Postgresql 学习记录,模式,分区表,触发器,事务,窗口函数,视图,建表,约束等
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Postgresql 学习记录,模式,分区表,触发器,事务,窗口函数,视图,建表,约束等相关的知识,希望对你有一定的参考价值。
Postgresql 学习记录,模式,分区表,触发器,事务,窗口函数,视图,建表,约束等
PostgreSQL使用一种客户端/服务器的模型。一次PostgreSQL会话由下列相关的进程(程序)组成:
- 一个服务器进程,它管理数据库文件、接受来自客户端应用与数据库的联接并且代表客户端在数据库上执行操作。 该数据库服务器程序叫做postgres。
- 那些需要执行数据库操作的用户的客户端(前端)应用。 客户端应用可能本身就是多种多样的:可以是一个面向文本的工具, 也可以是一个图形界面的应用,或者是一个通过访问数据库来显示网页的网页服务器,或者是一个特制的数据库管理工具。 一些客户端应用是和 PostgreSQL发布一起提供的,但绝大部分是用户开发的。
定义
PostgreSQL是一种关系型数据库管理系统 (RDBMS)。这意味着它是一种用于管理那些以关系 形式存储数据的系统。关系实际上是表的数学称呼。还有层次数据库和面向对象的数据库;
每个表都是一个命名的行集合。一个给定表的每一行由同一组的命名列组成,而且每一列都有一个特定的数据类型。虽然列在每行里的顺序是固定的, 但一定要记住 SQL 并不对行在表中的顺序做任何保证(但你可以为了显示的目的对它们进行显式地排序)。
表被分组成数据库,一个由单个PostgreSQL服务器实例管理的数据库集合组成一个数据库集簇。
PostgreSQL支持标准的SQL类型int、smallint、real、double precision、char(N)、varchar(N)、date、time、timestamp和interval,还支持其他的通用功能的类型和丰富的几何类型。PostgreSQL中可以定制任意数量的用户定义数据类型。因而类型名并不是语法关键字,除了SQL标准要求支持的特例外。
varchar(80)指定了一个可以存储最长 80 个字符的任意字符串的数据类型。int是普通的整数类型。real是一种用于存储单精度浮点数的类型。date类型应该可以自解释(没错,类型为date的列名字也是date。 这么做可能比较方便或者容易让人混淆 — 你自己选择)。
text,一种用于变长字符串的本地PostgreSQL类型
类型point就是一种PostgreSQL特有数据类型的例子。
创建表、插入更新删除,事务,窗口函数
窗口函数的神奇作用http://www.postgres.cn/docs/14/tutorial-window.html
视图、继承表,分区表
- 分区表按照range、list、hash分区。
创建父表,分区表,索引。
管理相对独立,优点: 数据维护成本低;分区表可以将不同的表放置在不同的物理空间上;直接从分区表查效率高;
删除数据时可以直接删掉不用的分区表,或者使子表从主表分离;主表创建索引时子表将自动拥有索引(也可配置子表不拥有);继承也能实现类似的功能,但触发器稍显复杂和需要一直更新。详见5.11.3
-- 移除旧数据最简单的选择是删除掉不再需要的分区:可以非常快地删除数百万行记录,因为它不需要逐个删除每个记录。不过注意需要在父表上拿到ACCESS EXCLUSIVE锁。
DROP TABLE measurement_y2006m02;
-- 另一种通常更好的选项是把分区从分区表中移除,但是保留它作为一个独立的表:
ALTER TABLE measurement DETACH PARTITION measurement_y2006m02;
-- 父表创建索引子表自动也有索引,或者父表创建索引子表不拥有;
CREATE INDEX measurement_usls_idx ON measurement (unitsales); --子表将自动拥有索引
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales); --子表将不拥有索引
--父表也将能使用子表的索引
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales);
CREATE INDEX measurement_usls_200602_idx
ON measurement_y2006m02 (unitsales);
ALTER INDEX measurement_usls_idx
ATTACH PARTITION measurement_usls_200602_idx;
缺点:通常通过主表定位到分区表在查询可能比直接从一个大表查要慢;主键有可能重复;
- 继承对于一些(城市表,首都表)可以简化逻辑;
- 视图可以保证每次输出的结果不会随着主表而发生变化;
- 没有办法创建跨越所有分区的排除约束,只可能单个约束每个叶子分区。
- 分区表上的惟一约束(也就是主键)必须包括所有分区键列。存在此限制是因为PostgreSQL只能每个分区中分别强制实施唯一性。
- BEFORE ROW 触发器无法更改哪个分区是新行的最终目标。
- 不允许在同一个分区树中混杂临时关系和持久关系。因此,如果分区表是持久的,则其分区也必须是持久的,反之亦然。在使用临时关系时,分区数的所有成员都必须来自于同一个会话。

-- 创建一个范围分区表:
CREATE TABLE measurement (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
-- 创建在分区键中具有多个列的范围分区表:
CREATE TABLE measurement_year_month (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (EXTRACT(YEAR FROM logdate), EXTRACT(MONTH FROM logdate));
-- 创建列表分区表:
CREATE TABLE cities (
city_id bigserial not null,
name text not null,
population bigint
) PARTITION BY LIST (left(lower(name), 1));
-- 建立哈希分区表:
CREATE TABLE orders (
order_id bigint not null,
cust_id bigint not null,
status text
) PARTITION BY HASH (order_id);
-- 创建范围分区表的分区:
CREATE TABLE measurement_y2016m07
PARTITION OF measurement (
unitsales DEFAULT 0
) FOR VALUES FROM ('2016-07-01') TO ('2016-08-01');
--使用分区键中的多个列,创建范围分区表的几个分区:
CREATE TABLE measurement_ym_older
PARTITION OF measurement_year_month
FOR VALUES FROM (MINVALUE, MINVALUE) TO (2016, 11);
CREATE TABLE measurement_ym_y2016m11
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 11) TO (2016, 12);
CREATE TABLE measurement_ym_y2016m12
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 12) TO (2017, 01);
CREATE TABLE measurement_ym_y2017m01
PARTITION OF measurement_year_month
FOR VALUES FROM (2017, 01) TO (2017, 02);
-- 创建列表分区表的分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b');
-- 创建本身是分区的列表分区表的分区,然后向其添加分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b') PARTITION BY RANGE (population);
CREATE TABLE cities_ab_10000_to_100000
PARTITION OF cities_ab FOR VALUES FROM (10000) TO (100000);
-- 建立哈希分区表的分区:
CREATE TABLE orders_p1 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE orders_p2 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE orders_p3 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE orders_p4 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
-- 建立默认分区:
CREATE TABLE cities_partdef
PARTITION OF cities DEFAULT;
-- 移除旧数据最简单的选择是删除掉不再需要的分区:可以非常快地删除数百万行记录,因为它不需要逐个删除每个记录。不过注意需要在父表上拿到ACCESS EXCLUSIVE锁。
DROP TABLE measurement_y2006m02;
-- 另一种通常更好的选项是把分区从分区表中移除,但是保留它作为一个独立的表:
ALTER TABLE measurement DETACH PARTITION measurement_y2006m02;
-- 父表创建索引子表自动也有索引,或者父表创建索引子表不拥有;
CREATE INDEX measurement_usls_idx ON measurement (unitsales); --子表将自动拥有索引
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales); --子表将不拥有索引
--父表也将能使用子表的索引
CREATE INDEX measurement_usls_idx ON ONLY measurement (unitsales);
CREATE INDEX measurement_usls_200602_idx
ON measurement_y2006m02 (unitsales);
ALTER INDEX measurement_usls_idx
ATTACH PARTITION measurement_usls_200602_idx;
-- 创建一个范围分区表:
CREATE TABLE measurement (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
-- 创建在分区键中具有多个列的范围分区表:
CREATE TABLE measurement_year_month (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (EXTRACT(YEAR FROM logdate), EXTRACT(MONTH FROM logdate));
-- 创建列表分区表:
CREATE TABLE cities (
city_id bigserial not null,
name text not null,
population bigint
) PARTITION BY LIST (left(lower(name), 1));
-- 建立哈希分区表:
CREATE TABLE orders (
order_id bigint not null,
cust_id bigint not null,
status text
) PARTITION BY HASH (order_id);
-- 创建范围分区表的分区:
CREATE TABLE measurement_y2016m07
PARTITION OF measurement (
unitsales DEFAULT 0
) FOR VALUES FROM ('2016-07-01') TO ('2016-08-01');
-- 使用分区键中的多个列-- 创建范围分区表的几个分区:
CREATE TABLE measurement_ym_older
PARTITION OF measurement_year_month
FOR VALUES FROM (MINVALUE, MINVALUE) TO (2016, 11);
CREATE TABLE measurement_ym_y2016m11
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 11) TO (2016, 12);
CREATE TABLE measurement_ym_y2016m12
PARTITION OF measurement_year_month
FOR VALUES FROM (2016, 12) TO (2017, 01);
CREATE TABLE measurement_ym_y2017m01
PARTITION OF measurement_year_month
FOR VALUES FROM (2017, 01) TO (2017, 02);
-- 创建列表分区表的分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b');
-- 创建本身是分区的列表分区表的分区,然后向其添加分区:
CREATE TABLE cities_ab
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('a', 'b') PARTITION BY RANGE (population);
CREATE TABLE cities_ab_10000_to_100000
PARTITION OF cities_ab FOR VALUES FROM (10000) TO (100000);
-- 建立哈希分区表的分区:
CREATE TABLE orders_p1 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 0);
CREATE TABLE orders_p2 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 1);
CREATE TABLE orders_p3 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 2);
CREATE TABLE orders_p4 PARTITION OF orders
FOR VALUES WITH (MODULUS 4, REMAINDER 3);
-- 建立默认分区:
CREATE TABLE cities_partdef
PARTITION OF cities DEFAULT;
基本语法
为了在一个字符串中包括一个单引号,可以写两个相连的单引号,例如’Dianne’‘s horse’。
一个转义字符串常量可以通过在开单引号前面写一个字母E(大写或小写形式)来指定
添加/修改/删除列/增加删除约束/重命名列/表
创建/删除模式及表
-
定义外部统计
-
创建序列
-
CREATE TABLE AS创建一个表,并且用 由一个SELECT命令计算出来的数据填充 该表。该表的列具有和SELECT的输出列 相关的名称和数据类型(不过可以通过给出一个显式的新列名列表来覆 盖这些列名)。
CREATE TABLE AS和创建一个视图有些 相似,但是实际上非常不同:它会创建一个新表并且只计算该查询一次 用来初始填充新表。这个新表将不会跟踪该查询源表的后续变化。相反, 一个视图只要被查询,它的定义SELECT 语句就会被重新计算。
Postgresql COPY/VIEW/PARTITION/OVER/ CASE WHEN
触发器
源码
SELECT '"bar": "baz", "balance": 7.77, "active": false'::json;
-- 创建数据库
createdb mydb;
-- 删除数据库
dropdb mydb;
SELECT version(),current_date;
-- 创建表
CREATE TABLE weather (
city varchar(80),
temp_lo int, -- 最低温度
temp_hi int, -- 最高温度
prcp real, -- 湿度
date date
);
CREATE TABLE cities (
name varchar(80),
location point
);
-- 删除表
DROP TABLE weather;
--插入表数据
INSERT INTO weather VALUES ('San Francisco', 46, 50, 0.25, '1994-11-27');
INSERT INTO cities VALUES ('San Francisco', '(-194.0, 53.0)');
INSERT INTO weather (city, temp_lo, temp_hi, prcp, date)
VALUES ('San Francisco', 43, 57, 0.0, '1994-11-29');
INSERT INTO weather (date, city, temp_hi, temp_lo)
VALUES ('1994-11-29', 'Hayward', 54, 37);
--杀手锏COPY命令
SELECT * FROM ops.t_application_properties
-- POSTGRESQL 9.0前支持,不支持
-- COPY (SELECT * FROM ops.t_application_properties WHERE key LIKE 'service') TO 'C:\\\\Users\\\\Administrator\\\\Desktop\\\\t_application_services.copy';
SELECT DISTINCT city FROM weather order by city;
SELECT * FROM weather;
SELECT * FROM weather, cities WHERE city = name;
-- 按城市找出最低温度中的最高温度
SELECT city FROM weather WHERE temp_lo = (SELECT max(temp_lo) FROM weather);
SELECT city, max(temp_lo) FROM weather GROUP BY city;
SELECT city, max(temp_lo) FROM weather GROUP BY city HAVING max(temp_lo) < 40;
-- 只关心以S开头的城市,最低温度的最高温度
SELECT city, max(temp_lo) FROM weather city LIKE 'S%' GROUP BY city HAVING max(temp_lo) < 40;
UPDATE weather SET temp_hi = temp_hi - 2, temp_lo = temp_lo - 2 WHERE date > '1994-11-28';
DELETE FROM weather WHERE city = 'Hayward';
--视图
CREATE VIEW myview AS
SELECT city, temp_lo, temp_hi, prcp, date, location
FROM weather, cities
WHERE city = name;
SELECT * FROM myview;
--外键辅助进行一些数据引用完整性,cities表必须现有city,才能插入到weather表中
CREATE TABLE cities (
city varchar(80) primary key,
location point
);
CREATE TABLE weather (
city varchar(80) references cities(city),
temp_lo int,
temp_hi int,
prcp real,
date date
);
-- 事务 ACID 在PostgreSQL中,开启一个事务需要将SQL命令用BEGIN和COMMIT命令包围起来。银行事务看起来会是这样:
-- PostgreSQL实际上将每一个SQL语句都作为一个事务来执行。如果我们没有发出BEGIN命令,则每个独立的语句都会被加上一个隐式的BEGIN以及(如果成功)COMMIT来包围它。一组被BEGIN和COMMIT包围的语句也被称为一个事务块。
-- ROLLBACK TO是唯一的途径来重新控制一个由于错误被系统置为中断状态的事务块,而不是完全回滚它并重新启动。
BEGIN;
UPDATE accounts SET balance = balance - 100.00
WHERE name = 'Alice';
SAVEPOINT my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Bob';
-- oops ... forget that and use Wally's account
ROLLBACK TO my_savepoint;
UPDATE accounts SET balance = balance + 100.00
WHERE name = 'Wally';
COMMIT;
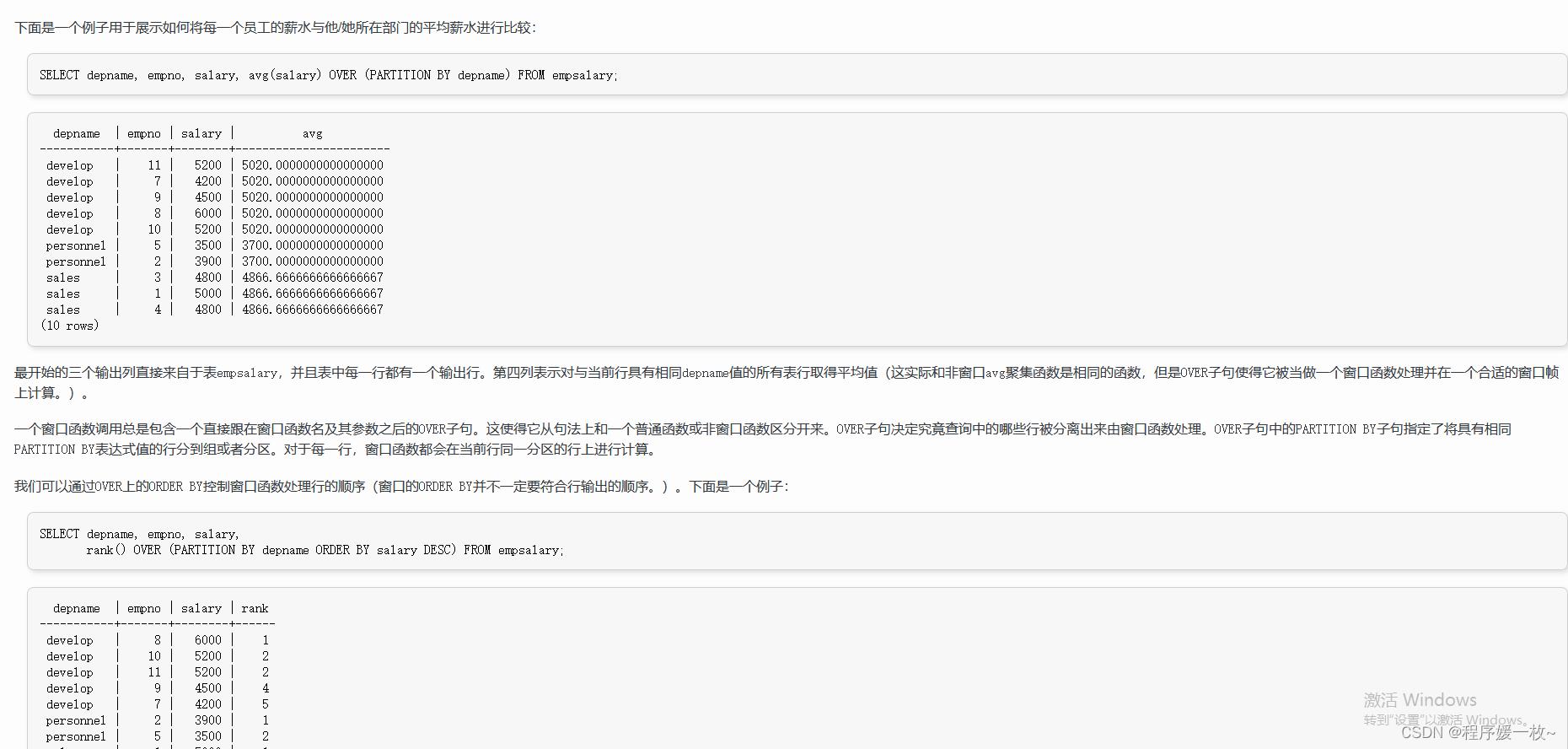
-- 展示如何将每一个员工的薪水与他/她所在部门的平均薪水进行比较:
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
-- 部门内员工薪水倒序排列
SELECT depname, empno, salary, rank() OVER (PARTITION BY depname ORDER BY salary DESC) FROM empsalary;
-- 为了在一个字符串中包括一个单引号,可以写两个相连的单引号,例如'Dianne''s horse'。
select 'Dianne''s horse',E'Dianne\\'s horse',$$Dianne's horse$$
-- 一个转义字符串常量可以通过在开单引号前面写一个字母E(大写或小写形式)来指定
select E'\\b' as 退格,E'\\f' as 换页,E'\\n' 换行,E'\\r' 回车,E'\\t' 制表符,E'\\o, \\oo, \\ooo (o = 0–7)' 八进制字节值
select 2^3,sqrt(2);
-- 聚合函数 根据某个字段排序后在聚合
SELECT array_agg(city ORDER BY prcp DESC) FROM weather;
SELECT string_agg(city, ',' ORDER BY city) FROM weather;
-- 直接聚合,并且以''字符串连接
select string_agg('''' || "city" || '''',',') from weather;
SELECT
count(*) AS unfiltered,
count(*) FILTER (WHERE i < 5) AS filtered
FROM generate_series(1,10) AS s(i);
-- generate_series生成序列
SELECT * FROM generate_series(1,10);
-- CROSS JOIN,INNER JOIN,LEFT JOIN,RIGHT JOIN,FULL OUTER JOIN的区别
CREATE TABLE foo (fooid int, foosubid int, fooname text);
CREATE FUNCTION getfoo(int) RETURNS SETOF foo AS $$
SELECT * FROM foo WHERE fooid = $1;
$$ LANGUAGE SQL;
SELECT * FROM getfoo(1) AS t1;
SELECT * FROM foo
WHERE foosubid IN (
SELECT foosubid
FROM getfoo(foo.fooid) z
WHERE z.fooid = foo.fooid
);
CREATE VIEW vw_getfoo AS SELECT * FROM getfoo(1);
SELECT * FROM vw_getfoo;
-- json_to_recordset & generate_series
SELECT *
FROM ROWS FROM
(
json_to_recordset('["a":40,"b":"foo","a":"100","b":"bar"]')
AS (a INTEGER, b TEXT),
generate_series(1, 3)
) AS x (p, q, s)
ORDER BY p;
-- 计算每种商品的销售额
SELECT product_id, p.name, (sum(s.units) * p.price) AS sales
FROM products p LEFT JOIN sales s USING (product_id)
GROUP BY product_id, p.name, p.price;
-- 计算近4周的产品id,名称及利润
SELECT product_id, p.name, (sum(s.units) * (p.price - p.cost)) AS profit
FROM products p LEFT JOIN sales s USING (product_id)
WHERE s.date > CURRENT_DATE - INTERVAL '4 weeks'
GROUP BY product_id, p.name, p.price, p.cost
HAVING sum(p.price * s.units) > 5000;
-- 聚合分组
SELECT brand, size, sum(sales) FROM items_sold GROUP BY GROUPING SETS ((brand), (size), ());
SELECT oid FROM pg_proc WHERE proname LIKE 'bytea%'
-- 数组
CREATE TABLE arr(f1 int[], f2 int[]);
INSERT INTO arr VALUES (ARRAY[[1,2],[3,4]], ARRAY[[5,6],[7,8]]);
SELECT ARRAY[f1, f2, '9,10,11,12'::int[]] FROM arr;
SELECT ARRAY[]::integer[],ARRAY[1,2,3+4],ARRAY[1,2,22.7]::integer[],ARRAY[ARRAY[1,2],ARRAY[3,4]],ARRAY(SELECT oid FROM pg_proc WHERE proname LIKE 'bytea%');
SELECT ARRAY(SELECT ARRAY[i, i*2] FROM generate_series(1,5) AS a(i));
--复杂的case when计算
SELECT CASE WHEN min(employees) > 0
THEN avg(expenses / employees)
END
CASE COALESCE(sum(employees),0)
WHEN 0 THEN 0.0
ELSE SUM(salary)/sum(employees)
END
-- 计算比率
(CASE COALESCE(sum(employees),0)
WHEN 0 THEN '0.00%'
ELSE concat(round(SUM(salary)*100.0/sum(employees)),2),'%')
END) excelRate
(CASE WHEN time > 1440 THEN time/1440||'天'||time%1440/60||'小时'||time%60||'分钟'
WHEN time > 60 THEN time/60||'小时'||time%60||'分钟'
ELSE time%60||'分钟'
END) weekAvg
FROM departments;
-- 创建表
drop table if exists my_first_table;
CREATE TABLE if not exists my_first_table (
first_column text,
second_column integer
);
-- 自增序列 主键 唯一 非空约束 外键
CREATE TABLE products (
product_no integer DEFAULT nextval('products_product_no_seq') PRIMARY KEY,
name text NOT NULL,
price numeric DEFAULT 9.99,
number CHECK (number > 0),
discounted_price numeric CONSTRAINT positive_price CHECK (discounted_price > 0),
CONSTRAINT valid_discount CHECK (price > discounted_price), --打折价格低于正常价格
UNIQUE (product_no)
);
-- 组合约束
CREATE TABLE example (
a integer,
b integer,
c integer,
UNIQUE (a, c)
);
CREATE TABLE products (
product_no integer PRIMARY KEY,
name text,
price numeric
);
CREATE TABLE orders (
order_id integer PRIMARY KEY,
shipping_address text
);
CREATE TABLE order_items (
product_no integer REFERENCES products ON DELETE RESTRICT, --不允许删除被引用的行
order_id integer REFERENCES orders ON DELETE CASCADE,--删除时级联删除 还有其他两种选项:SET NULL和SET DEFAULT。这些将导致在被引用行被删除后,引用行中的引用列被置为空值或它们的默认值。
quantity integer,
PRIMARY KEY (product_no, order_id)
);
-- 序列发生器取值
CREATE TABLE tablename (
colname SERIAL
);
-- 等价于以下语句:
CREATE SEQUENCE tablename_colname_seq AS integer;
CREATE TABLE tablename (
colname integer NOT NULL DEFAULT nextval('tablename_colname_seq')
);
ALTER SEQUENCE tablename_colname_seq OWNED BY tablename.colname;
--创建序列
CREATE SEQUENCE serial START 101;
-- 从这个序列中选取下一个数字:
SELECT nextval('serial');
SELECT x,
round(x::numeric) AS num_round,
round(x::double precision) AS dbl_round
FROM generate_series(-3.5, 3.5, 1) as x;
-- 生成时间序列
select * from generate_series(to_timestamp(1658937600)::DATE,to_timestamp(1659537600)::DATE,'1 day')
-- 生成char时间序列
select to_char(generate_series(to_timestamp(1658937600)::DATE,to_timestamp(1659537600)::DATE,'1 day'),'yyyy-mm-dd')
-- 创建一个范围分区表:
CREATE TABLE measurement (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
-- 创建在分区键中具有多个列的范围分区表:
CREATE TABLE measurement_year_month (
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (EXTRACT(YEAR FROM logdate), EXTRACT(MONTH FROM logdate));
-- 创建列表分区表:
CREATE TABLE cities (
city_id bigserial not null,
name text not null,
population bigint
) PARTITION BY LIST (left(lower(name), 1));
-- 建立哈希分区表:
CREATE TABLE orders (
order_id bigint not null,
cust_id bigint not null,
status text
) PARTITION BY HASH (order_id);
-- 创建范围分区表的分区:
CREATE TABLE measurement_y2016m07
PARTITION OF measurement (
unitsales DEFAULT 0
) FOR 以上是关于Postgresql 学习记录,模式,分区表,触发器,事务,窗口函数,视图,建表,约束等的主要内容,如果未能解决你的问题,请参考以下文章