大数据技术生态,不懂你捶我
Posted 大数据指北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术生态,不懂你捶我相关的知识,希望对你有一定的参考价值。
大家好,我是脚丫先生 (o^^o)
大数据时代这个词被提出已经10年有余,特别是最近几年风风火火的贵州贵阳。
乘着时代的风口和国家的有力支撑,已被称之为“中国数谷”。
大数据的力量如此巨大,难免让人好奇不已。那么到底什么是大数据呢?
大数据的概念、大数据技术、大数据平台,一条龙服务,尽在下文!!!

目录
一、大数据
大数据(Big Data)本身是个很宽泛的概念,根据字面理解,可知是很大很大的数据。
数据大到了极限,造成传统技术已经无法处理。
专业术语:大数据指的是传统数据处理应用软件,不足以处理(存储和计算)它们,大而复杂的数据集。
可以理解 为一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库,软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低。
总而言之,大数据就是指数据很大,传统技术无法高效的处理该数据。
四大特征:大量,多样,高速,低价值密度。
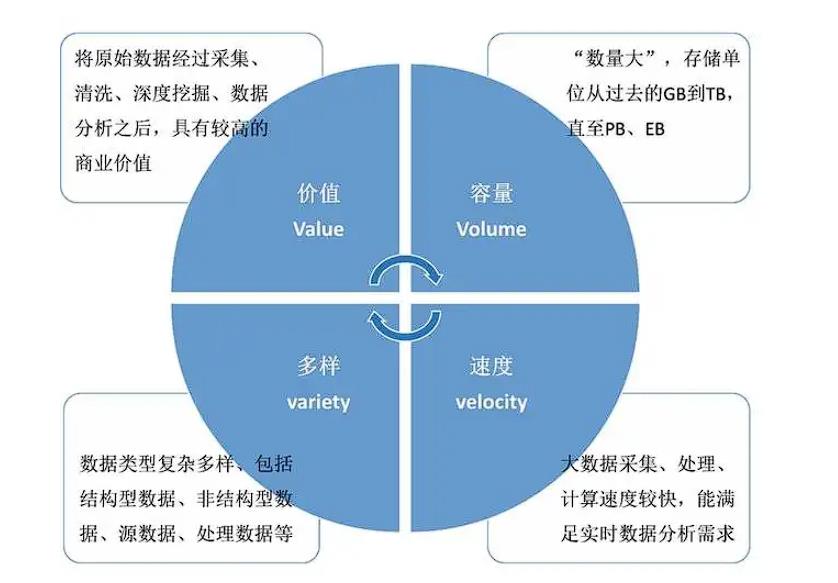
(1) 大量:数据容量大。从TB级别,跃升到PB级别。海量的数据,可谓是数据的海洋。

(2) 多样:数据类型的多样性,包括文本,图片,视频,音频。相对于以往便于存储的以文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等。

传统技术的处理多类型的数据已经不堪重任,因此对于数据的处理能力提出了更高要求。
(3) 高速:指获得数据的速度以及处理数据的速度,数据的产生呈指数式爆炸式增长,处理数据要求的延时越来越低。
(4) 价值密度低:价值密度的高低与数据总量的大小成反比。以视频为例,一部1小时的视频,在连续不间断的监控中,会产生大量的数据,但是有用数据可能仅有一二秒。

价值密度低,就好比一整部电影,无数个镜头,然而仅有一两个镜头较为经典。
二、大数据核心技术
我们知道了大数据的特点之后,就要改变传统的数据处理模式。
解决,海量数据的存储和计算问题。
因此引进了新处理模式,大数据技术。
大数据的概念比较抽象,而大数据技术栈的庞大程度将让你叹为观止。
来吧,我们一起漂进大数据技术的海洋,从此一去不复返!!!

这些就是大数据生态圈的技术组件,可谓是眼花缭乱,应接不暇(好吧,其实是杂乱无章)。
那么,大数据生态圈的技术组件(技术栈),又是如何解决海量数据的存储和计算问题呢 ?
先放大数据技术生态圈的一个大致组件分布图,之后我们一步步的进行分解组合。
图片我们可以看到,已经把之前杂乱的大数据组件摆放的规规矩矩,有条有序的。
看着由杂乱无章到井井有条的大数据生态圈有点舒服。
似乎有点像家里修建房屋一样,一层一层,往上拔高,逐渐精彩。
那么我们接下来就一起把大数据生态圈这栋房子开始修建。
2.1 HDFS分布式文件系统
既然要把大数据生态圈这栋房子修建,那么我们首先要进行的就是打建地基。
地基不稳,地动山摇。
HDFS分布式文件系统就好比我的地基。我们知道传统的文件系统是单机的,不能横跨不同的机器。
HDFS分布式文件系统的设计本质上是为了大量的数据能横跨成百上千台机器。
简而言之,把多台机器存储的数据,用一个软件进行统一管理,执行增删改查操作。
万事开头难,我们终于有了HDFS分布式文件系统作为房屋的地基,此刻我们的大数据生态圈房屋是这样的。
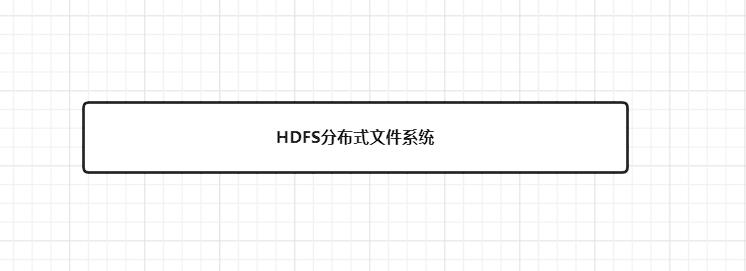
既然此刻,已经有了房屋的地基HDFS,也就是可以进行数据的存储。
吐一口气,算是解决了海量大数据的存储问题。
那么既然有了数据,我就应该去解决海量大数据的计算问题。因此,开始了我们房屋的第一层修建。
2.2 MapReduce计算引擎
当把海量数据存储于HDFS分布式文件系统之后,就开始考虑怎么处理数据。
虽然HDFS可以为你整体管理不同机器上的数据,但是这些数据太大了。在一台服务器读取TP级别的海量数据(比如整个东京热有史以来所有高清电影的大小甚至更大)。
是需要消耗非常多的时间,比如微博要更新24小时热博,它必须在24小时之内处理完海量的数据,显然单机服务器的计算能力是无法完成的。
但是如果我们用很多台服务器,利用这些机器的资源进行分布式处理数据,那么就可以大大的提高执行效率,这就是MapReduce的功能,一种分布式并行处理框架。
到此,我们第一层,计算引擎MapReduce算是正式修建完毕。此时,我们的大数据生态圈房屋是这样的。
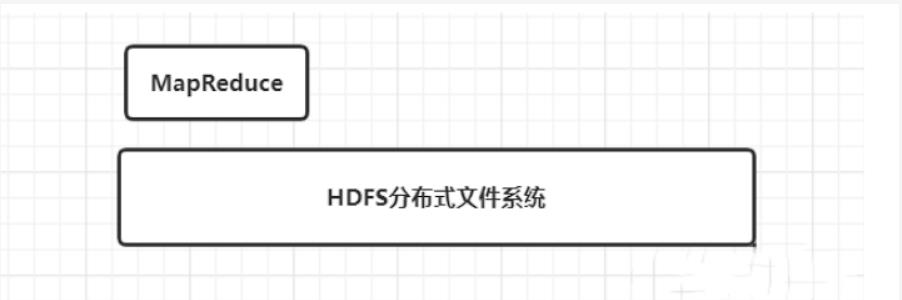
2.3 Hive数据仓库
有了MapReduce分布式处理框架之后我们发现MapReduce的程序写起来很麻烦,对于不懂程序开发的人非常不友好。
希望简化这个过程,能有个更高层更抽象的语言层来描述算法和数据处理流程。
就好比,虽然MapReduce这层房可以住,但是它并不好住,不是喜欢的风格。我们希望能在它基础上进行修改成我们喜欢的style。
于是就有了Hive,开发人员只需要编写简单易上手的SQL语句,它就把SQL语言翻译成MapReduce程序,让计算引擎去执行,从而让你从繁琐的MapReduce程序中解脱出来,用更简单更直观的语言去写程序了。
我们的第二层,Hive数据仓库层算是正式修建完毕。此时,我们的大数据生态圈房屋是这样的。
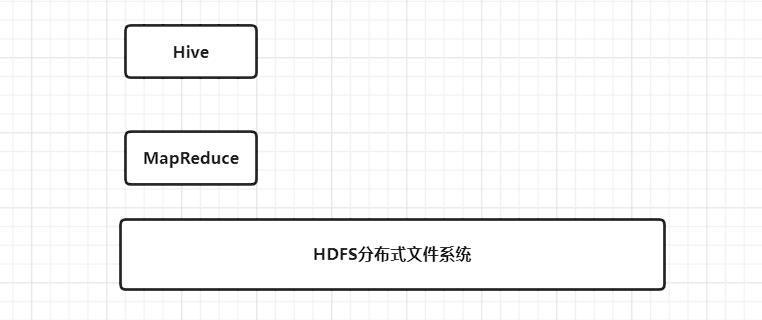
2.4 快一点吧 Spark/Flink
其实大家都已经发现Hive后台使用MapReduce作为执行引擎,实在是有点慢。
Spark/Flink应运而生,它是用来弥补基于MapReduce处理数据速度上的缺点,它的特点是把数据装载到内存中计算而不是去读硬盘。
Spark/Flink支持批处理和流处理,是非常先进的计算引擎。
就好比,当我们修建好MapReduce和Hive层后,过了很多年,发现已经过时了。
我们需要该基础上,保留原来风格的同时,进行翻修。于是得到了Spark/Flink。
此时,我们的大数据生态圈楼房已经进化成了这样。

2.5 Oozie / Azkaban任务调度
在大数据生态圈楼房中,我们已经修建好了计算引擎层,这层每天都需要清洁阿姨定时打扫。于是我们联系了一个家政的阿姨进行每天处理计算引擎层的卫生。
Oozie / Azkaban任务调度组件,就相当于家政阿姨,它需要根据我们设定的时间执行任务。
Oozie / Azkaban任务调度组件只针对于离线批处理任务。
此时,你的大数据生态圈楼房继续升级
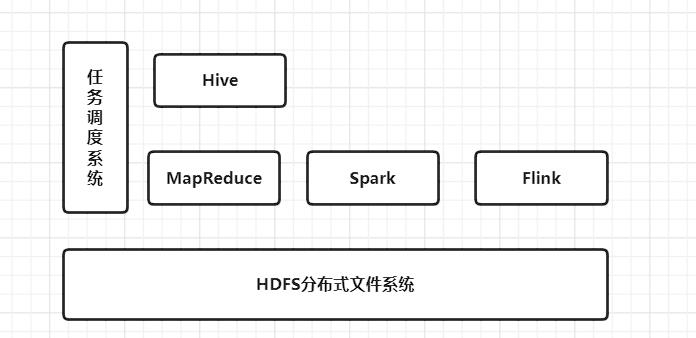
这样,我们就通过任务调度系统,根据我们的需要定时的去处理任务。
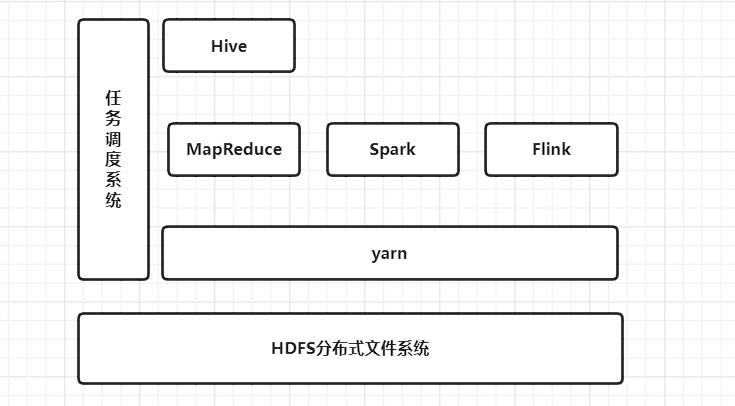
2.6 yarn资源管理器
yarn资源管理器,就好比我们修建大数据生态圈时候的房屋的楼层使用说明,哪一层是干嘛的,这些楼层的使用顺序都是规定安排好的,不然那么多层随便使用,会杂乱无章的,有了yarn我们就在大数据生态圈,互相尊重而有序的使用这些楼层。
简而言之,可以把yarn理解为,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序,Yarn为这些程序提供运算所需的资源(内存、cpu)。
我们的大数据生态圈楼房继续升级。
2.7 数据采集 Sqoop / Flume / DataX/Kafka
大数据生态圈楼房,所有的楼层和楼层使用顺序设计都已经完成后,我们此时差不多就已经完成了修建。是时候安排人员入住了。那么我们通过什么方式去邀请人来入住呢?
这里的人,就相当于数据,只有有了数据,整个大数据生态圈才有意义。
因此我们就有了Sqoop/Flume/DataX/Kafka。
通过这些工具去采集数据到HDFS文件系统,进而处理数据。
大数据生态圈楼,继续升级
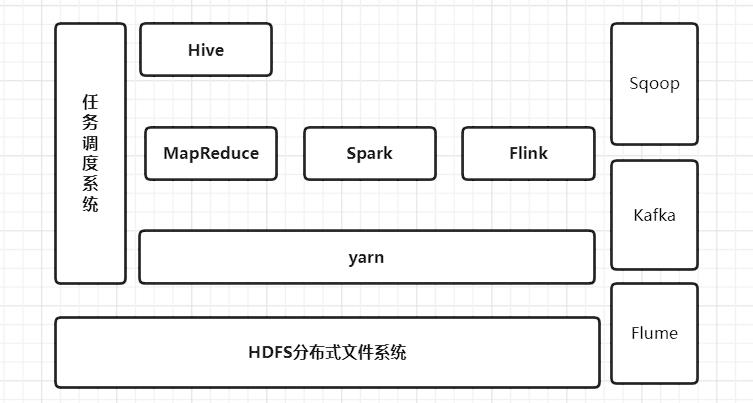
此时,我们的大数据生态圈楼房,基本的建设可以说是完成。剩余的工作就是一些装饰和家具了。
从以上所述,我们可以知道,大数据生态圈的技术栈多而杂乱,只有让它们有序的组合一起工作。
才能解决海量数据的存储和计算。
以上是关于大数据技术生态,不懂你捶我的主要内容,如果未能解决你的问题,请参考以下文章