论文笔记:SAITS: SELF-ATTENTION-BASED IMPUTATION FOR TIMESERIES
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:SAITS: SELF-ATTENTION-BASED IMPUTATION FOR TIMESERIES相关的知识,希望对你有一定的参考价值。
对time-series 使用self-attention来进行补全
1 introduction
- 传统的处理缺失数据的方式一般有两个分类
- 直接删去只有部分观测值的样本
- 使用数据补全,将合适的数据填入
- 直接删去的不足
- 直接删去会导致偏差;合适的数据补全是无偏的
- 部分观测样本也是有一定的意义的
- 目前一些模型的不足
- BRITS、GAIN、E2GAN等模型都是autoregressive 模型(xt的数值取决于之前1~t-1中一部分数值)
- ——>会导致compounding errors(个人理解是误差累计?就
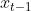 的误差会累加到xt上)
的误差会累加到xt上)
- ——>会导致compounding errors(个人理解是误差累计?就
- NAOMI是non-autoregressive模型
- 但是他的内部机制(循环)会导致补全速度很慢
- BRITS、GAIN、E2GAN等模型都是autoregressive 模型(xt的数值取决于之前1~t-1中一部分数值)
- self-attention机制,既是non-autoregressive,又可以解决RNN中速度慢&内存限制的问题
- ——>可以避免compounding error的问题
- ——>可以让补全质量更高,速度更快
- 这篇论文提出了SAITS (Self-Attention-based Imputation for Time Series) ,利用self-attention来进行时间序列补全
2 related works
- 基于RNN的模型
- GRU-D、BRITS。。。
- 基于RNN的模型比较费时,同时有内存的约束
- ——>处理长期时间序列的任务很困难
- 会遇到compounding error的问题
- 基于GAN的模型+基于VAE的模型
- GRUI、E2GAN、NAOMI
- GPPVAE、GPVAE
- 高斯过程先验是为了让数据能够被嵌入到更平滑&更可解释的表达中
- 基于GAN和VAE的模型都是生成模型,因而训练起来比较复杂
- GAN模型,由于他们损失函数的形式,会需要不收敛、表现不佳的情况
- VAE模型,他们由有隐空间中采样得到的
- ——>往往得不到固定的结构/数据分布
- ——>使得补全内容难以解释,后续分析比较困难
- 基于self-attention的模型
- CSDA:cross-dimensional self-attention,三个维度(time,location,measurement)的自注意力,以补全时空数据中的确实信息【2019,未开源】
- CDSA: cross dimensional self-attention for multivariate, geo-tagged time series imputation
- DeepMVI:多维时间序列的缺失值不全【2021,未开源】
- Transformer with a convolutional window feature and a kernel regression
- Missing value imputation on multidimensional time series
-
NRTSI【2021】
- Nrtsi: Non-recurrent time series imputation
- 将时间序列处理成(time,data)的元组,然后使用Transformer 的encoder来进行建模
- CSDA:cross-dimensional self-attention,三个维度(time,location,measurement)的自注意力,以补全时空数据中的确实信息【2019,未开源】
3 方法部分
3.0 时间序列
 多维时间序列
多维时间序列 丢失数据的mask矩阵
丢失数据的mask矩阵 人为mask掉一些观察值,这是人为mask的identity矩阵
人为mask掉一些观察值,这是人为mask的identity矩阵
3.1 联合训练方法
包含两个学习任务:Masked Imputation Task (MIT) , Observed Reconstruction Task (ORT)
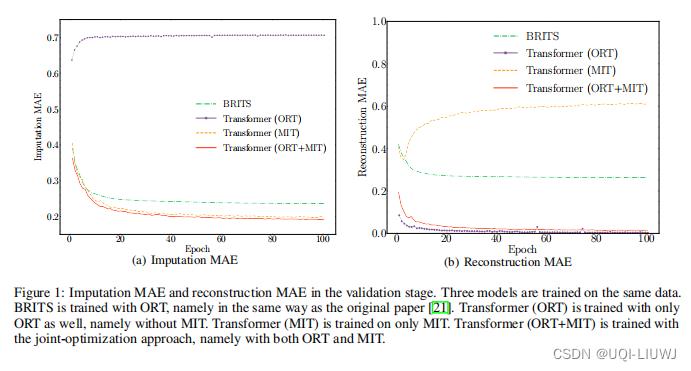
如果只学习ORT/MIT,那么另一个任务上(MIT/ORT),效果会很一般。
如果联合训练,那么在两个任务上效果都不错。
3.1.1 Masked Imputation Task (MIT)
希望能够很好地补全人为mask掉的那些点。
使用MAE作为补全损失函数
3.1.2 Observed Reconstruction Task (ORT)
希望观测值能够被很好地重构
也是使用MAE作为重构损失函数
3.2 模型各组件介绍
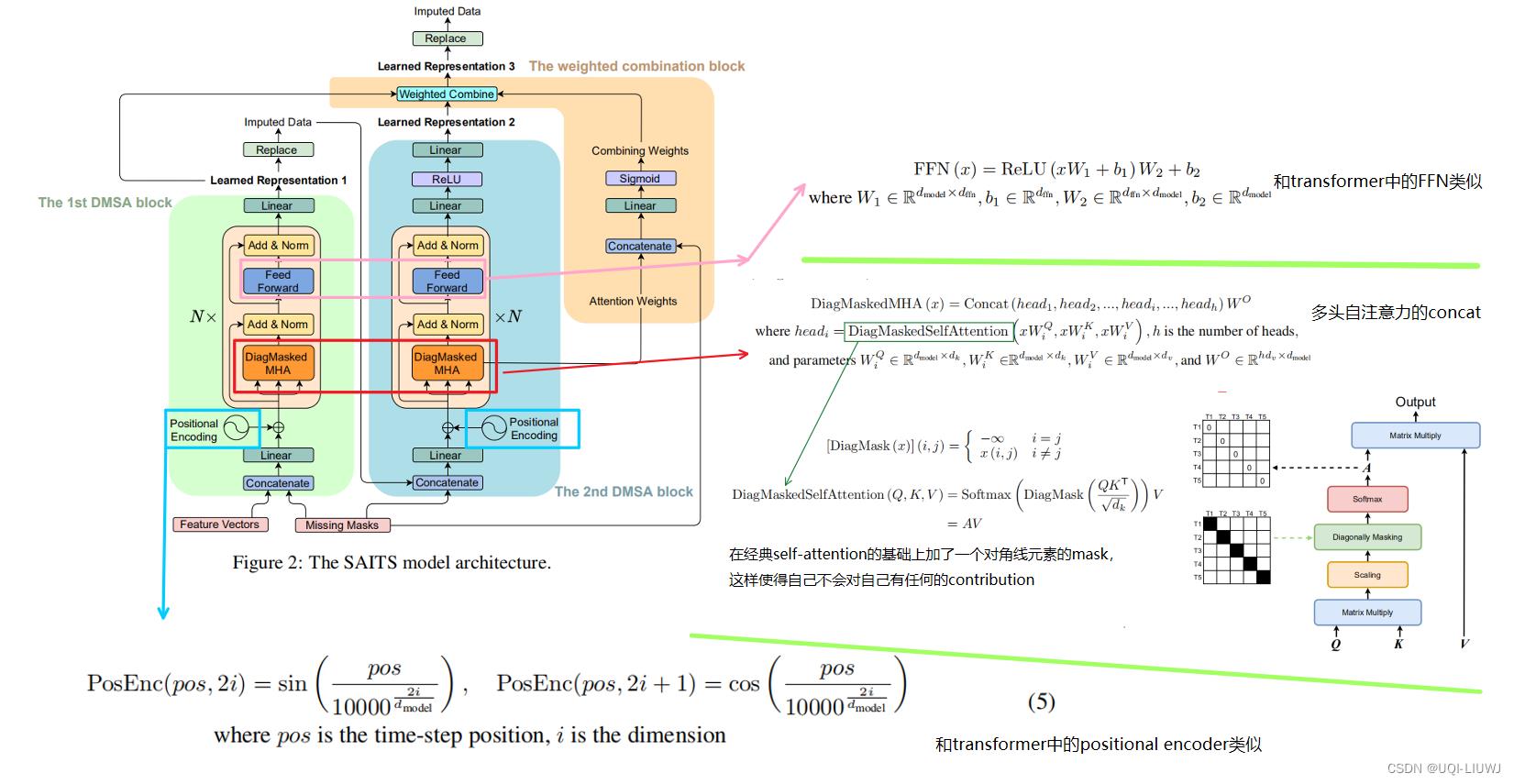
3.3 模型流程介绍
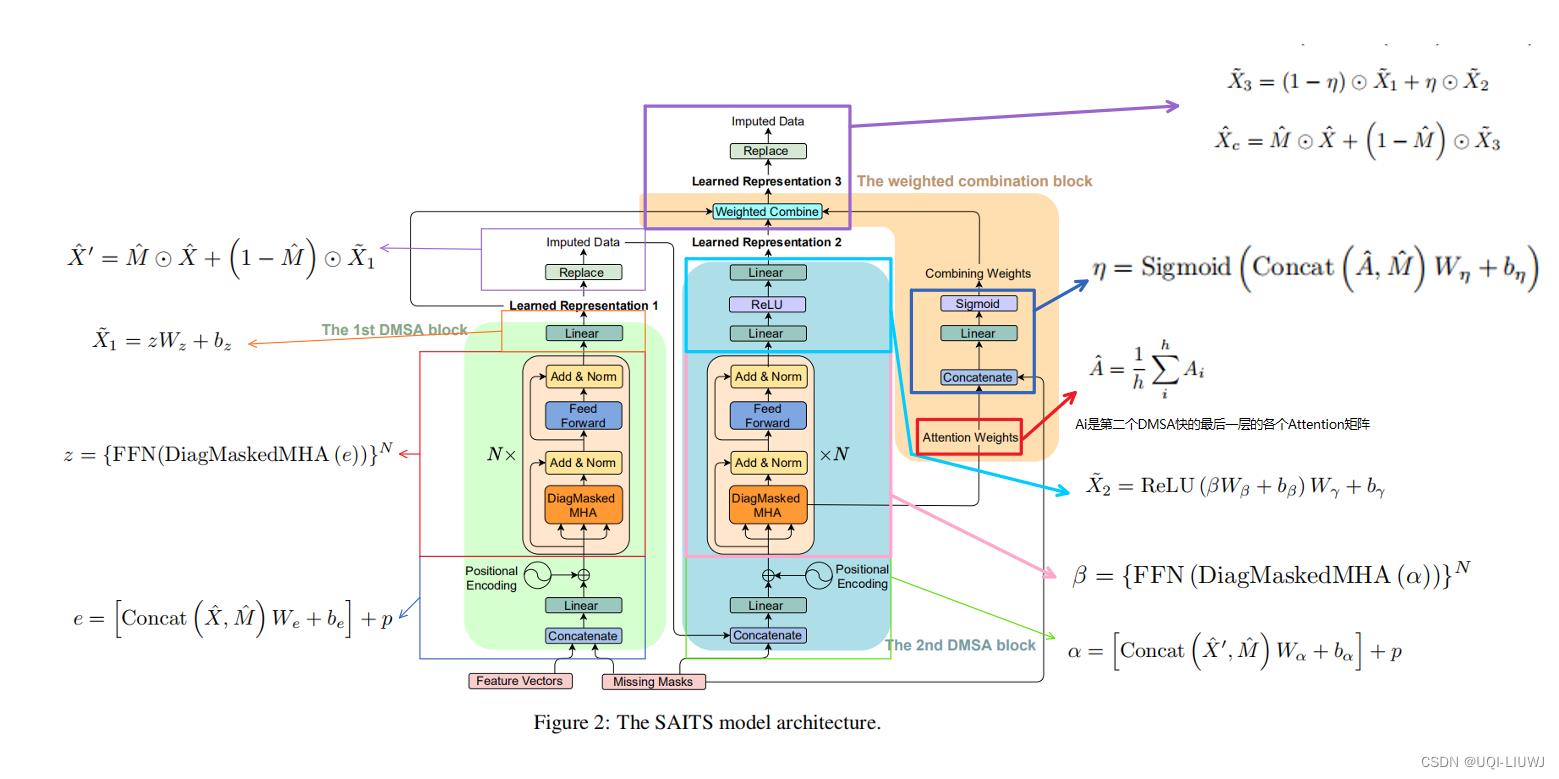
3.4 损失函数
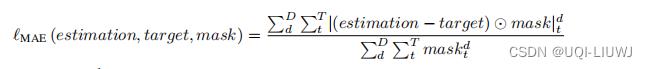
某一个mask下(观测值/人工遮去的点),所有相应的观测值和目标值的MAE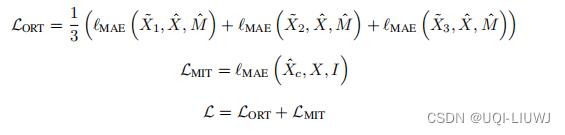
重构观测值的时候,第一个DMSA、第二个DMSA和最后加权了的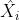 ,都是为了重构X,所以他们都需要和实际值进行比较,所以这里ORT的损失函数是三个MAE的和的平均值。
,都是为了重构X,所以他们都需要和实际值进行比较,所以这里ORT的损失函数是三个MAE的和的平均值。
4 实验部分
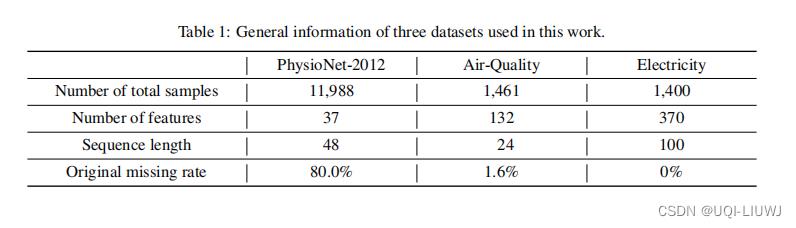
4.1 数据集
4.2 Metric
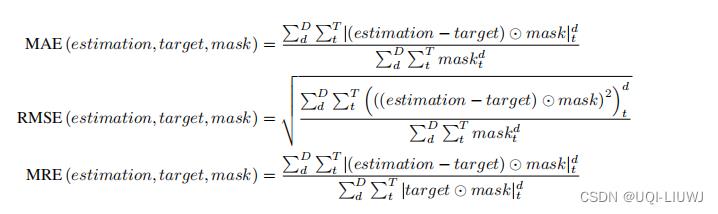
4.3 实验结果
4.3.1 不同数据集的补全结果
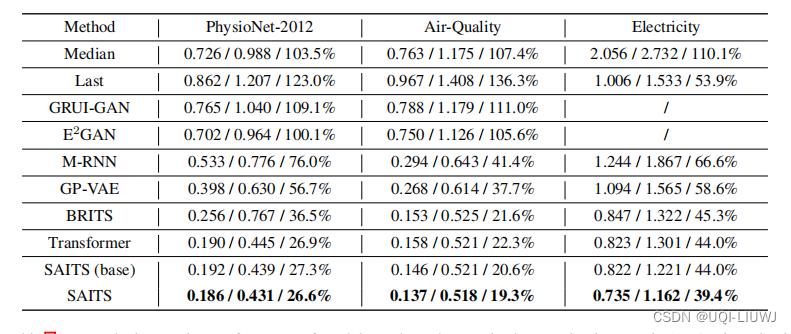
没有数值的几个是因为损失爆炸,跑不起来
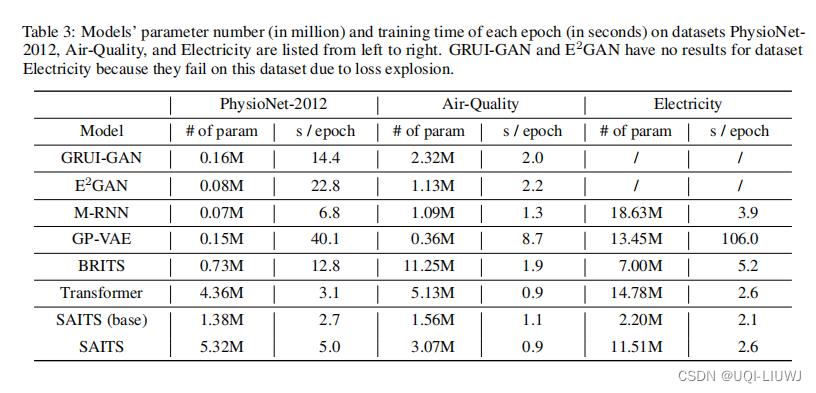
4.3.2 参数量和运行时间
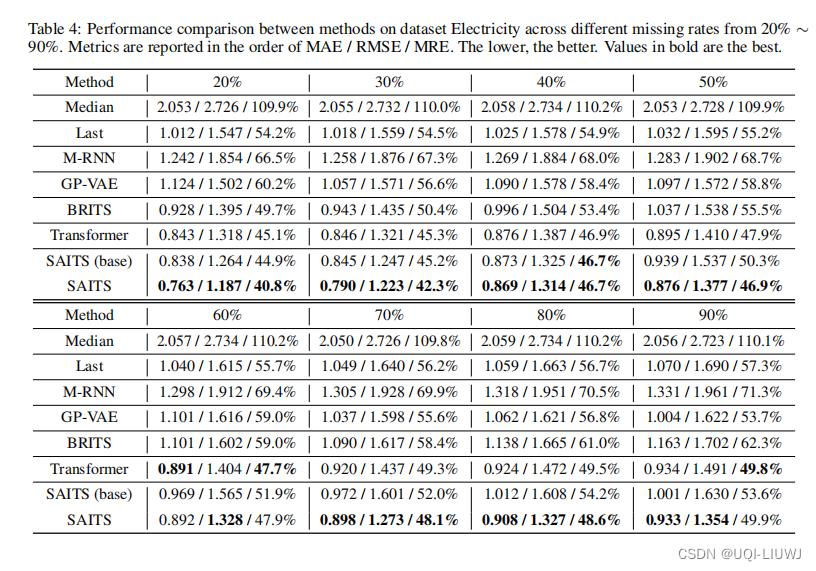
4.3.3 不同缺失率下的补全结果
4.3.4 ablation study

唯一区别是,加不加那个对角线的mask
以上是关于论文笔记:SAITS: SELF-ATTENTION-BASED IMPUTATION FOR TIMESERIES的主要内容,如果未能解决你的问题,请参考以下文章
论文笔记-Deep Learning on Graphs: A Survey(上)
论文笔记之GPT-GNN: Generative Pre-Training of Graph Neural Networks