿创征文|Python-sklearn机器学习快速入门:你的第一个机器学习实战项目
猿创征文|基于Java+SpringBoot+vue学生学习平台详细设计实现