一文详解用 eBPF 观测 HTTP
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文详解用 eBPF 观测 HTTP相关的知识,希望对你有一定的参考价值。

前言
随着eBPF推出,由于具有高性能、高扩展、安全性等优势,目前已经在网络、安全、可观察等领域广泛应用,同时也诞生了许多优秀的开源项目,如Cilium、Pixie等,而iLogtail 作为阿里内外千万实例可观测数据的采集器,eBPF 网络可观测特性也预计会在未来8月发布。下文主要基于eBPF观测HTTP 1、HTTP 1.1以及HTTP2的角度介绍eBPF的针对可观测场景的应用,同时回顾HTTP 协议自身的发展。
eBPF基本介绍
eBPF 是近几年 Linux Networkworking 方面比较火的技术之一,目前在安全、网络以及可观察性方面应用广泛,比如CNCF 项目Cilium 完全是基于eBPF 技术实现,解决了传统Kube-proxy在大集群规模下iptables 性能急剧下降的问题。从基本功能上来说eBPF 提供了一种兼具性能与灵活性来自定义交互内核态与用户态的新方式,具体表现为eBPF 提供了友好的api,使得可以通过依赖libbpf、bcc等SDK,将自定义业务逻辑安全的嵌入内核态执行,同时通过BPF Map 机制(不需要多次拷贝)直接在内核态与用户态传递所需数据。

当聚焦在可观测性方面,我们可以将eBPF 类比为Javaagent进行介绍。Javaagent的基本功能是程序启动时对于已存在的字节码进行代理字节码织入,从而在无需业务修改代码的情况下,自动为用户程序加入hook点,比如在某函数进入和返回时添加hook点可以计算此函数的耗时。而eBPF 类似,提供了一系列内核态执行的切入点函数,无需修改代码,即可观测应用的内部状态,以下为常用于可观测性的切入点类型:
- kprobe:动态附加到内核调用点函数,比如在内核exec系统调用前检查参数,可以BPF 程序设置 SEC("kprobe/sys_exec")头部进行切入。
- tracepoints:内核已经提供好的一些切入点,可以理解为静态的kprobe,比如syscall 的connect函数。
- uprobe:与krobe对应,动态附加到用户态调用函数的切入点称为uprobe,相比如kprobe 内核函数的稳定性,uprobe 的函数由开发者定义,当开发者修改函数签名时,uprobe BPF 程序同样需要修改函数切入点签名。
- perf_events:将BPF 代码附加到Perf事件上,可以依据此进行性能分析。
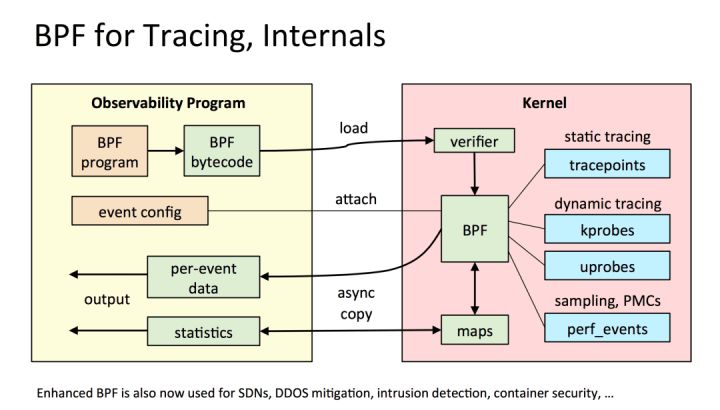
TCP与eBPF
由于本文观测协议HTTP 1、HTTP1.1以及HTTP2 都是基于TCP 模型,所以先回顾一下 TCP 建立连接的过程。首先Client 端通过3次握手建立通信,从TCP协议上来说,连接代表着状态信息,比如包含seq、ack、窗口/buffer等,而tcp握手就是协商出来这些初始值;而从操作系统的角度来说,建立连接后,TCP 创建了INET域的 socket,同时也占用了FD 资源。对于四次挥手,从TCP协议上来说,可以理解为释放终止信号,释放所维持的状态;而从操作系统的角度来说,四次挥手后也意味着Socket FD 资源的回收。
而对于应用层的角度来说,还有一个常用的概念,这就是长连接,但长连接对于TCP传输层来说,只是使用方式的区别:
- 应用层短连接:三次握手+单次传输数据+四次挥手,代表协议HTTP 1
- 应用层长连接:三次握手+多次传输数据+四次挥手,代表协议 HTTP 1.1、HTTP2
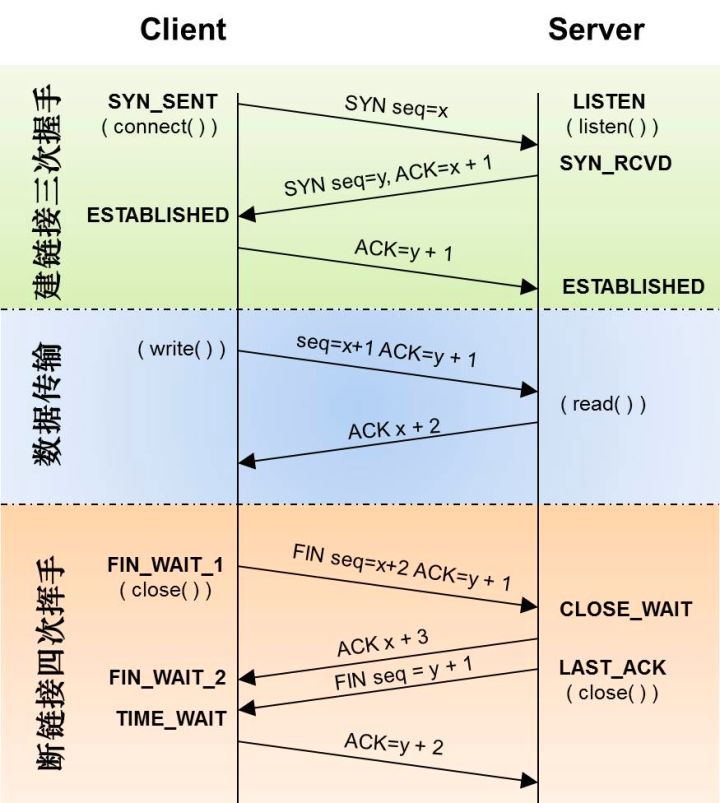
参考下图TCP 建立连接过程内核函数的调用,对于eBPF 程序可以很容易的定义好tracepoints/kprobe 切入点。例如建立连接过程可以切入 accept 以及connect 函数,释放链接过程可以切入close过程,而传输数据可以切入read 或write函数。
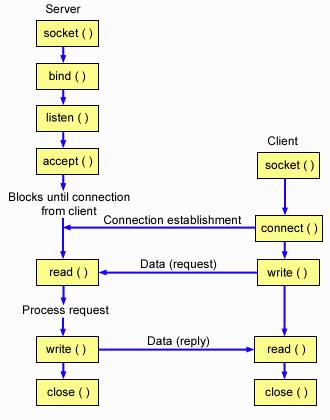
基于TCP 大多数切入点已经被静态化为tracepoints,因此BPF 程序定义如下切入点来覆盖上述提到的TCP 核心函数(sys_enter 代表进入时切入,sys_exit 代表返回时切入)。
SEC("tracepoint/syscalls/sys_enter_connect") SEC("tracepoint/syscalls/sys_exit_connect") SEC("tracepoint/syscalls/sys_enter_accept") SEC("tracepoint/syscalls/sys_exit_accept") SEC("tracepoint/syscalls/sys_enter_accept4") SEC("tracepoint/syscalls/sys_exit_accept4") SEC("tracepoint/syscalls/sys_enter_close") SEC("tracepoint/syscalls/sys_exit_close") SEC("tracepoint/syscalls/sys_enter_write") SEC("tracepoint/syscalls/sys_exit_write") SEC("tracepoint/syscalls/sys_enter_read") SEC("tracepoint/syscalls/sys_exit_read") SEC("tracepoint/syscalls/sys_enter_sendmsg") SEC("tracepoint/syscalls/sys_exit_sendmsg") SEC("tracepoint/syscalls/sys_enter_recvmsg") SEC("tracepoint/syscalls/sys_exit_recvmsg") ....
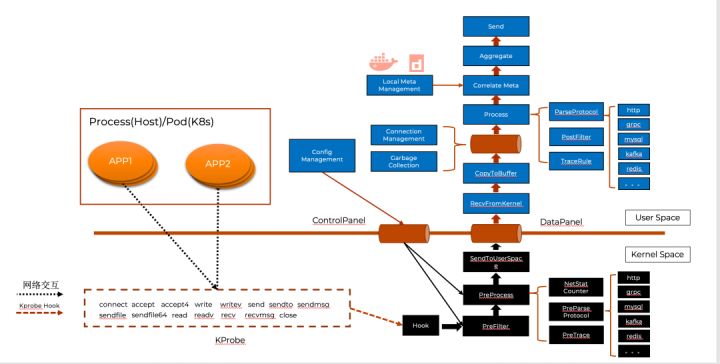
结合上述概念,我们以iLogtail的eBPF 工作模型为例,介绍一个可观测领域的eBPF 程序是如何真正工作的。更多详细内容可以参考此分享: 基于eBPF的应用可观测技术实践。如下图所示,iLogtaileBPF 程序的工作空间分为Kernel Space与User Space。
Kernel Space 主要负责数据的抓取与预处理:
- 抓取:Hook模块会依据KProbe定义拦截网络数据,虚线中为具体的KProbe 拦截的内核函数(使用上述描述的SEC进行定义),如connect、accept 以及write 等。
- 预处理:预处理模块会根据用户态配置进行数据的拦截丢弃以及数据协议的推断,只有符合需求的数据才会传递给SendToUserSpace模块,而其他数据将会被丢弃。其后SendToUserSpace 模块通过eBPF Map 将过滤后的数据由内核态数据传输到用户态。
User Space 的模块主要负责数据分析、聚合以及管理:
- 分析:Process 模块会不断处理eBPF Map中存储的网络数据,首先由于Kernel 已经推断协议类型,Process 模块将根据此类型进行细粒度的协议分析,如分析mysql 协议的SQL、分析HTTP 协议的状态码等。其次由于 Kernel 所传递的连接元数据信息只有Pid 与
- FD 等进程粒度元信息,而对于Kubernetes 可观测场景来说,Pod、Container 等资源定义更有意义,所以Correlate Meta 模块会为Process 处理后的数据绑定容器相关的元数据信息。
- 聚合:当绑定元数据信息后,Aggreate 模块会对数据进行聚合操作以避免重复数据传输,比如聚合周期内某SQL 调用1000次,Aggreate 模块会将最终数据抽象为 XSQL:1000 的形式进行上传。
- 管理:整个eBPF 程序交互着大量着进程与连接数据,因此eBPF 程序中对象的生命周期需要与机器实际状态相符,当进程或链接释放,相应的对象也需要释放,这也正对应着Connection Management 与Garbage Collection 的职责。
eBPF 数据解析
HTTP 1 、HTTP1.1以及HTTP2 数据协议都是基于TCP的,参考上文,一定有以下函数调用:
- connect 函数:函数签名为int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen), 从函数签名入参可以获取使用的socket 的fd,以及对端地址等信息。
- accept 函数:函数签名为int accept(int sockfd, struct sockaddr addr, socklen_t addrlen), 从函数签名入参同样可以获取使用的socket 的fd,以及对端地址等信息。
- sendmsg函数:函数签名为 ssize_t sendmsg(int sockfd, const struct msghdr *msg, int flags),从函数签名可以看出,基于此函数可以拿到发送的数据包,以及使用的socket 的fd信息,但无法直接基于入参知晓对端地址。
- recvmsg函数:函数签名为 ssize_t recvmsg(int sockfd, struct msghdr *msg, int flags),从函数签名可以看出,基于此函数我们拿到接收的数据包,以及使用的socket 的fd信息,但无法直接基于入参知晓对端地址。
- close 函数:函数签名为 int close(int fd),从函数签名可以看出,基于此函数可以拿到即将关闭的fd信息。
HTTP 1 / HTTP 1.1 短连接模式
HTTP 于1996年推出,HTTP 1 在用户层是短连接模型,也就意味着每一次发送数据,都会伴随着connect、accept以及close 函数的调用,这就以为这eBPF程序可以很容易的寻找到connect 的起始点,将传输数据与地址进行绑定,进而构建服务的上下游调用关系。
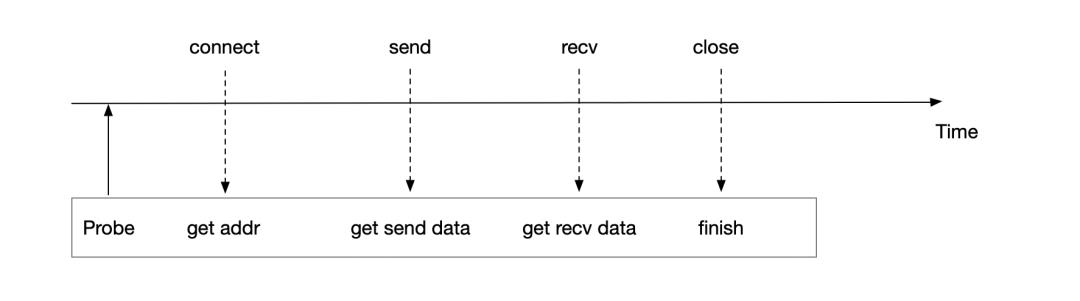
可以看出HTTP 1 或者HTTP1.1 短连接模式是对于eBPF 是非常友好的协议,因为可以轻松的关联地址信息与数据信息,但回到HTTP 1/HTTP1.1 短连接模式 本身来说,‘友好的代价’不仅意味着带来每次TCP 连接与释放连接的消耗,如果两次传输数据的HTTP Header 头相同,Header 头也存在冗余传输问题,比如下列数据的头Host、Accept 等字段。

HTTP 1.1 长连接
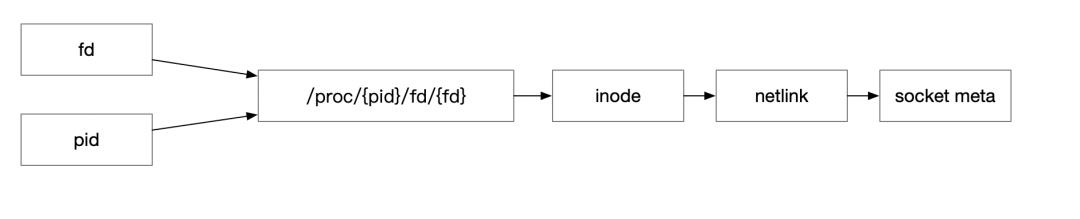
HTTP 1.1 于HTTP 1.0 发布的一年后发布(1997年),提供了缓存处理、带宽优化、错误通知管理、host头处理以及长连接等特性。而长连接的引入也部分解决了上述HTTP1中每次发送数据都需要经过三次握手以及四次挥手的过程,提升了数据的发送效率。但对于使用eBPF 观察HTTP数据来说,也带来了新的问题,上文提到建立地址与数据的绑定依赖于在connect 时进行probe,通过connect 参数拿到数据地址,从而与后续的数据包绑定。但回到长连接情况,假如connect 于1小时之前建立,而此时才启动eBPF程序,所以我们只能探测到数据包函数的调用,如send或recv函数。此时应该如何建立地址与数据的关系呢?

首先可以回到探测函数的定义,可以发现此时虽然没有明确的地址信息,但是可以知道此TCP 报文使用的Socket 与FD 信息。因此可以使用 netlink 获取此Socket 的元信息,进行对长连接补充对端地址,进而在HTTP 1.1 长连接协议构建服务拓扑与分析数据明细。
ssize_t sendmsg(int sockfd, const struct msghdr msg, int flags) ssize_t recvmsg(int sockfd, struct msghdr msg, int flags)
HTTP 2
在HTTP 1.1 发布后,由于冗余传输以及传输模型串行等问题,RPC 框架基本上都是进行了私有化协议定义,如Dubbo 等。而在2015年,HTTP2 的发布打破了以往对HTTP 协议的很多诟病,除解决在上述我们提到的Header 头冗余传输问题,还解决TCP连接数限制、传输效率、队头拥塞等问题,而 gRPC正式基于HTTP2 构建了高性能RPC 框架,也让HTTP 1 时代层出不穷的通信协议,也逐渐走向了归一时代,比如Dubbo3 全面兼容gRPC/HTTP2 协议。
特性
以下内容首先介绍一些HTTP2 与eBPF 可观察性相关的关键特性。
多路复用
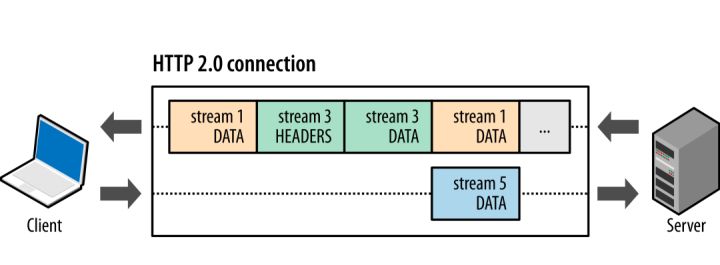
HTTP 1 是一种同步、独占的协议,客户端发送消息,等待服务端响应后,才进行新的信息发送,这种模式浪费了TCP 全双工模式的特性。因此HTTP2 允许在单个连接上执行多个请求,每个请求相应使用不同的流,通过二进制分帧层,为每个帧分配一个专属的stream 标识符,而当接收方收到信息时,接收方可以将帧重组为完整消息,提升了数据的吞吐。此外可以看到由于Stream 的引入,Header 与Data 也进行了分离设计,每次传输数据Heaer 帧发送后为此后Data帧的统一头部,进一步提示了传输效率。
首部压缩
HTTP 首部用于发送与请求和响应相关的额外信息,HTTP2引入首部压缩概念,使用与正文压缩不同的技术,支持跨请求压缩首部,可以避免正文压缩使用算法的安全问题。HTTP2采用了基于查询表和Huffman编码的压缩方式,使用由预先定义的静态表和会话过程中创建的动态表,没有引用索引表的首部可以使用ASCII编码或者Huffman编码传输。
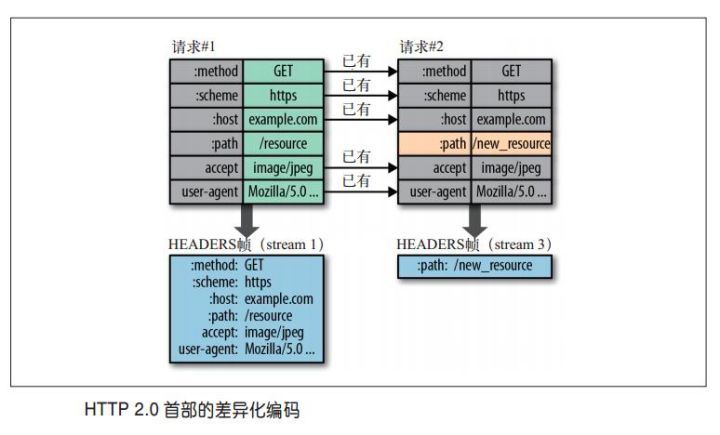
但随着性能的提升,也意味着越来越多的数据避免传输,这也同时意味着对eBPF 程序可感知的数据会更少,因此HTTP2协议的可观察性也带来了新的问题,以下我们使用gRPC不同模式以及Wireshark 分析HTTP2协议对eBPF 程序可观测性的挑战。
GRPC
Simple RPC
Simple RPC 是GRPC 最简单的通信模式,请求和响应都是一条二进制消息,如果保持连接可以类比为HTTP 1.1 的长连接模式,每次发送收到响应,之后再继续发送数据。
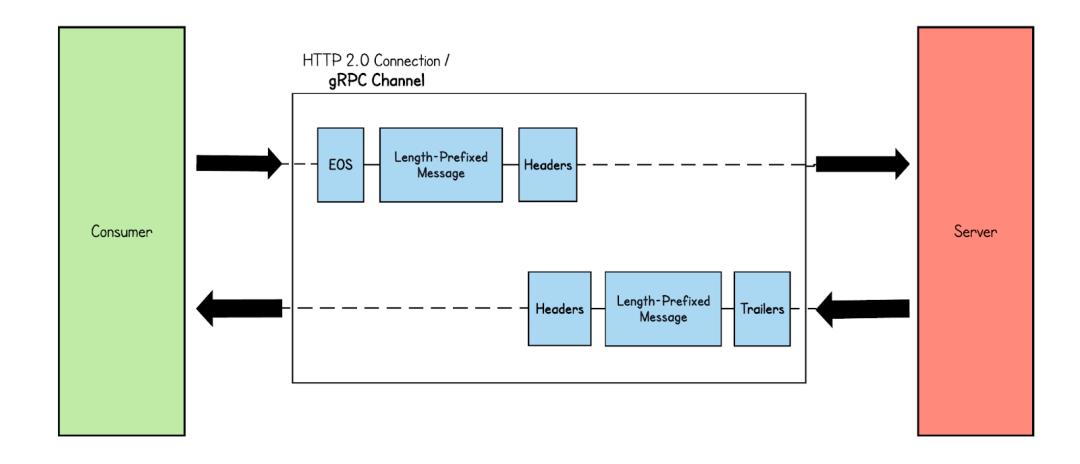
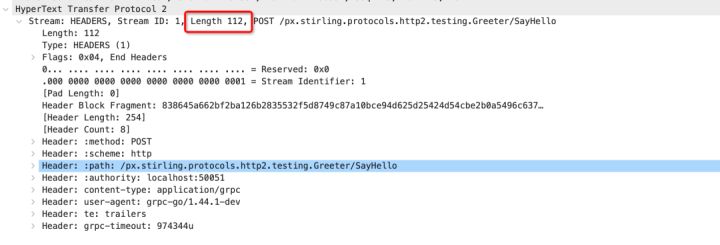
但与HTTP 1 不同的是首部压缩的引入,如果维持长连接状态,后续发的数据包Header 信息将只存储索引值,而不是原始值,我们可以看到下图为Wirshark 抓取的数据包,首次发送是包含完整Header帧数据,而后续Heders 帧长度降低为15,减少了大量重复数据的传输。

Stream 模式
Stream 模式是gRPC 常用的模式,包含Server-side streaming RPC,Client-side streaming RPC,Bidirectional streaming RPC,从传输编码上来说与Simple RPC 模式没有不同,都分为Header 帧、Data帧等。但不同的在于Data 帧的数量,Simple RPC 一次发送或响应只包含一个Data帧 模式,而Stream 模式可以包含多个。
1、Server-side streaming RPC:与Simple RPC 模式不同,在Server-side streaming RPC 中,当从客户端接收到请求时,服务器会发回一系列响应。此响应消息序列在客户端发起的同一 HTTP 流中发送。如下图所示,服务器收到来自客户端的消息,并以帧消息的形式发送多个响应消息。最后,服务器通过发送带有呼叫状态详细信息的尾随元数据来结束流。
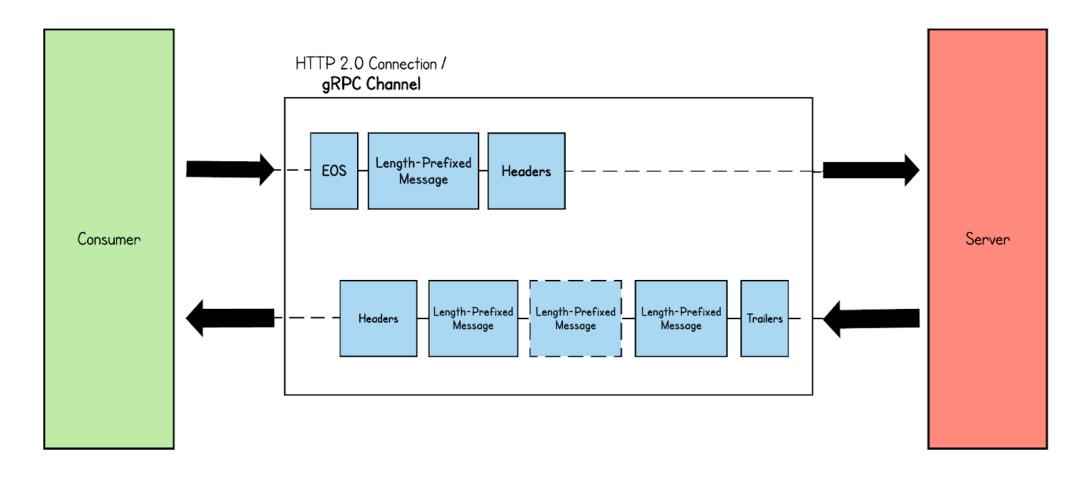
2、Client-side streaming RPC: 在客户端流式 RPC 模式中,客户端向服务器发送多条消息,而服务器只返回一条消息。
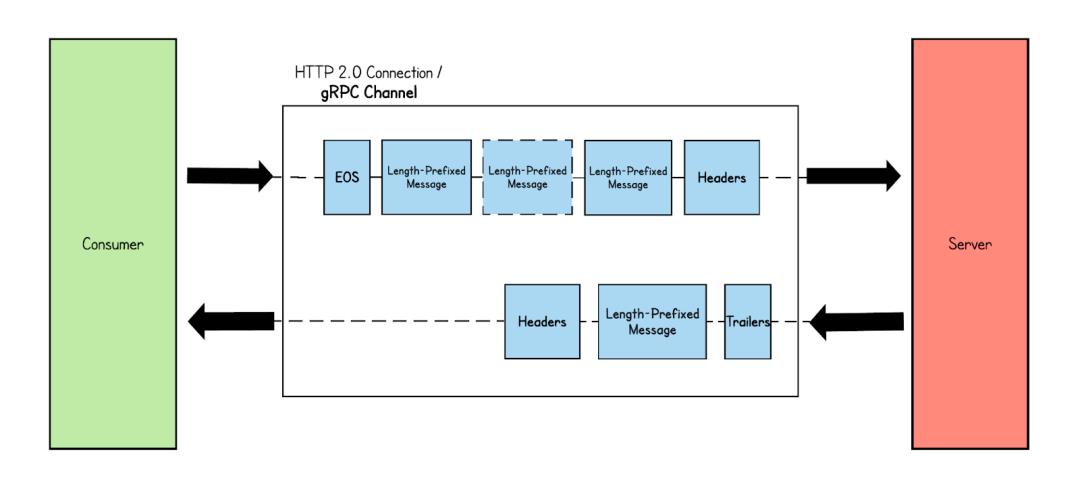
3、Bidirectional streaming RPC:客户端和服务器都向对方发送消息流。客户端通过发送标头帧来设置 HTTP 流。建立连接后,客户端和服务器都可以同时发送消息,而无需等待对方完成。
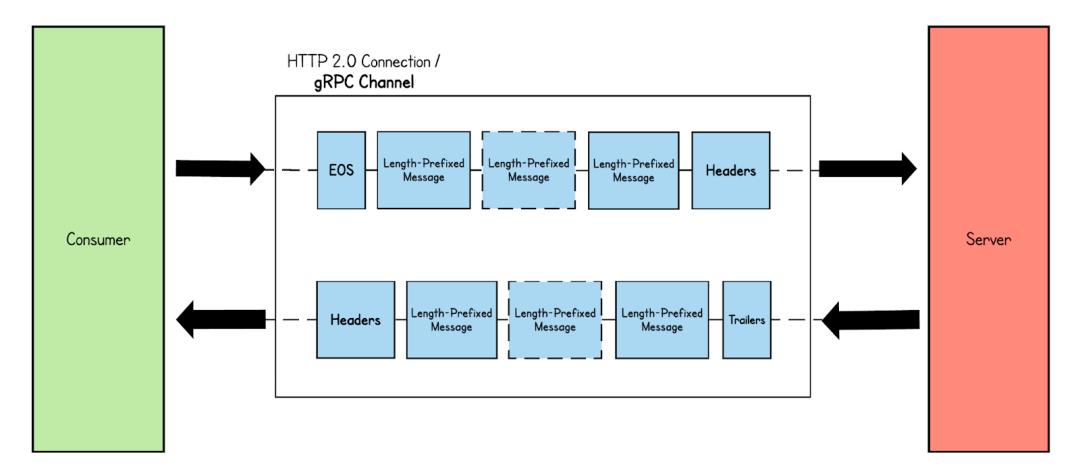
tracepoint/kprobe的挑战
从上述wirshark 报文以及协议模式可以看出,历史针对HTTP1时代使用的tracepoint/kprobe 会存在以下挑战:
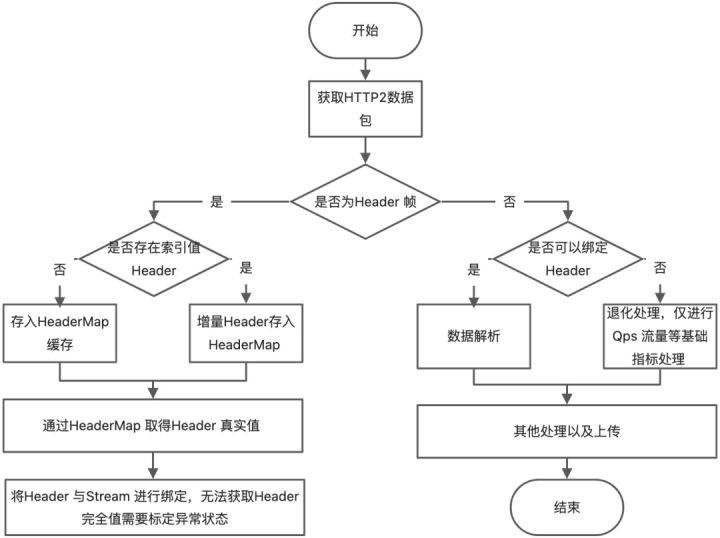
- Stream 模式: 比如在Server-side stream 下,假如tracepoint/kprobe 探测的点为Data帧,因Data 帧因为无法关联Header 帧,都将变成无效Data 帧,但对于gRPC 使用场景来说还好,一般RPC 发送数据和接受数据都很快,所以很快就会有新的Header 帧收到,但这时会遇到更大的挑战,长连接下的首部压缩。
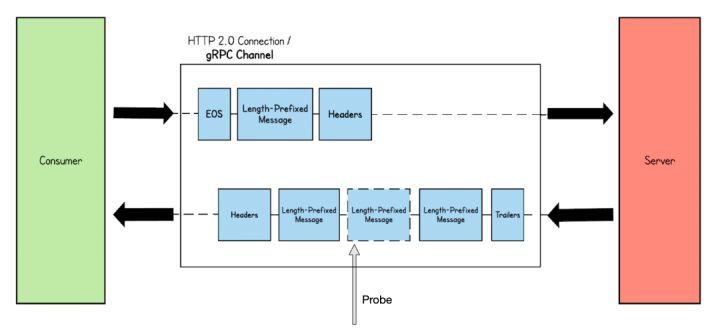
- 长连接+首部压缩:当HTTP2 保持长连接,connect 后的第一个Stream 传输的Header 会为完整数据,而后续Header帧如与前置Header帧存在相同Header 字段,则数据传输的为地址信息,而真正的数据信息会交给Server 或Client 端的应用层SDK 进行维护,而如下图eBPF tracepoints/kprobe 在stream 1 的尾部帧才进行probe,对于后续的Header2 帧大概率不会存在完整的Header 元数据,如下图Wireshark 截图,包含了很多Header 信息的Header 长度仅仅为15,可以看出eBPF tracepoints/kprobe 对于这种情况很难处理。
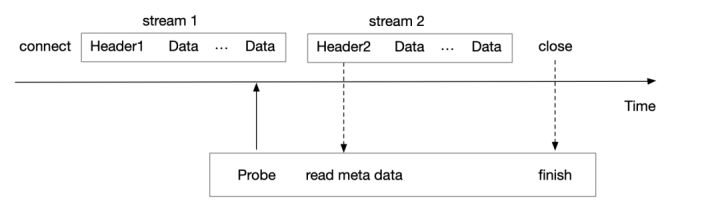
从上文可知,HTTP2 可以归属于有状态的协议,而Tracepoint/Kprobe 对有状态的协议数据很难处理完善,某些场景下只能做到退化处理,以下为使用Tracepoint/Kprobe 处理的基本流程。
Uprobe 可行吗?
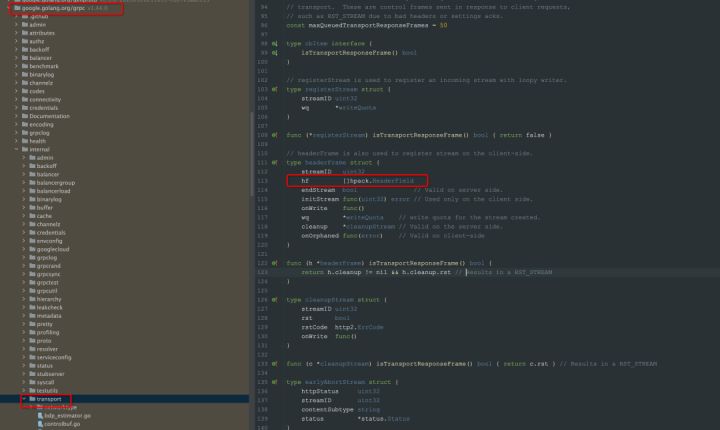
从上述tracepoint/kprobe 的挑战可以看到,HTTP 2 是一种很难被观测的协议,在HTTP2 的协议规范上,为减少Header 的传输,client 端以及server 端都需要维护Header 的数据,下图是grpc 实现的HTTP2 客户端维护Header 元信息的截图,所以在应用层可以做到拿到完整Header数据,也就绕过来首部压缩问题,而针对应用层协议,eBPF 提供的探测手段是Uprobe(用户态),而Pixie 项目也正是基于Uprobe 实践了gRPC HTTP2 流量的探测,详细内容可以参考此文章[1]。
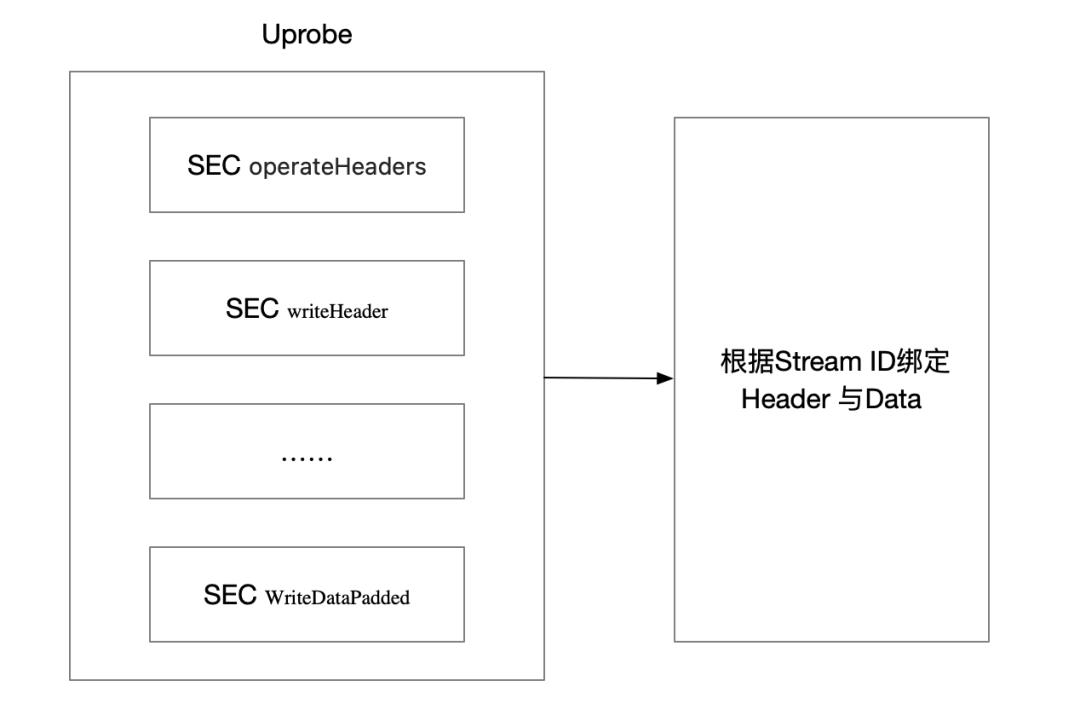
下图展示了使用Uprobe 观测Go gRPC 流量的基本流程,如其中writeHeader 的函数定义为 func (l *loopyWriter) writeHeader(streamID uint32, endStream bool, hf []hpack.HeaderField, onWrite func()), 可以看到明确的Header 文本。
Kprobe 与Uprobe 对比
从上文可以看出Uprobe 实现简单,且不存在数据退化的问题,但Uprobe 真的完美吗?
- 兼容性:上述方案仅仅是基于Golang gRPC 的 特定方法进行探测,也就意味着上述仅能覆盖Golang gRPC 流量的观察,对于Golang 其他HTTP2 库无法支持。
- 多语言性:Uprobe 只能基于方法签名进行探测,更适用于C/GO 这种纯编译型语言,而对于Java 这种JVM 语言,因为运行时动态生成符号表,虽然可以依靠一些javaagent 将java 程序用于Uprobe,但是相对于纯编译型语言,用户使用成本或改造成本还是会更高一些。
- 稳定性:Uprobe 相对于tracepoint/kprobe 来说是不稳定的,假如探测的函数函数签名有改变,这就意味着Uprobe 程序将无法工作,因为函数注册表的改变将使得Uprobe 无法找到切入点。
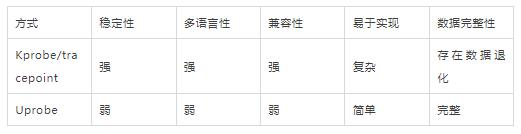
综合下来2种方案对比如下,可以看到2种方案对于HTTP2(有状态)的观测都存在部分取舍:
总结
上述我们回顾了HTTP1到HTTP2 时代的协议变迁,也看到HTTP2 提升传输效率做的种种努力,而正是HTTP2的巨大效率提升,也让gRPC选择了直接基于HTTP2 协议构建,而也是这种选择,让gRPC 成为了RPC 百家争鸣后是隐形事实协议。但我们也看到了协议的进步意味着更少的数据交互,也让数据可观察变得更加困难,比如HTTP2 使用eBPF目前尚无完美的解决方法,或使用Kprobe 观察,选择的多语言性、流量拓扑分析、但容许了失去流量细节的风险;或使用Uprobe 观察,选择了数据的细节,拓扑,但容许了多语言的兼容性问题。
iLogtail致力于打造覆盖Trace、Metrics 以及Logging 的可观测性的统一Agent,而eBPF 作为目前可观测领域的热门采集技术,提供了无侵入、安全、高效观测流量的能力,预计8月份,我们将在iLogtail Cpp正式开源后发布此部分功能,欢迎大家关注和互相交流。
参考:
TCP 的几个状态:https://www.s0nnet.com/archives/tcp-status
HTTP2.0的总结:https://liyaoli.com/2015-04-18/HTTP-2.0.html
Transmission Control Protocol:https://en.wikipedia.org/wiki/Transmission_Control_Protocol
Computer Networks:https://www.cse.iitk.ac.in/users/dheeraj/cs425/lec18.html
Hypertext_Transfer_Protocol:https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
gRPC: A Deep Dive into the Communication Pattern:https://thenewstack.io/grpc-a-deep-dive-into-the-communication-pattern/
ebpf2-http2-tracing:https://blog.px.dev/ebpf-http2-tracing/
深入理解Linux socket:https://www.modb.pro/db/153725
基于eBPF的应用可观测技术实践:https://www.bilibili.com/video/BV1Gg411d7tq
作者 | 少旋
本文为阿里云原创内容,未经允许不得转载。
以上是关于一文详解用 eBPF 观测 HTTP的主要内容,如果未能解决你的问题,请参考以下文章
XDP/eBPF — 基于 eBPF 的 Linux Kernel 可观测性
深度解析|基于 eBPF 的 Kubernetes 一站式可观测性系统