数据挖掘金山办公2020校招大数据和机器学习算法笔试题
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘金山办公2020校招大数据和机器学习算法笔试题相关的知识,希望对你有一定的参考价值。
【数据挖掘】金山办公2020校招大数据和机器学习算法笔试题
1、 执行如下程序代码后,C的值是( C )
int a = 0, c = 0;
do
–c;
a = a - 1;
while(a > 0);
0
1
-1
死循环
2、写出中序遍历如下二叉树的结果( C)
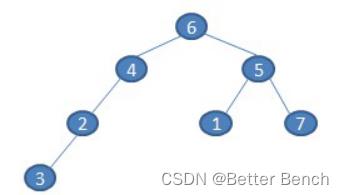
A、6423517
B、6452173
C、3246157
D、3217456
3、设指针变量p指向双向链表中结点A,指针变量s指向被插入的结点X,则在结点A的后面插入结点X的操作序列为( D)。
p->right=s; s->left=p; p->right->left=s; s->right=p->right;
s->left=p;s->right=p->right;p->right=s; p->right->left=s;
p->right=s; p->right->left=s; s->left=p; s->right=p->right;
s->left=p;s->right=p->right;p->right->left=s; p->right=s;
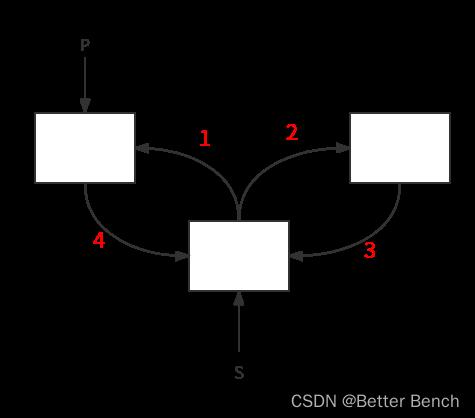
前驱后继,前驱后继
4、在一条线段上任取两点,求能构成三角形的概率是多少:( B )
A、1/8
B、1/4
C、1/3
D、1/2
解析:假设总线长为10,第一段线长x,第二段线长y,则第三段线长10-x-y。
由三角形性质可知:x+y>10-x-y ,即x+y>5 ; x+(10-x-y)>y, 即y<5 ;同理x<5 ;
接下来用图解法,画出方程相应的线就可以求出,x,y可取值的范围的面积为25,所以概率为 25/100=1/4
5、以下正则表达式,能用来提取下面文字中的所有日期的是( D )
“The next meetup on data science will be held on 2017-09-21, previously it happened on 31/03, 2016”
A 、\\d4-\\d2-\\d2
B、(19|20)\\d2-(0[1-9]|1[0-2])-[0-2][1-9]
C、(19|20)\\d2-(0[1-9]|1[0-2])-([0-2][1-9]|3[0-1])
D、都不能
解析:
(1)限定符(Quantifier)
a*:a出现0次或多次
a+:a出现1次或多次
a?:a出现0次或1次
a6: a出现6次
a2,6: a出现2-6次
a2,: a出现两次以上
(2)或运算符(OR Operator)
(a|b):匹配a或者b
(ab)|(cd):匹配ab或者cd
(3)字符类(Character Classes)
[abc]:匹配a或者b或者c
[a-c]:同上
[a-fA-F0-9]:匹配小写+大写英文字符以及数字
[^0-9]:匹配非数字字符
(4)元字符(Meta-characters)
\\d:匹配数字字符
\\D:匹配非数字字符
\\w:匹配单词字符(英文、数字、下划线)
\\W:匹配非单词字符
\\s:匹配空白符(包含换行符、Tab)
\\S:匹配非空白字符
.:匹配任意字符(换行符除外)
\\bword\\b : \\b标注字符的边界(全字匹配)
^:匹配行首
$:匹配行尾
(5)贪婪/懒惰匹配(Greedy/Lazy Match)
<.+>:默认贪婪匹配“任意字符”
<.+?>:懒惰匹配“任意字符”
B、C是能匹配 2017-09-21,不能匹配31/03,2016
6、观察者模式定义了一种()的依赖关系。 A
A、一对多
B、一对一
C、多对多
D、都有可能
7、N-Grams指的是N个单词的组合,下面的句子可以产生的Bi-Gram(N=2)是( C )
“Kingsoft Corporation is a famous software company in the world.”
A、7
B、8
C、9
D、10
解析:n-gram为第n个元素与前面第n-1个元素相关。其中N=2带进去即可,n为2时,第2个元素与第1个元素相关,以此类推可以得到9个。
8、堆可以用作(A)
A、优先队列
B、栈
C、降序数组
D、普通数组
9、列哪个HTTP请求方法的请求体为空(C )
A、POST
B、SEND
C、GET
D、PUT
http请求的方法总共有如下几个:get,post,put,delete,head,connect,trace,options。get方法通常用于向服务器请求资源,如果需要带参数会把参数放于url末尾发送。post则是把数据放于http报文试题的主体里面。put主要是用于文件的传输。delete是通过url对服务器上的某些资源进行删除。connext是通过与服务器进行隧道链接,通过通道将数据进行加密连接。options是查询该请求url可以支持什么请求的方法。trace是让服务器把之前的请求通信在发回给客户端
10、下列伪代码段说明了OOP的哪个特征?( D )
class Student
int marks;
;
class Topper : public Student
int age;
Topper(int age)
this.age=age;
;
A、继承
B、多态
C、继承与多态
D、封装和继承
11、Attention机制属于以下哪种网络结构( D)
A、Seq to Seq
B、Seq to Vector
C、Vector to Seq
D、Encoder-Decoder
12、one-hot和word2vec的相比,以下哪项是正确的(B )
A、one-hot向量稀疏,内存占用比Word2vec小
B、word2vec的向量考虑了词的上下文语义
C、one-hot可以用来判断相似词
D、Word2vec输出的向量维度与词典大小有直接关系
解析:A、D错:one-hot编码法,是按照词典来进行编码的,词向量维度取决于就是词典数量。向量稀疏,内存占用会比Word2vec大,Word2vec可以控制输出维度。
B对:word2vec是基于分布假设,认为上下文环境相同的词语其语义也相似.,主要的方法有两种:CBOW和skip-gram. Word2vec能将one-hot Encoder转化为低维度的连续值,也就是稠密向量,具有相似语义的单词的向量之间距离会比较小,部分词语之间的关系能够用向量的运算表示.
C错:word2vec可以用来判断相似词,用Word2Vec得到词向量后,一般用余弦相似度来比较两个词的相似程度
13、Nave Bayes(朴素贝叶斯)是一种特殊的Bayes分类器,特征变量是X,类别标签是Y,它的一个假定是( B)
A、各类别的先验概率P(Y)是相等的
B、特征变量X的各个维度是类别条件独立随机变量
C、以0为均值,sqr(2)/2为标准差的正态分布
D、P(X|Y)是高斯分布
解析:朴素贝叶斯的条件就是每个变量相互独立
14、在Logistic Regression 中,如果同时加入L1和L2范数,不会产生什么效果(D )
A、可以做特征选择,并在一定程度上防止过拟合
B、能解决维度灾难问题
C、能加快计算速度
D、可以获得更准确的结果
解析:L0 范数计算非零参数个数,无法防止过拟合
L1 范数进行特征选择,使得参数矩阵稀疏,一定程度上防止过拟合
L2 范数可以防止过拟合
15、有一个15×15 的图像,使用一个 3×3 的 filter 进行卷积(步幅为2)之后,得到的图像大小为(A )
A、 8*8
B、9*9
C、10*10
D、11*11
16、下列哪个不属于有监督学习( C)
A、逻辑回归
B、SVM
C、K-means
D、XGBoost
18、Logistic Loss是( )
交叉熵
L
=
−
[
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
)
]
L = -[ylog\\haty +(1-y)log(1-\\haty)]
L=−[ylogy^+(1−y)log(1−y^)]
19、以下哪种模型可以被用来计算文档相似度是( D)
A、练一个word2vec模型学习文档中的上下文关系
B、训练一个词袋模型学习文档中的词共现关系
C、建立文档-词矩阵,用每个文档的cos距离
D、选项所有
解析:七种方法计算文本相似度方法
余弦相似度 余弦(余弦函数),三角函数的一种。 …
简单共有词 通过计算两篇文档共有的词的总字符数除以最长文档字符数来评估他们的相似度。 …
编辑距离 …
SimHash + 汉明距离 …
Jaccard相似性系数 …
欧几里得距离 …
曼哈顿距离
20、甲、乙、丙、丁4人分别掌握英、法、德、日四种语言中的两种,其中有3人会说英语,但没有一种语言是4人都会的,并且知道:
(1)没有人既会日语又会法语;
(2)甲会日语,而乙不会,但他们可以用另一种语言交谈;
(3)丙不会德语,甲和丁交谈时,需要丙为他们做翻译;
(4)乙、丙、丁不会同一种语言。
根据上述条件,以下哪项是四人分别会的两种语言?(A)
A、甲会英语和日语,乙会英语和德语,丙会英语和法语,丁会法语和德语。
B、甲会英语和日语,乙会英语和法语,丙会英语和德语,丁会法语和德语。
C、甲会英语和德语,乙会英语和日语,丙会英语和法语,丁会法语和德语。
D、甲会英语和德语,乙会英语和法语,丙会法语和德语,丁会英语和日语。
解析:根据不会的某种语言进行排除法做。
B和D 、题目说了丙不会德语
C、题目说了,乙不会日语
21、
下列可以用来提升短文本分类模型的准确率的特征是( A B C D )
A、 词频
B、文本的向量表示
C、词性标注
D、语法依赖关系
22、如果神经网络有高的偏差(bias),下列哪些方法可以尝试(A、C )
A、增加隐层神经元数量
B、增加测试(test)数据
C、增加网络层数
D、增加正则项
E、增加训练(training)数据
解析:网络层有较高的偏差(bias),模型拟合效果不佳,模型结构不够复杂,可以加深网络层,增加隐层神经元的个数。
23、下列关于栈的叙述正确的是(A、D)
A、栈是线性结构
B、栈是一种树状结构
C、栈具有先进先出的特征
D、栈有后进先出的特征
24、有关模板方法模式,以下叙述正确的是() A C D
A、允许定义不同的子过程,同时维护基本过程的一致性。
B、将定义和操作相互分离。
C、创建一个抽象类,用抽象方法实现一个过程,这些抽象方法必须在子类中实现。
D、实现抽象方法的子类的步骤可以独立变化,并且这些步骤可以采用Strategy 模式来实现。
解析:模板方法是将不变算法部分封装到父类中,将可变需要扩展部分封装到子类中实现,而不是将算法与操作相分离。
25、Which of the following statements are correct with regards to Topic Modeling( )
牛客官方正确答案: C D,我觉得官方答案不正确,我的答案: A B D
A、 It is a supervised learning technique
B、LDA (Linear Discriminant Analysis) can be used to perform topic modeling
C、Selection of number of topics in a model depends on the size of data
D、Number of topic terms are not directly proportional to size of the data
解析:关于主题模型正确的是:
它是一种有监督学习;
LDA可用于主题建模;
模型中主题数量的选择取决于数据的大小;
主题词的数量与数据的大小不成正比。
解释:LDA是一种无监督的主题模型。
模型的主题数量的选择不取决于数量的大小,取决于数据中主题类别;
主题词的数量类似于关键词,与数据大小无关。
26、装饰器模式和代理模式有哪些相同点和不同点,并分别举例说明?
修饰器模式:动态地给一个对象添加一些额外的职责,同时又不改变其结构,就增加功能来说装饰模式比生成子类更为灵活。
代理模模式:为其他对象提供一种代理以控制对这个对象的访问。
(1)相同点
两种从设计模式分类来看都属于结构型,因为两者均使用了组合关系。其次两者都能实现对对象方法进行增强处理的效果。
(2)不同点
代理模式,注重对对象某一功能的流程把控和辅助。它可以控制对象做某些事,重心是为了借用对象的功能完成某一流程,而非对象功能如何。
装饰模式,注重对对象功能的扩展,它不关心外界如何调用,只注重对对象功能的加强,装饰后还是对象本身。
举个例子说明两者不同之处,代理和装饰其实从另一个角度更容易去理解两个模式的区别:代理更多的是强调对对象的访问控制,比如说,访问A对象的查询功能时,访问B对象的更新功能时,访问C对象的删除功能时,都需要判断对象是否登陆,那么我需要将判断用户是否登陆的功能抽提出来,并对A对象、B对象和C对象进行代理,使访问它们时都需要去判断用户是否登陆,简单地说就是将某个控制访问权限应用到多个对象上;而装饰器更多的强调给对象加强功能,比如说要给只会唱歌的A对象添加跳舞功能,添加说唱功能等,简单地说就是将多个功能附加在一个对象上。
27、设计一个系统用来预测输入的中文电影评论表达的情感状态是正面,负面还是中立的。要求给出特征处理的方法,使用哪种预测模型,为什么使用该模型,如何评价系统的好坏等。
(1)数据预处理,包括去除特殊字符,大小写统一
(2)利用分词工具进行分词,并采用word2vec编码为词向量
(3)利用二分类模型,TextCNN,Fasttext,等文本分类模型
(4)评价指标采用混淆矩阵、准确率、召回率、ROC、AUC等
28、在计算广告中,经常存在样本非常稀疏且极度不均衡的情况,请说下你对该类问题的理解和解决思路。
(1)扩大数据集
当遇到类别不均衡问题时,首先应该想到,是否可能再增加数据(一定要有小类样本数据),更多的数据往往战胜更好的算法。因为机器学习是使用现有的数据多整个数据的分布进行估计,因此更多的数据往往能够得到更多的分布信息,以及更好分布估计。即使再增加小类样本数据时,又增加了大类样本数据,也可以使用放弃一部分大类数据(即对大类数据进行欠采样)来解决。
(2)数据集重采样
可以使用一些策略该减轻数据的不平衡程度。该策略便是采样(sampling),主要有两种采样方法来降低数据的不平衡性。
对小类的数据样本进行采样来增加小类的数据样本个数,即过采样(over-sampling ,采样的个数大于该类样本的个数)。
对大类的数据样本进行采样来减少该类数据样本的个数,即欠采样(under-sampling,采样的次数少于该类样本的个素)。
考虑对大类下的样本(超过1万、十万甚至更多)进行欠采样,即删除部分样本;
考虑对小类下的样本(不足1为甚至更少)进行过采样,即添加部分样本的副本;
考虑尝试随机采样与非随机采样两种采样方法;
考虑对各类别尝试不同的采样比例,比一定是1:1,有时候1:1反而不好,因为与现实情况相差甚远;
考虑同时使用过采样与欠采样。
(3)人工产生数据样本
一种简单的人工样本数据产生的方法便是,对该类下的所有样本每个属性特征的取值空间中随机选取一个组成新的样本,即属性值随机采样。你可以使用基于经验对属性值进行随机采样而构造新的人工样本,或者使用类似朴素贝叶斯方法假设各属性之间互相独立进行采样,这样便可得到更多的数据,但是无法保证属性之前的线性关系(如果本身是存在的)。
有一个系统的构造人工数据样本的方法SMOTE(Synthetic Minority Over-sampling Technique)。SMOTE是一种过采样算法,它构造新的小类样本而不是产生小类中已有的样本的副本,即该算法构造的数据是新样本,原数据集中不存在的。该基于距离度量选择小类别下两个或者更多的相似样本,然后选择其中一个样本,并随机选择一定数量的邻居样本对选择的那个样本的一个属性增加噪声,每次处理一个属性。这样就构造了更多的新生数据。具体可以参见原始论文。 这里有SMOTE算法的多个不同语言的实现版本:
Python: UnbalancedDataset模块提供了SMOTE算法的多种不同实现版本,以及多种重采样算法。
R: DMwR package。
Weka: SMOTE supervised filter。
(4)基于异常检测的方式
我们可以从不同于分类的角度去解决数据不均衡性问题,我们可以把那些小类的样本作为异常点(outliers),因此该问题便转化为异常点检测(anomaly detection)与变化趋势检测问题(change detection)。
异常点检测即是对那些罕见事件进行识别。如通过机器的部件的振动识别机器故障,又如通过系统调用序列识别恶意程序。这些事件相对于正常情况是很少见的。
变化趋势检测类似于异常点检测,不同在于其通过检测不寻常的变化趋势来识别。如通过观察用户模式或银行交易来检测用户行为的不寻常改变。
将小类样本作为异常点这种思维的转变,可以帮助考虑新的方法去分离或分类样本。这两种方法从不同的角度去思考,让你尝试新的方法去解决问题。从算法角度出发,通常的方法包括了:
(1)尝试不同的分类算法
强烈建议不要对待每一个分类都使用自己喜欢而熟悉的分类算法。应该使用不同的算法对其进行比较,因为不同的算法使用于不同的任务与数据。具体可以参见“Why you should be Spot-Checking Algorithms on your Machine Learning Problems”。
决策树往往在类别不均衡数据上表现不错。它使用基于类变量的划分规则去创建分类树,因此可以强制地将不同类别的样本分开。目前流行的决策树算法有:C4.5、C5.0、CART和Random Forest等。
(2)对小类错分进行加权惩罚
对分类器的小类样本数据增加权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集,译者注),从而使得分类器将重点集中在小类样本身上。一个具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。如penalized-SVM和penalized-LDA算法。
对小样本进行过采样(例如含L倍的重复数据),其实在计算小样本错分cost functions时会累加L倍的惩罚分数。
(3)从重构分类器的角度出发
仔细对你的问题进行分析与挖掘,是否可以将你的问题划分成多个更小的问题,而这些小问题更容易解决。你可以从这篇文章In classification, how do you handle an unbalanced training set?中得到灵感。例如:
将你的大类压缩成小类;
使用One Class分类器(将小类作为异常点);
使用集成方式,训练多个分类器,然后联合这些分类器进行分类;
将二分类问题改成多分类问题
29、给定一个长度为n的数组a[0],a[1]…a[n-1]和一个数字x,在数组中查找两个数a和b(可以是相同的值,但是不可以是相同位置的数字),使得它们的和与输入的数字差的绝对值最小。
比如:a = [8,3,6,1] x=13
那么答案为:6和8
输入描述:
第一行两个数字 n,x(2<=n<=1000,1<=x<=108)
第二行n个用空格隔开的数字a[0],a[1]...a[n-1]
输出描述:
两个数字a,b,用空格隔开。比较小的数字在左边,即输出要保证a<=b
输入例子1:
4 13
8 3 6 1
输出例子1:
6 8
n,x = list(map(int, input().split(' ')))
A = [int(x) for x in input().split(' ')]
num = len(A)
a = 0
b = 1
for i in range(num - 1):
for j in range(i+1, num):
if abs(A[i] + A[j] - x) < abs(A[a] + A[b] - x):
a = i
b = j
if A[a] < A[b]:
print(A[a], A[b])
else:
print(A[b], A[a])
以上是关于数据挖掘金山办公2020校招大数据和机器学习算法笔试题的主要内容,如果未能解决你的问题,请参考以下文章