神经网络回归与线性模型
Posted ViperL1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络回归与线性模型相关的知识,希望对你有一定的参考价值。
一、线性回归
需要通过训练集和
求解x,y之间的映射关系
1.线性回归
①模型
增广权重向量&增广特征向量:在x和上添加一个b,可将模型中原有的b消除。
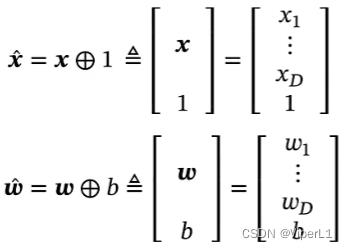
模型转换为:
②训练集D上的经验风险
X矩阵:其中每行为一个样本
Y向量:列向量,每一列为一个结果
③经验风险最小化
以此公式求解w
推导:
条件:
必须存在
若不存在(特征之间存在共线性),可以采用以下两种方法求解
①SGD(随机数下降) ②降维
结构风险: ,其中
被称为正则化项,
为正则化参数。
使其最小化:
!!!Attention矩阵微积分

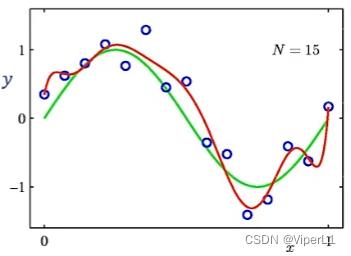
2.多项式回归
①模型
多项式曲线拟合
②损失函数
③经验风险最小化
求解过程与线性回归类似
④选择合适的多项式次数

控制过拟合:正则化
惩罚大的系数:
其中为正则化项,
为正则化系数
控制过拟合:增加训练样本数量
3.从概率视角来看线性回归
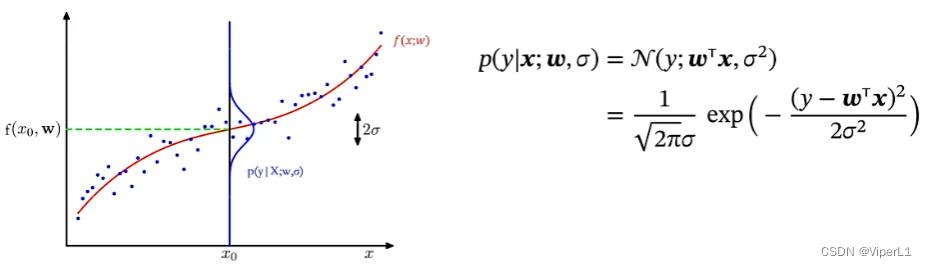
①似然函数
参数w固定时,描述随机变量x的分布情况,称p(x;w)为概率
已知随机变量x时,不同参数w对其分布的影响,称p(x;w)为似然
线性回归中的似然函数:
②最大似然估计
求一组参数w,使取最大值(求导)
③贝叶斯学习
将参数w也视为随机变量;给定一组数据X,求参数w的分布p(w|X),也称后验分布
贝叶斯公式:
先验: 后验 正比于 似然 X 先验

最大后验估计:
正则化系数
⑤四种准则
| 平方误差 | 经验风险最小化 | |
| 结构风险最小化 | ||
| 概率 | 最大似然估计 | (XX^T)^-1Xy |
| 最大后验估计 |
4.模型选择
模型越复杂,训练错误越低;
但不能以训练错误高低来选择模型;
选择模型时,测试集不可见。
①引入验证集
可将训练集分为两部分训练集和验证集,在验证集上挑选一个错误最小的模型。
解决数据稀疏问题(样本过少):交叉验证,将训练集分为S组,每次使用S-1组作为训练集,剩下一组作验证集;取验证集平均性能最好的一组。

②使用准则
赤池信息量准则、贝叶斯信息准则
③偏差-方差分解
平衡模型复杂度和期望风险
期望风险:
最优模型:
期望风险可以分解为:
通常由样本分布及噪声引起,无法通过优化模型消除。
目的:模型与最优模型
尽可能贴近


由偏差与方差进行模型选择

随着模型复杂度↑,方差↑,偏差↓
5.常用定理
①没有免费午餐定理
不存在某种算法对所有问题都有效
②丑小鸭定理
丑小鸭与白天鹅之间的区别和两只白天鹅之间的区别一样大(未给定具体条件的情况下)
③奥卡姆剃刀定理
若无必要,勿增实体
④归纳偏置
做出的假设称为归纳偏置,在贝叶斯学习中称为先验
⑤PAC学习
由大数定律,训练集趋于无穷大时,泛化误差趋近于0
以上是关于神经网络回归与线性模型的主要内容,如果未能解决你的问题,请参考以下文章