Scala中的控制结构
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scala中的控制结构相关的知识,希望对你有一定的参考价值。
所谓的内建控制结构是指编程语言中可以使用的一些代码控制语法,如Scala中的if, while, for, try, match, 以及函数调用等。需要注意的是,Scala几乎所有的内建控制结构都会返回一个值,这是由于函数式编程语言被认为是计算值的过程,所以作为函数式编程语言的一个组件,这些内建控制结构也不例外。
如果不好理解函数式编程语言中每一个内建控制结构都会返回一个值这一概念,可以回想一下? :表达式,这个表达式基本上能表明这一概念,作用和if表达式类似,但是会根据条件得到一个分支的值作为返回值。
一、if表达式
Scala的if语句和其他语言中的类似,传入一个判断条件。
比如,在指令式语言中,我们常常这样写
var filename = "default.txt"
if (!args.isEnpty)
filename = args(0)上面的代码中,首先定义一个变量filename并赋给一个初始化值。如果满足if中的判断条件,则将该值进行更新。
在Scala中,可以对上面的代码进行简化,不在需要定义一个变量并且根据条件更新其值。
val filename =
if (!args.isEmpty) args(0)
else "default.txt"if表达式会返回一个值,根据判断条件决定该返回值及类型取自if表达式的哪一个分支。并且当该表达式没有副作用时,直接使用该表达式得到的值和定义一个val变量并赋值的作用是相同的。所以,如果只需要将该文件名打印出来,可以进一步简化成
println(if (!args.isEmpty) args(0) else "default.txt")不过,一般建议还是先将该值赋给一个变量,然后输出该变量的值。这样能够保证代码的可读性和重构性。
二、while循环
1、while循环
while循环有一个判断条件和一个循环体,只要满足判断条件,该循环体就会被执行。下面展示一段求最大公约数的while循环代码
def gcdLoop(x: Long, y: Long): Long =
var a = x
var b = y
while (a != 0)
val temp = a
a = b % a
b = temp
b
2、do-while循环
同样,Scala也提供一个do-while循环结构,和上面这个不同的是,do-while循环首先执行循环体,然后判断循环条件是否满足,以决定下一次循环是否继续。下面这段代码,循环读取输入文本,直到遇到空行为止。
val line = ""
do
line = readLine()
print("Read: " + line)
while (line != "")3、Unit返回值
while和do-while都被称为循环,而不是表达式。这时由于while和do-while循环不会得到一个返回值,或者是它们的返回值为Unit。Unit值被写成(),如下所示,定义一个返回值为Unit的函数greet
def greet() println("hi")
greet() == () 结果如下,表示greet函数的返回值与()是相等的。

需要注意的是,在Scala中对一个var变量重新赋值的语句得到的返回值也是Unit。
比如,如果执行下面这段代码,Scala编译器会认为将一个Unit类型的值与""对比,结果永远为true
var line = ""
while ((line = readLine()) != "")
println("Read: " + line) 运行结果如下,即使某一次无任何输入,该循环仍然会执行并继续。

对于纯函数式编程语言来说,其中是没有while和do-while循环这一概念的。但是Scala提供了这一功能,while循环的使用,使得代码可读性更强。而如果不使用while循环的话,有些代码会写出递归调用的形式,比如下面采用递归的方法计算最大公约数。
def gcd(x: Long, y: Long): Long =
if (y == 0) x else gcd(y, x % y)三、for表达式
for表达可以用于简单的字面变量以及集合类型变量,也可以在遍历时使用一些过滤条件进行过滤,还能够基于旧的集合生成新的集合对象。
1、枚举集合类型
下面这段代码,获取当前路径下所有的文件,并打印出来。其中filesHere变量是一个数组类型的变量,使用file <- filesHere循环遍历数组中的每一个元素。
val filesHere = (new java.io.File(".")).listFiles
for (file <- filesHere)
println(file) 运行结果如下所示,

上面展示的是数组类型变量的for表达式,同样的for表达式还可以用于更多其他类型的变量遍历上。比如
for (i <- 1 to 4)
println("Iteration " + i) 结果如下

2、增加过滤条件
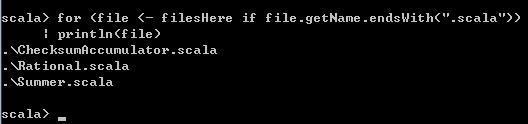
也可以在for表达式中增加一个过滤条件,筛选出其中满足条件的元素进行处理。比如下面这段代码,也是列举出当前路径下的所有文件,但是只显示其中.scala类型的文件。
val filesHere = (new java.io.File(".")).listFiles
for (file <- filesHere if file.getName.endsWith(".scala"))
println(file) 结果如下:
在循环判断中,也可以增加多个判断条件。
for (
file <- filesHere
if file.isFile
if file.getName.endsWith(".scala")
) println(file)3、嵌套循环
如果使用多个<-表达式,就会得到一个嵌套循环结构。例如下面代码中有一个两层嵌套。外层循环遍历filesHere遍历,内层循环遍历fileLines方法读取到的文件中每一行的内容。
def fileLines(file: java.io.File) =
scala.io.Source.fromFile(file).getLines().toList
def grep(pattern: String) =
for
file <- filesHere
if file.getName.endsWith(".scala")
line <- fileLines(file)
if line.trim.matches(pattern)
println(file + ": + line.trim)
grep(".*gcd.*") 注意这里将for表达式的圆括号换成了花括号。
4、流间变量绑定
上面那段嵌套循环的代码中,重复执行了line.trim代码。如果不想重复的话,可以将line.trim的结果通过=符合赋值给一个val变量,这个变量的val关键字可以省略不写。
在下面这段代码中,trimmed变量在for表达式中被引入,并且初始化为line.trim。接下来的代码中两次使用到了这个trimmed变量,一次是在if表达式中,一次是在println操作中。
def grep (pattern: String) =
for
file <- filesHere
if file.getName.endsWith(".scala")
line <- fileLines(file)
trimmed = line.trim
if trimmed.matches(pattern)
println(file + ":" + trimmed)
grep(".*gcd.*") 在原文中,这一小节的英语表述是(Mid-stream variable bindings)。 这里的流间变量绑定是指在for表达式中引入的变量,可以在for表达式的后续其他代码中使用该变量。
5、生成新的集合变量
之所以这里称for为表达式,而不是for循环,是因为for表达式可以获得一个返回值。需要使用到关键字yield。
(1)生成源集合相同类型的新集合
例如下面的代码,找出当前路径下所有的.scala类型的文件,并赋值给一个function。该for表达式函数体每一次执行,都会产生一个file值。当filesHere遍历完成之后,会将所有yield出来的file值存储到同一个集合类型对象中。返回集合的元素类型,与源集合中的元素类型相同。
def scalaFiles =
for
file <- filesHere
if file.getName.endsWith(".scala")
yield file 结果如下,

上面这段代码中需要注意的是yield关键字的位置。正确的格式应该是下面这样的,
for clauses yield body由于上面代码中的函数体比较简单,看不出有什么异常,如果按照下面这种写法,就是错误的
for ( file <- filesHere if file.getName.endsWith(".scala")
yield file
这种错误写法中,yield关键字就是写入了函数体中。
(2)生成其他类型的集合
其实在Scala的for表达式中,也可以生成与源集合不同类型的集合。比如下面这段代码中,首先获取当前路径下的所有.scala文件,然后对每一个文件读取其中的所有行,去重,然后取出其中只包含for关键字的代码,最后,获取这几行代码的字符个数。
其中的fileLines函数得到一个Iterator[String]类型的返回值。
val forLineLengths =
for
file <- filesHere
if file.getName.endsWith(".scala")
line <- fileLines(file)
trimmed = line.trim
if trimmed.matches(".*for.*")
yield trimmed.length 总结一下,有关于for表达式,可以很方便的遍历某个集合,也可在遍历时加入过滤条件对循环的集合进行筛选。同时也可以在for表达式中多次写入<-实现嵌套循环,并且,for表达式中引入的变量可以省略val关键字并在后续多次使用。最后,面对复杂的for表达式时,最好不用圆括号,而改为使用花括号。
四、try表达式异常处理
Scala中的表达式,除了正常执行并得到一个返回值的情况外,还有一种是运行时出现异常。出现异常时,程序可能会被终止,也可以由方法调用者捕获并对该异常作出处理。
1、抛出异常
Scala抛出异常和Java类似,同样适用throw关键字,抛出的这个异常类,也可以由开发者自定义。
throw new IllegalArgumentException 对于throw表达式,Scala其实也对应了一个返回值,其类型为Nothing。
比如下面求一个偶数的一半,当传入的n是偶数时才进行计算,否则直接抛出一个RuntimeException。
val half = (
if (n % 2 == 0)
n / 2
else
throw new RuntimeException("n must be even")) 运行结果如下,当n为3时,直接抛出一个异常,而当n为4时,返回一个Int值2。
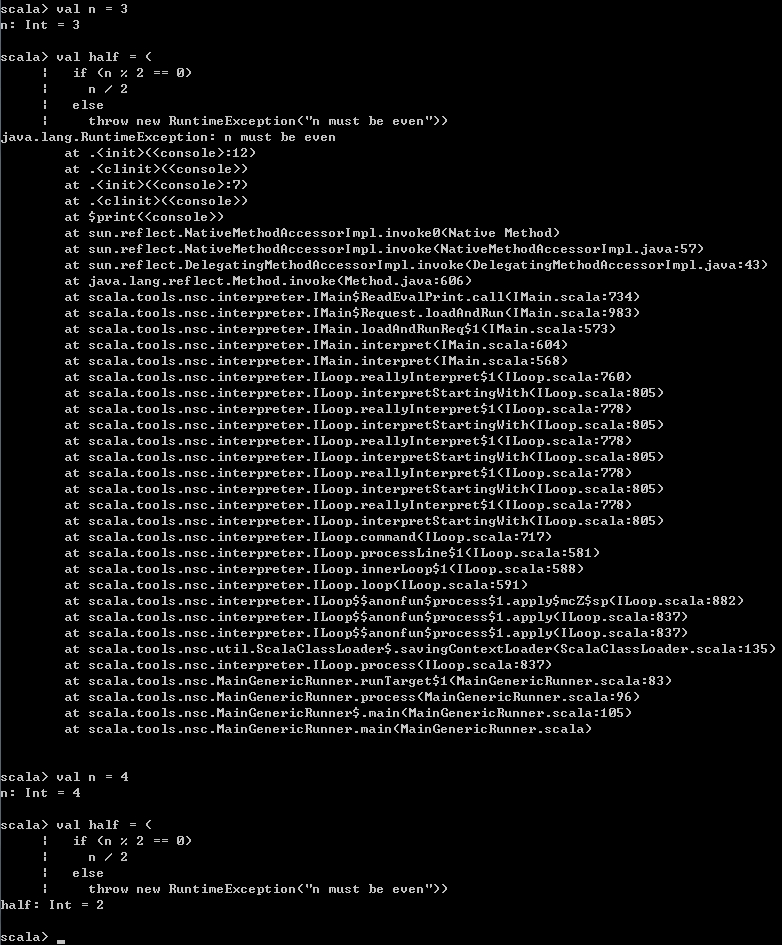
前面提到,if表达式返回值的类型为两个分支计算值的公共父类,而现在throw表达式的的返回值为Nothing,并且在Scala的类层级关系中Nothing是任何类的直接或间接子类。也就是说,对于if表达式来说,某一个分支是throw表达式的话,那么该if表达式最终返回值的类型是有值计算的那一个分支的类型。
2、捕获异常
抛出了异常,如果不加处理,程序就会终止。抛出异常后,可以使用catch关键字捕获该异常,并针对不同的异常作出不同的处理方案。下面的代码展示了一个完成的try...catch代码结构
import java.io.FileReader
import java.io.FileNotFoundException
import java.io.IOException
try
val f = new FileReader("input.txt")
// Use and close file
catch
case ex: FileNotFoundException => // Handle missing file
case ex: IOException => // Handle other I/O error
当抛出异常时,会顺序执行catch代码块中的逻辑。上面代码中,如果抛出FileNotFoundException,那么就会执行文件不存在这一分支的代码。而如果抛出IOException异常,就会执行I/O异常这一部分的逻辑。而如果这两种异常都匹配不到抛出的异常时,程序还是会终止。
3、finally子句
类似于Java代码中,有时候遇到抛出异常而导致程序终止时,可能还希望执行一些收尾的逻辑。比如下面这段代码中,如果读取文件时抛出异常导致程序终止,那么最好在终止前将打开的文件关闭。关闭文件的这段逻辑就写在finally子句中。
import java.io.FileReader
val file = new FileReader("input.txt")
try
// Use the file
finally
file.close() // Be sure to close the file
4、产生一个返回值
类似于其他的控制结构,try-catch-finally代码也会产生一个返回值。
比如下面代码中,对一个URL地址进行处理,如果不抛出异常,那么使用传入的地址构造一个URL对象。如果抛出异常并被捕获到的话,则使用默认地址构造一个URL对象。
import java.net.URL
import java.net.MalformedURLException
def urlFor(path: String) =
try
new URL(path)
catch
case e: MalformedURLException =>
new URL("http://www.scala-lang.org")
如果抛出异常并没有被捕获到,那么返回的结果为Nothing。而finally子句中设置的返回值是无法获取到的,这也是由于程序终止时一般在finally中只需要做一些收尾的操作,而不需要去改变某些变量的值。
如果在finally中显示的return了某个返回值,或者抛出一个异常,那么这个返回值或者抛出的异常会将之前try-catch中应有的返回值覆盖掉。比如
def f(): Int = try return 1 finally return 2 结果如下:

而不显示返回一个值时,最终的返回值为try中的内容。比如
def g(): Int = try 1 finally 2 结果如下:

五、match表达式
match表达式类似于switch表达式,可以在多个待选值中进行选择。
看下面的代码,如果args的长度大于0,那么firstArg变量的值为第一个元素,否则为空字符串。然后,根据firstArg变量的具体内容,如果是salt则打印paper,如果是eggs则打印bacon。而如果不是这三种中的任何一个,则打印huh?。下面代码中的下划线_表示任意匹配。
val firstArg = if (args.length > 0) args(0) else ""
firstArg match
case "salt" => println("pepper")
case "chips" => println("salsa")
case "eggs" => println("bacon")
case _ => println("huh?")
和Java中的switch不同的是,Scala中的match语法可以匹配包括整数,字符串等任意类型的变量,并且在每个case后没有break关键字。而switch和match最大的不同是,match表达式也会有一个返回值。上面的代码片段中,打印每一种情况的显示内容,而接下来这一段代码,会根据匹配情况将字符串赋值给一个变量。
val firstArg = if (!args.isEmpty) args(0) else ""
val friend =
firstArg match
case "salt" => "pepper"
case "chips" => "salsa"
case "eggs" => "bacon"
case _ => "huh?"
println(friend) 可以从下面的结果看到,friend的值为salsa。

以上是关于Scala中的控制结构的主要内容,如果未能解决你的问题,请参考以下文章