Day702.监控Tomcat的性能 -深入拆解 Tomcat & Jetty
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day702.监控Tomcat的性能 -深入拆解 Tomcat & Jetty相关的知识,希望对你有一定的参考价值。
监控Tomcat的性能
Hi,我是阿昌,今天学习记录的是关于监控Tomcat的性能。
监控 Tomcat 哪些关键指标,如何通过 JConsole 来监控它们。
如果系统没有暴露 JMX 接口,我们还可以通过命令行来查看 Tomcat 的性能指标。
一、Tomcat 的关键指标
Tomcat 的关键指标有吞吐量、响应时间、错误数、线程池、CPU以及 JVM 内存。
前三个指标是我们最关心的业务指标,Tomcat 作为服务器,就是要能够又快有好地处理请求,因此吞吐量要大、响应时间要短,并且错误数要少。
而后面三个指标是跟系统资源有关的,当某个资源出现瓶颈就会影响前面的业务指标,比如线程池中的线程数量不足会影响吞吐量和响应时间;但是线程数太多会耗费大量 CPU,也会影响吞吐量;
当内存不足时会触发频繁地 GC,耗费 CPU,最后也会反映到业务指标上来。那如何监控这些指标呢?
Tomcat 可以通过 JMX 将上述指标暴露出来的。
JMX(Java Management Extensions,即 Java 管理扩展)是一个为应用程序、设备、系统等植入监控管理功能的框架。
JMX 使用管理 MBean 来监控业务资源,这些 MBean 在 JMX MBean 服务器上注册,代表 JVM 中运行的应用程序或服务。每个 MBean 都有一个属性列表。JMX 客户端可以连接到 MBean Server 来读写 MBean 的属性值。
JMX 的工作原理图:

Tomcat 定义了一系列 MBean 来对外暴露系统状态,接下来我们来看看如何通过 JConsole 来监控这些指标。
二、通过 JConsole 监控 Tomcat
首先我们需要开启 JMX 的远程监听端口,具体来说就是设置若干 JVM 参数。我们可以在 Tomcat 的 bin 目录下新建一个名为setenv.sh的文件(或者setenv.bat,根据你的操作系统类型),然后输入下面的内容:
export JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote"
export JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=9001"
export JAVA_OPTS="$JAVA_OPTS -Djava.rmi.server.hostname=x.x.x.x"
export JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.ssl=false"
export JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.authenticate=false"
重启 Tomcat,这样 JMX 的监听端口 9001 就开启了,接下来通过 JConsole 来连接这个端口。
jconsole x.x.x.x:9001
我们可以看到 JConsole 的主界面:

前面我提到的需要监控的关键指标有吞吐量、响应时间、错误数、线程池、CPU 以及 JVM 内存,接下来我们就来看看怎么在 JConsole 上找到这些指标。
1、吞吐量、响应时间、错误数
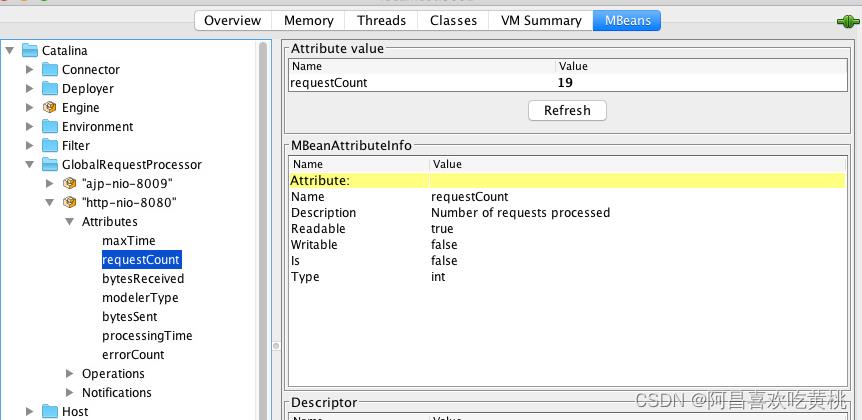
在 MBeans 标签页下选择 GlobalRequestProcessor,这里有 Tomcat 请求处理的统计信息。
你会看到 Tomcat 中的各种连接器,展开“http-nio-8080”,你会看到这个连接器上的统计信息,其中 maxTime 表示最长的响应时间,processingTime 表示平均响应时间,requestCount 表示吞吐量,errorCount 就是错误数。
2、线程池
选择“线程”标签页,可以看到当前 Tomcat 进程中有多少线程,如下图所示:
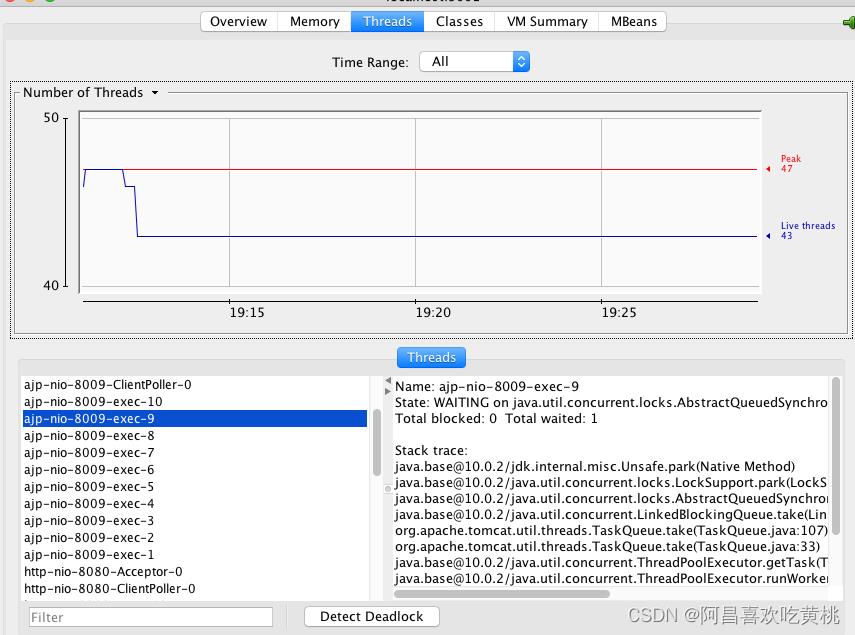
图的左下方是线程列表,右边是线程的运行栈,这些都是非常有用的信息。
如果大量线程阻塞,通过观察线程栈,能看到线程阻塞在哪个函数,有可能是 I/O 等待,或者是死锁。
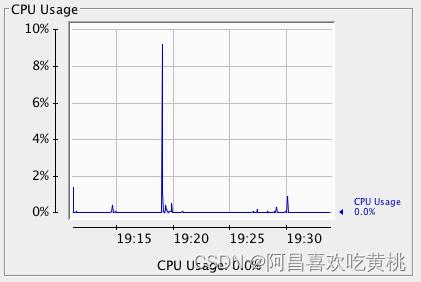
3、CPU
在主界面可以找到 CPU 使用率指标,请注意这里的 CPU 使用率指的是 Tomcat 进程占用的 CPU,不是主机总的 CPU 使用率。
4、JVM 内存
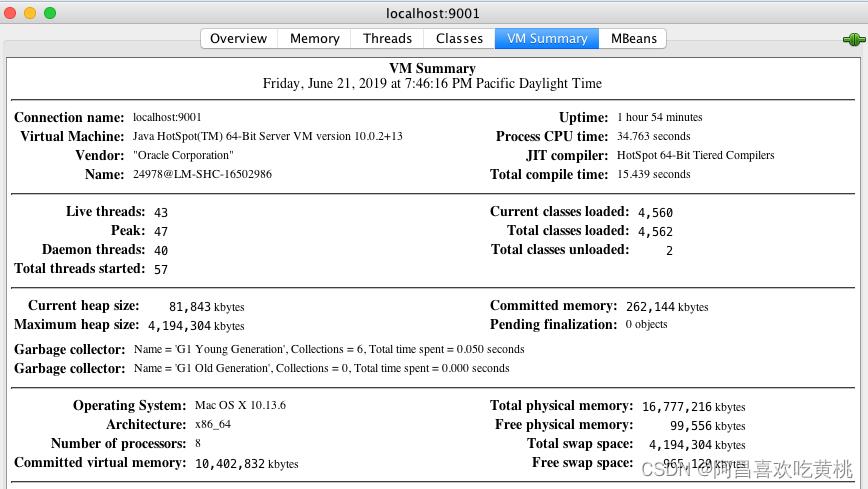
选择“内存”标签页,你能看到 Tomcat 进程的 JVM 内存使用情况。

你还可以查看 JVM 各内存区域的使用情况,大的层面分堆区和非堆区
堆区里有分为 Eden、Survivor 和 Old。选择“VM Summary”标签,可以看到虚拟机内的详细信息
三、命令行查看 Tomcat 指标
极端情况下如果 Web 应用占用过多 CPU 或者内存,又或者程序中发生了死锁,导致 Web 应用对外没有响应,监控系统上看不到数据,这个时候需要我们登陆到目标机器,通过命令行来查看各种指标。
首先我们通过 ps 命令找到 Tomcat 进程,拿到进程 ID。

接着查看进程状态的大致信息,通过cat/proc//status命令:
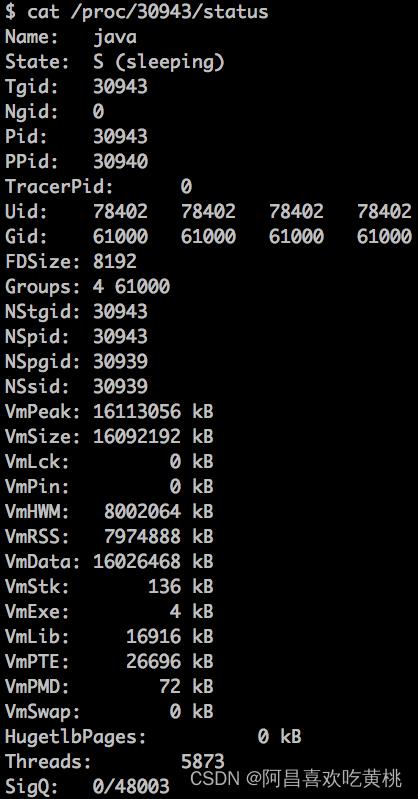
监控进程的 CPU 和内存资源使用情况:

查看 Tomcat 的网络连接,比如 Tomcat 在 8080 端口上监听连接请求,通过下面的命令查看连接列表:
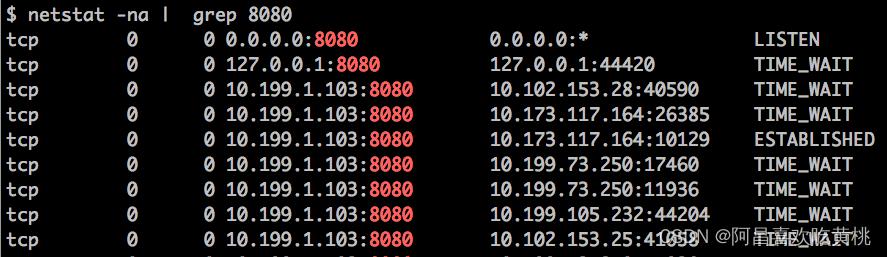
你还可以分别统计处在“已连接”状态和“TIME_WAIT”状态的连接数:

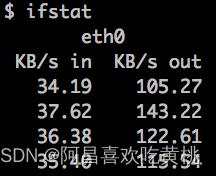
通过ifstat来查看网络流量,大致可以看出 Tomcat 当前的请求数和负载状况。
四、实战案例
在这个实战案例中,我们会创建一个 Web 应用,根据传入的参数 latency 来休眠相应的秒数,目的是模拟当前的 Web 应用在访问下游服务时遇到的延迟。
然后用 JMeter 来压测这个服务,通过 JConsole 来观察 Tomcat 的各项指标,分析和定位问题。
主要的步骤有:
创建一个 Spring Boot 程序,加入下面代码所示的一个 RestController:
@RestController
public class DownStreamLatency
@RequestMapping("/greeting/latency/seconds")
public Greeting greeting(@PathVariable long seconds)
try
Thread.sleep(seconds * 1000);
catch (InterruptedException e)
e.printStackTrace();
Greeting greeting = new Greeting("Hello World!");
return greeting;
从上面的代码我们看到,程序会读取 URL 传过来的 seconds 参数,先休眠相应的秒数,再返回请求。这样做的目的是,客户端压测工具能够控制服务端的延迟。
为了方便观察 Tomcat 的线程数跟延迟之间的关系,还需要加大 Tomcat 的最大线程数,我们可以在application.properties文件中加入这样一行:
server.tomcat.max-threads=1000
启动 JMeter 开始压测,这里我们将压测的线程数设置为 100:
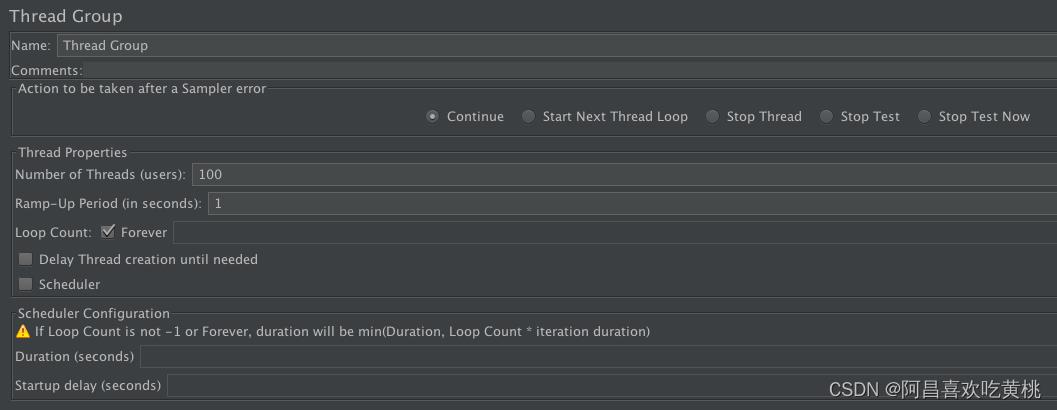
请你注意的是,我们还需要将客户端的 Timeout 设置为 1000 毫秒,这是因为 JMeter 的测试线程在收到响应之前,不会发出下一次请求,这就意味我们没法按照固定的吞吐量向服务端加压。
而加了 Timeout 以后,JMeter 会有固定的吞吐量向 Tomcat 发送请求。
开启测试,这里分三个阶段,第一个阶段将服务端休眠时间设为 2 秒,然后暂停一段时间。
第二和第三阶段分别将休眠时间设置成 4 秒和 6 秒。

最后我们通过 JConsole 来观察结果:
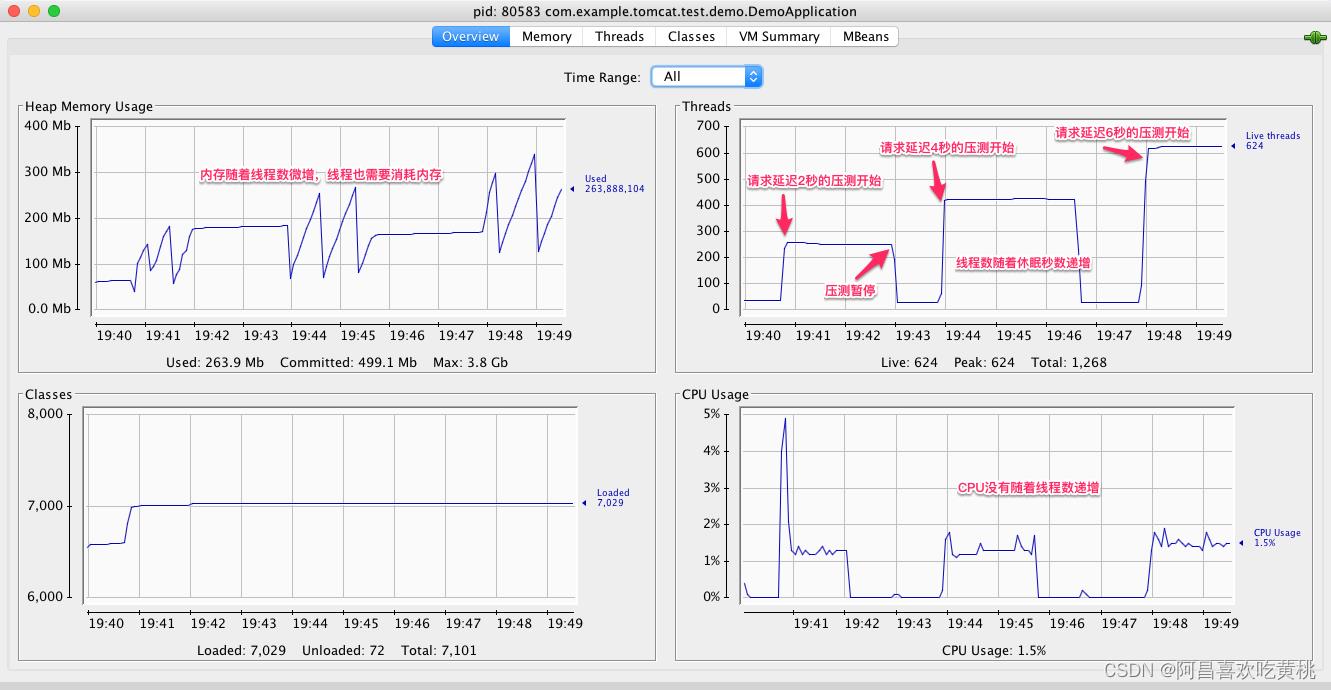
下面我们从线程数、内存和 CPU 这三个指标来分析 Tomcat 的性能问题。
- 首先看线程数,在第一阶段时间之前,线程数大概是 40,第一阶段压测开始后,线程数增长到 250。为什么是 250 呢?这是因为 JMeter 每秒会发出 100 个请求,每一个请求休眠 2 秒,因此 Tomcat 需要 200 个工作线程来干活;此外 Tomcat 还有一些其他线程用来处理网络通信和后台任务,所以总数是 250 左右。第一阶段压测暂停后,线程数又下降到 40,这是因为线程池会回收空闲线程。第二阶段测试开始后,线程数涨到了 420,这是因为每个请求休眠了 4 秒;同理,我们看到第三阶段测试的线程数是 620。
- 我们再来看 CPU,在三个阶段的测试中,CPU 的峰值始终比较稳定,这是因为 JMeter 控制了总体的吞吐量,因为服务端用来处理这些请求所需要消耗的 CPU 基本也是一样的。
- 各测试阶段的内存使用量略有增加,这是因为线程数增加了,创建线程也需要消耗内存。
从上面的测试结果我们可以得出一个结论:对于一个 Web 应用来说,下游服务的延迟越大,Tomcat 所需要的线程数越多,但是 CPU 保持稳定。所以如果你在实际工作碰到线程数飙升但是 CPU 没有增加的情况,这个时候你需要怀疑,你的 Web 应用所依赖的下游服务是不是出了问题,响应时间是否变长了。
五、总结
Tomcat 中的关键的性能指标以及如何监控这些指标:
主要有吞吐量、响应时间、错误数、线程池、CPU 以及 JVM 内存。
在实际工作中,我们需要通过观察这些指标来诊断系统遇到的性能问题,找到性能瓶颈。
如果我们监控到 CPU 上升,这时我们可以看看吞吐量是不是也上升了,如果是那说明正常;
如果不是的话,可以看看 GC 的活动,如果 GC 活动频繁,并且内存居高不下,基本可以断定是内存泄漏。
请问工作中你如何监控 Web 应用的健康状态?遇到性能问题的时候是如何做问题定位的呢?
使用prometheus + grafana 监控各种指标,每天上班前看一下昨天的情况,设置好阈值,如果达到就报警。
以上是关于Day702.监控Tomcat的性能 -深入拆解 Tomcat & Jetty的主要内容,如果未能解决你的问题,请参考以下文章