编写高质量代码:改善Java程序的151个建议(第5章:数组和集合___建议75~78)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编写高质量代码:改善Java程序的151个建议(第5章:数组和集合___建议75~78)相关的知识,希望对你有一定的参考价值。
建议75:集合中的元素必须做到compareTo和equals同步
实现了Comparable接口的元素就可以排序,compareTo方法是Comparable接口要求必须实现的,它与equals方法有关系吗?有关系,在compareTo的返回为0时,它表示的是 进行比较的两个元素时相等的。equals是不是也应该对此作出相应的动作呢?我们看如下代码:
1 class City implements Comparable<City> { 2 private String code; 3 4 private String name; 5 6 public City(String _code, String _name) { 7 code = _code; 8 name = _name; 9 } 10 //code、name的setter和getter方法略 11 @Override 12 public int compareTo(City o) { 13 //按照城市名称排序 14 return new CompareToBuilder().append(name, o.name).toComparison(); 15 } 16 17 @Override 18 public boolean equals(Object obj) { 19 if (null == obj) { 20 return false; 21 } 22 if (this == obj) { 23 return true; 24 } 25 if (obj.getClass() == getClass()) { 26 return false; 27 } 28 City city = (City) obj; 29 // 根据code判断是否相等 30 return new EqualsBuilder().append(code, city.code).isEquals(); 31 } 32 33 }
我们把多个城市对象放在一个list中,然后使用不同的方法查找同一个城市,看看返回值有神么异常?代码如下:
1 public static void main(String[] args) { 2 List<City> cities = new ArrayList<City>(); 3 cities.add(new City("021", "上海")); 4 cities.add(new City("021", "沪")); 5 // 排序 6 Collections.sort(cities); 7 // 查找对象 8 City city = new City("021", "沪"); 9 // indexOf方法取得索引值 10 int index1 = cities.indexOf(city); 11 // binarySearch查找索引值 12 int index2 = Collections.binarySearch(cities, city); 13 System.out.println(" 索引值(indexOf) :" + index1); 14 System.out.println(" 索引值(binarySearch) :" + index2); 15 }
输出的index1和index2应该一致吧,都是从一个列表中查找相同的元素,只是使用的算法不同嘛。但是很遗憾,结果不一致:
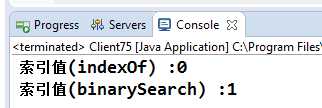
indexOf返回的是第一个元素,而binarySearch返回的是第二个元素(索引值为1),这是怎么回事呢?
这是因为indexOf是通过equals方法判断的,equals方法等于true就认为找到符合条件的元素了,而binarySearch查找的依据是compareTo方法的返回值,返回0即认为找到符合条件的元素了。
仔细审查一下代码,我们覆写了compareTo和equals方法,但是两者并不一致。使用indexOf方法查找时 ,遍历每个元素,然后比较equals方法的返回值,因为equals方法是根据code判断的,因此当第一次循环时 ,equals就返回true,indexOf方法结束,查找到指定值。而使用binarySearch二分法查找时,依据的是每个元素的compareTo方法返回值,而compareTo方法又是依赖属性的,name相等就返回0,binarySearch就认为找到元素了。
问题明白了,修改很easy,将equals方法修改成判断name是否相等即可,虽然可以解决问题,但这是一个很无奈的办法,而且还要依赖我们的系统是否支持此类修改,因为逻辑已经发生了很大的变化,从这个例子,我们可以理解两点:
- indexOf依赖equals方法查找,binarySearch则依赖compareTo方法查找;
- equals是判断元素是否相等,compareTo是判断元素在排序中的位置是否相同。
既然一个决定排序位置,一个是决定相等,那我们就应该保证当排序相同时,其equals也相同,否则就会产生逻辑混乱。
注意:实现了compareTo方法就应该覆写equals方法,确保两者同步。
建议76:集合运算时使用最优雅方式
在初中代数中,我们经常会求两个集合的并集、交集、差集等,在Java中也存在着此类运算,那如何实现呢?一提到此类集合操作,大部分的实现者都会说:对两个集合进行遍历,即可求出结果。是的。遍历可以实现并集、交集、差集等运算,但这不是最优雅的处理方式,下面来看看如何进行更优雅、快速、方便的集合操作:
(1)、并集:也叫作合集,把两个集合加起来即可,这非常简单,代码如下:
1 public static void main(String[] args) { 2 List<String> list1 = new ArrayList<String>(); 3 list1.add("A"); 4 list1.add("B"); 5 List<String> list2 = new ArrayList<String>(); 6 list2.add("C"); 7 // 并集 8 list1.addAll(list2); 9 }
(2)、交集:计算两个集合的共有元素,也就是你有我也有的元素集合,代码如下:
//交集 list1.retainAll(list2);
其中的变量list1和list2是两个列表,仅此一行,list1中就只包含了list1、list2中共有的元素了,注意retailAll方法会删除list1中没有出现在list2中的元素。
(3)、差集:由所有属于A但不属于B的元素组成的集合,叫做A与B的差集,也就是我有你没有的元素,代码如下:
//差集 list1.retainAll(list2);
也很简单,从list1中删除出现在list2中的元素,即可得出list1和list2的差集部分。
(4)、无重复的并集:并集是集合A加集合B,那如果集合A和集合B有交集,就需要确保并集的结果中只有一份交集,此为无重复的并集,此操作也比较简单,代码如下:
//删除在list1中出现的元素 list2.removeAll(list1); //把剩余的list2元素加到list1中 list1.addAll(list2);
可能有人会说,求出两个集合的并集,然后转成hashSet剔除重复元素不就解决了吗?错了,这样解决是不行的,比如集合A有10个元素(其中有两个元素值是相同的),集合B有8个元素,它们的交集有两个元素,我们可以计算出它们的并集是18个元素,而无重复的并集有16个元素,但是如果用hashSet算法,算出来则只有15个元素,因为你把集合A中原本就重复的元素也剔除了。
之所以介绍并集、交集、差集,那是因为在实际开发中,很少有使用JDK提供的方法实现集合这些操作,基本上都是采用了标准的嵌套for循环:要并集就是加法,要交集就是contains判断是否存在,要差集就使用了!contains(不包含),有时候还要为这类操作提供了一个单独的方法看似很规范,其实应经脱离了优雅的味道。
集合的这些操作在持久层中使用的非常频繁,从数据库中取出的就是多个数据集合,之后我们就可以使用集合的各种方法构建我们需要的数据,需要两个集合的and结果,那是交集,需要两个集合的or结果,那是并集,需要两个集合的not结果,那是差集。
建议77:使用shuffle打乱列表
在网站上,我们经常会看到关键字云(word cloud)和标签云(tag cloud),用于表达这个关键字或标签是经常被查阅的,而且还可以看到这些标签的动态运动,每次刷新都会有不一样的关键字或标签,让浏览者觉得这个网站的访问量很大,短短的几分钟就有这么多的搜索量。不过,在Java中该如何实现呢?代码如下:
1 public static void main(String[] args) { 2 int tagCloudNum = 10; 3 List<String> tagClouds = new ArrayList<String>(tagCloudNum); 4 // 初始化标签云,一般是从数据库读入,省略 5 Random rand = new Random(); 6 for (int i = 0; i < tagCloudNum; i++) { 7 // 取得随机位置 8 int randomPosition = rand.nextInt(tagCloudNum); 9 // 当前元素与随机元素交换 10 String temp = tagClouds.get(i); 11 tagClouds.set(i, tagClouds.get(randomPosition)); 12 tagClouds.set(randomPosition, temp); 13 } 14 }
现从数据库中读取标签,然后使用随机数打乱,每次产生不同的顺序,嗯,确实能让浏览者感觉到我们的标签云顺序在变化---浏览者多嘛!但是,对于乱序处理我们可以有更好的实现方式,先来修改第一版:
1 public static void main(String[] args) { 2 int tagCloudNum = 10; 3 List<String> tagClouds = new ArrayList<String>(tagCloudNum); 4 // 初始化标签云,一般是从数据库读入,省略 5 Random rand = new Random(); 6 for (int i = 0; i < tagCloudNum; i++) { 7 // 取得随机位置 8 int randomPosition = rand.nextInt(tagCloudNum); 9 // 当前元素与随机元素交换 10 Collections.swap(tagClouds, i, randomPosition); 11 } 12 }
上面使用了Collections的swap方法,该方法会交换两个位置的元素值,不用我们自己写交换代码了。难道乱序到此就优化完了吗?没有,我们可以继续重构,第二版如下:
1 public static void main(String[] args) { 2 int tagCloudNum = 10; 3 List<String> tagClouds = new ArrayList<String>(tagCloudNum); 4 // 初始化标签云,一般是从数据库读入,省略 5 //打乱顺序 6 Collections.shuffle(tagClouds); 7 }
这才是我们想要的结果,就这一行,即可打乱一个列表的顺序,我们不用费尽心思的遍历、替换元素了。我们一般很少用到shuffle这个方法,那它在什么地方用呢?
- 可用在程序的 "伪装" 上:比如我们例子中的标签云,或者是游侠中的打怪、修行、群殴时宝物的分配策略。
- 可用在抽奖程序中:比如年会的抽奖程序,先使用shuffle把员工顺序打乱,每个员工的中奖几率相等,然后就可以抽出第一名、第二名。
- 可以用在安全传输方面:比如发送端发送一组数据,先随机打乱顺序,然后加密发送,接收端解密,然后进行排序,即可实现即使是相同的数据源,也会产生不同密文的效果,加强了数据的安全性。
建议78:减少HashMap中元素的数量
本建议是说HahMap中存放数据过多的话会出现内存溢出,代码如下:
1 public static void main(String[] args) { 2 Map<String, String> map = new HashMap<String, String>(); 3 List<String> list = new ArrayList<String>(); 4 final Runtime rt = Runtime.getRuntime(); 5 // JVM中止前记录信息 6 rt.addShutdownHook(new Thread() { 7 @Override 8 public void run() { 9 StringBuffer sb = new StringBuffer(); 10 long heapMaxSize = rt.maxMemory() >> 20; 11 sb.append(" 最大可用内存:" + heapMaxSize + " M\n"); 12 long total = rt.totalMemory() >> 20; 13 sb.append(" 堆内存大小:" + total + "M\n"); 14 long free = rt.freeMemory() >> 20; 15 sb.append(" 空闲内存:" + free + "M"); 16 System.out.println(sb); 17 } 18 }); 19 for (int i = 0; i < 40*10000; i++) { 20 map.put("key" + i, "value" + i); 21 // list.add("list"+i); 22 } 23 }
这个例子,我经过多次运算,发现在40万的数据并不会内存溢出,如果要复现此问题,需要修改Eclipse的内存配置,才会复现。但现在的机器的内存逐渐的增大,硬件配置的提高,应该可以容纳更多的数据。本人机器是windows64,内存8G配置,Eclipse的配置为 -Xms286M -Xmx1024M,在单独运行此程序时,数据量加到千万级别才会复现出此问题。但在生产环境中,如果放的是复杂对象,可能同样配置的机器存放的数据量会小一些。
但如果换成list存放,则同样的配置存放的数据比HashMap要多一些,本人就针对此现象进行分析一下几点:
1.HashMap和ArrayList的长度都是动态增加的,不过两者的扩容机制不同,先说HashMap,它在底层是以数组的方式保存元素的,其中每一个键值对就是一个元素,也就是说HashMap把键值对封装成了一个Entry对象,然后再把Entry对象放到了数组中。也就是说HashMap比ArrayList多了一次封装,多出了一倍的对象。其中HashMap的扩容机制代码如下(resize(2 * table.length)这就是扩容核心代码):
1 void addEntry(int hash, K key, V value, int bucketIndex) { 2 if ((size >= threshold) && (null != table[bucketIndex])) { 3 resize(2 * table.length); 4 hash = (null != key) ? hash(key) : 0; 5 bucketIndex = indexFor(hash, table.length); 6 } 7 8 createEntry(hash, key, value, bucketIndex); 9 }
在插入键值对时会做长度校验,如果大于或者等于阈值,则数组长度会增大一倍。
1 void resize(int newCapacity) { 2 Entry[] oldTable = table; 3 int oldCapacity = oldTable.length; 4 if (oldCapacity == MAXIMUM_CAPACITY) { 5 threshold = Integer.MAX_VALUE; 6 return; 7 } 8 9 Entry[] newTable = new Entry[newCapacity]; 10 boolean oldAltHashing = useAltHashing; 11 useAltHashing |= sun.misc.VM.isBooted() && 12 (newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD); 13 boolean rehash = oldAltHashing ^ useAltHashing; 14 transfer(newTable, rehash); 15 table = newTable; 16 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); 17 }
而阈值就是代码中红色标注的部分,新容量*加权因子和MAXIMUM_CAPACITY + 1两个值的最小值。MAXIMUM_CAPACITY的值如下:
static final int MAXIMUM_CAPACITY = 1 << 30;
而加权因子的值为0.75,代码如下:
static final float DEFAULT_LOAD_FACTOR = 0.75f;
所以hashMap的size大于数组的0.75倍时,就开始扩容,经过计算得知(怎么计算的,以文中例子来说,查找2的N次幂大于40万的最小值即为数组的最大长度,再乘以0.75,也就是最后一次扩容点,计算的结果是N=19),在Map的size为393216时,符合了扩容条件,于是393216个元素开始搬家,要扩容则需要申请一个长度为1048576(当前长度的两倍,2的20次方)的数组,如果此时内存不足以支撑此运算,就会爆出内存溢出。这个就是这个问题的根本原因。
2、我们思考一下ArrayList的扩容策略,它是在小于数组长度的时候才会扩容1.5倍,经过计算得知,ArrayLsit在超过80万后(一次加两个元素,40万的两倍),最近的一次扩容是在size为1005305时同样的道理,如果此时内存不足以申请扩容1.5倍时的数组,也会出现内存溢出。
综合来说,HashMap比ArrayList多了一层Entry的底层封装对象,多占用了内存,并且它的扩容策略是2倍长度的递增,同时还会根据阈值判断规则进行判断,因此相对于ArrayList来说,同样的数据,它就会优先内存溢出。
也许大家会想到,可以在声明时指定HashMap的默认长度和加载因子来减少此问题的发生,可以缓解此问题,可以不再频繁的进行数组扩容,但仍避免不了内存溢出问题,因为键值对的封装对象Entry还是少不了的,内存依然增长比较快,所以尽量让HashMap中的元素少量并简单一点。也可以根据需求以及系统的配置来计算出,自己放入map中的数据会不会造成内存溢出呢?
以上是关于编写高质量代码:改善Java程序的151个建议(第5章:数组和集合___建议75~78)的主要内容,如果未能解决你的问题,请参考以下文章
编写高质量代码:改善Java程序的151个建议(第3章:类对象及方法___建议41~46)
转载---编写高质量代码:改善Java程序的151个建议(第2章:基本类型___建议21~25)
编写高质量代码:改善Java程序的151个建议(第5章:数组和集合___建议65~69)
编写高质量代码:改善Java程序的151个建议(第4章:字符串___建议52~55)