数据挖掘顺丰公司数据挖掘笔试题
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘顺丰公司数据挖掘笔试题相关的知识,希望对你有一定的参考价值。
【数据挖掘】顺丰公司数据挖掘笔试题
1、二叉排序树的链表节点定义如下:
typedef struct BiTnode
int key_value;
struct BiTnode *L,*R;/节点的左、右树指针/
请补充完整查找键值key的函数。(D)
BSTree lookup_key(BSTree root,int key)
if() return NULL;
else
if(key == root->key_value)
return root;
else if(key > root->key_value)
return (1);
else
return (2);
A、
(1)lookup_key(root->R,key)
(2)lookup_key(NULL,key)
B、
(1)lookup_key(root->R,root.key_value)
(2)lookup_key(root->L,root.key_value)
C、
(1)lookup_key(root->L,key)
(2)lookup_key(root->R,key)
D、
(1)lookup_key(root->R,key)
(2)lookup_key(root->L,key)
2、对序列(12,18,22,38,39,49,79,89)进行排序,最不适合的算法是(B)
A、 冒泡排序
B、 快速排序
C、 归并排序
D、 插入排序
| 排序方法 | 平均时间 | 最好时间 | 最坏时间 |
|---|---|---|---|
| 桶排序(不稳定) | O(n) | O(n) | O(n) |
| 基数排序(稳定) | O(n) | O(n) | O(n) |
| 归并排序(稳定) | O(nlogn) | O(nlogn) | O(nlogn) |
| 快速排序(不稳定) | O(nlogn) | O(nlogn) | O(n^2) |
| 堆排序(不稳定) | O(nlogn) | O(nlogn) | O(nlogn) |
| 希尔排序(不稳定) | O(n^1.25) | ||
| 冒泡排序(稳定) | O(n^2) | O(n) | O(n^2) |
| 选择排序(不稳定) | O(n^2) | O(n^2) | O(n^2) |
| 直接插入排序(稳定) | O(n^2) | O(n) | O(n^2) |
快排不适合对基本有序的数据集合进行排序
3、调用函数时,入参及返回地址使用了(D)
A、 队列
B、 多维数组
C、 顺序表
D、 栈
在函数调用过程中形成嵌套时,则应使最后被调用的函数最先返回,后进先出,栈。
4、设有递归算法如下,最终打印结果是(A)
#include<stdio.h>
int foo(int a ,int b)
if (b == 0) return 0;
if (b % 2 == 0) return foo(a+a,b/2);
return foo(a+a,b/2)+a;
int main()
printf(“%d”, foo(1,3));
return 0;
A 、 3
B、 4
C、 5
D、 6
f(1,3) = f(2,1)+1 = f(4,0)+2+1 =0+2+1=3
5、请指出堆排序、选择排序、冒泡排序、快速排序的平均时间复杂度(A)
A、
n
l
o
g
n
、
n
2
、
n
2
、
n
l
o
g
n
nlogn、n^2 、n^2、nlogn
nlogn、n2、n2、nlogn
B、
n
2
、
n
2
、
n
2
、
n
l
o
g
n
n^2、n^2、n^2、nlogn
n2、n2、n2、nlogn
C、
n
l
o
g
n
、
n
l
o
g
n
、
n
2
、
n
l
o
g
n
nlogn、nlogn、n^2、nlogn
nlogn、nlogn、n2、nlogn
D、
n
l
o
g
n
、
n
2
、
n
2
、
n
2
nlogn、n^2、n^2、n^2
nlogn、n2、n2、n2
| 排序方法 | 平均时间 | 最好时间 | 最坏时间 |
|---|---|---|---|
| 桶排序(不稳定) | O(n) | O(n) | O(n) |
| 基数排序(稳定) | O(n) | O(n) | O(n) |
| 归并排序(稳定) | O(nlogn) | O(nlogn) | O(nlogn) |
| 快速排序(不稳定) | O(nlogn) | O(nlogn) | O(n^2) |
| 堆排序(不稳定) | O(nlogn) | O(nlogn) | O(nlogn) |
| 希尔排序(不稳定) | O(n^1.25) | ||
| 冒泡排序(稳定) | O(n^2) | O(n) | O(n^2) |
| 选择排序(不稳定) | O(n^2) | O(n^2) | O(n^2) |
| 直接插入排序(稳定) | O(n^2) | O(n) | O(n^2) |
6、What is Static Method in Java(A、B、C)
It is a method which belongs to the class and not to the object(instance)
A static method can access only static data. It can not access non-static data (instance variables)
A static method can call only other static methods and can not call a non-static method from it.
A static method can not be accessed directly by the class name and doesn’t need any object
解析:A:静态方法是一个属于类而不属于对象(实例)的方法。(√)
静态方法可以在没有创建对象实例的情况下调用,其是可以通过类名引用。
B:静态方法只能访问静态数据。无法访问非静态数据(实例变量)。(√)
它这边的意思是不能直接访问非静态数据(实例变量),因为非静态数据是属于对象属性的,其只有在对象存在的时候才能引用。
C:静态方法只能调用其他静态方法,不能从中调用非静态方法。(√)
这里也是不能直接调用非静态方法,因为非静态方法是属于某个对象的,不先实例化对象,通过对象引用,那么将无法判断具体调用哪个对象(实例)的非静态方法。
D:静态方法不能通过类名直接访问,也不需要任何对象。(×) 静态方法可以直接用类名访问。
类名.静态方法名() 这种方式是可以的,所以静态方法可以直接通过类名进行访问。
7、
public class CharToString
public static void main(String[] args)
char myChar = ‘g’;
String myStr = Character.toString(myChar);
System.out.println("String is: "+myStr);
myStr = String.valueOf(myChar);
System.out.println("String is: "+myStr);
此代码片段输出正确的值是(A)
A、
String is: g
String is: g
B、
String is: 103
String is: g
C、
String is: g
String is: 103
D、
String is: 103
String is: 103
8、一个空栈,如果有顺序输入序列:a1,a2,a3…an(个数大于3),而且输出第一个元素为 a(n-1), 那么所有元素都出栈后,(D)
A、 输出的最后元素一定为 an
B、 输出的最后元素一定为 a1
C、 不能确定元素 a1 ~ (an-2) 的输出顺序
D、 a(n-2) 一定比 a(n-3) 先出
9、利用栈完成数制转换,将十进制的169转换为八进制,出栈序列为(A)
A、 251
B、 521
C、 215
D、 152
169/8 = 21 余1
21/8 = 2 余5
2/8 = 0 余 2
栈是先进后出,那么出来的数则为251
10、主机IP为200.15.13.13/23,其子网掩码是(D)
A、255.255.249.0
B、255.255.2410
C、 255.255.253.0
D、 255.255.254.0
总共32位,掩码长度为23,也就是11111111 11111111 11111110 00000000,转为十进制,就是255.255.254.0
11、总部给某分公司分配的网络地址是172.16.2.0/24,该分公司有三个部门,每个部门计算机不多于30台,在网络配置时,进行子网划分,可以使用的子网掩码是(B、C)
A、255.255.255.128
B、255.255.255.192
C、255.255.255.224
D、255.255.255.240
解析:172.16.2.0/24为B类地址,所以子网掩码肯定是255.255开头,因为该地址有24为的网络号,也就是剩下的子网掩码是:
11111111.00000000,又因为有三个部门,留下两位进行表示,且这两位最大为11,所以有11111111.11000000(255.192),又因为30的二进制至少用5位来表示,4位(1111)的最大值才15,5位的最大值31,所以只留下4位时为11111111.11110000,(255.240),所以为大于等于192小于240.
12、以下叙述中,不正确的有(B、D )
A、 单元测试对源程序中每一个程序单元进行测试,检查各个模块是否正确实现规定的功能,从而发现模块在编码中或算法中的错误。该阶段涉及编码和详细设计文档。
B、 集成测试是基于软件需求说明书的黑盒测试,是对已经集成好的软件系统进行彻底的测试,以验证软件系统的正确性和性能等满足其规约所指定的要求,检查软件的行为和输出是否正确
C、 确认测试主要是检查已实现的软件是否满足需求规格说明书中确定了的各种需求。
D、 系统测试的主要目的是检查软件单位之间的接口是否正确,主要是针对程序内部结构进行测试,特别是对程序之间的接口进行测试。
解析:
B:
系统测试是基于软件需求说明书的黑盒测试,是对已经集成好的软件系统进行彻底的测试,以验证软件系统的正确性和性能等满足其规约所指定的要求,检查软件的行为和输出是否正确
D:
集成测试的主要目的是检查软件单位之间的接口是否正确,主要是针对程序内部结构进行测试,特别是对程序之间的接口进行测试。
BD的概念刚好反了,所以错误
13、关于链表,正确的是(A、C)
A、 无需事先估计空间
B、 支持随机访问
C、 增删不必挪动元素
D、 所需空间与线性表长度成正比,并且地址连续
E、 插入一个元素所需挪动元素的平均个数为n/2
解析:链表不支持随机访问。 链表的地址不一定连续, 增删不必挪动元素
14、以下关于链表和数组说法正确的是(A,C)
A、 new出来的数组也在堆中
B、 数组插入或删除元素的时间复杂度O(n),链表的时间复杂度O(1)
C、 数组利用下标定位,时间复杂度为O(1),链表定位元素时间复杂度O(n)
D、对于add和remove,ArrayList要比LinkedList快
解析:链表与数组插入和删除时间复杂度都是O (n)
数组:查询速度快, 增删元素慢
链表: 查询速度慢, 增删元素快
15、甲乙丙3个进程对某类资源的需求分别是7个、8个、3个。且目前已分别得到了3个、3个和2个资源,若系统还至少能提供( )个资源,则系统是安全的。
A、1
B、4
C、2
D、8
解析:先给丙进程一个资源,让它成功执行,释放三个资源;然后给甲进程,此时一共3+3=6个资源,还需要一个才能使甲进程启动,故1+1;最后将甲释放的给乙进程,可以满足,所以共2个。
16、32位处理器是指处理器的(B)是32位的
A、 控制总线
B、 数据总线
C、 地址总线
D、 所有的总线
17、以下关于TCP和UDP说法正确的是(A,C)
TCP数据传输慢,UDP数据传输快
TCP通过滑动窗口机制进行拥塞控制
UDP缓冲区小于报文长度,则会丢失报文
DNS协议用于域名解析,默认23端口
解析:TCP使用滑动窗口是为了进行流量控制,不是拥塞控制,是为了让发送端不要发送得太快。DNS的默认端口号是53
18、某打车公司将驾驶里程(drivedistanced)超过5000里的司机信息转移到一张称为seniordrivers 的表中,他们的详细情况被记录在表drivers 中,正确的sql为(D )
A、 insert into seniordrivers
drivedistanced>=5000 from drivers where
B、 insert seniordrivers (drivedistanced) values from drivers where drivedistanced>=5000
C、 insert into seniordrivers
(drivedistanced)values>=5000 from drivers where
D、 select * into seniordrivers from drivers where drivedistanced >=5000
解析:语法是select into:copy information from one table into another
19、允许信号在两个方向上传输,但某一时刻只允许信号在一个信道上单向传输的通信是(B )
A、 单工通信
B、 半双工通信
C、 全双工通信
D、 时工通信
20、LR分析法属于()
A、 自顶向下分析法
B、 LALR分析法
C、 SLR分析法
D、 自底向上分析法
解析:编译原理的知识,LR分析法也是一种“移进—归约”的自底向上语法分析方法,其本质是规范归约
21、下面哪种UML图描述的是一个实体基于事件反应的动态行为,显示了该实体如何根据当前所处的状态对不同的事件做出反应( )
A、 活动图
B、 状态图
C、 配置图
D、 构件图
描述状态的就是状态图
22、 在关系模式R(U,F)中,X,Y,Z是U中属性,则多值依赖的传递律是(D)
A、 如果X→→Y,Y→→Z,则X→→Z
B、 如果X→→Y,Y→→Z,则X→→YZ
C、 如果X→→Y,Y→→Z,则X→→Y Z
D、 如果X→→Y,Y→→Z,则X→→Z-Y
考的是数据库技术中函数依赖和多值依赖的推理规则:
A1.(函数依赖的自反律):如果Y∈X∈U,则X→Y。
A2.(函数依赖的增广律):如果X→Y,且Z∈U,则XZ→YZ。
A3.(函数依赖的传递律):如果X→Y,Y→Z,则X→Z。
A4.(多值依赖的补规则):如果X→→Y,则X→→(U-X-Y)。
A5.(多值依赖的增广律):如果X→→Y,且V∈W,则WX→→VY。
A6.(多值依赖的传递律):如果X→→Y,Y→→Z,则X→→(Z-Y)。
A7.(从函数依赖导出多值依赖):如果X→Y,则X→→Y。
A8.(从多值依赖导出函数依赖):如果X→→Y,Z∈Y,Y∩W=∮,W→Z,则X→Z。
A9.(多值依赖的合并律):如果X→→Y,X→→Z,则X→→YZ。
A10.(多值依赖的伪传递律):如果X→→Y,WY→→Z,则WX→→(Z-WY)。
A11.(多值依赖与函数依赖混合传递律):如果X→→Y,XY→Z,则X→(Z-Y)。
A12.(多值依赖的分解律):如果X→→Y,X→→Z,则X→→(Y∩X),X→→(Y-Z),X→→(Z-Y)。
23、下面关于JAVA的垃圾回收机制,正确的是(B )
A、当调用“System.gc()”来强制回收时,系统会立即回收垃圾
B、垃圾回收不能确定具体的回收时间
C、程序可明确地标识某个局部变量的引用不再被使用
D、程序可以显式地立即释放对象占有的内存
解析:java提供了一个系统级的线程,即垃圾回收器线程。用来对每一个分配出去的内存空间进行跟踪。当JVM空闲时,自动回收每块可能被回收的内存,GC是完全自动的,不能被强制执行。程序员最多只能用System.gc()来建议执行垃圾回收器回收内存,但是具体的回收时间,是不可知的。当对象的引用变量被赋值为null,可能被当成垃圾。
24、关于SpringMVC,以下说法错误的是?(D)
A、 SpringMVC的核心入口是DispatcherServlet
B、 @RequestMapping注解既可以用在类上也可以用在方法上
C、 @PathVariable作用是取出url中的模板变量作为参数
D、 controller默认是单例,通过@Scope(“prototype”)注解改为多例,成员变量共享
解析:成员变量是由对象所私有的。不是静态变量 静态变量可以共享,成员变量不行
25、在hive中下列哪些命令可以实现去重()
A、 distinct
B、 group by
C、 row_number
D、】 having
解析:row_number是排完序后再取topN,相同于去重
25、表关联时,以下哪种说法是正确的(D)
A、左连接时,结果集数据的行数一定等于左表
B、左连接时,结果集数据的行数一定等于右表
C、右连接时,结果集数据的行数一定等于右表
D、左连接时,结果集的行数可能大于左表的行数
解析:左连接时,如果 left join on的条件在右表中有所重复,那么最终记录数目会大于原表数量
26、有一张学生成绩表sc(sno 学号,class 课程,score 成绩),示例如下:

请问哪个语句可以查询出每个学生的英语、数学的成绩(行转列,一个学生输出一行记录,比如输出[1, 89, 90])?(D)
A、select sno,class,score from sc where class in('english','math')
B、select sno,
if(class='english',score,0),
if(class='math',score,0)
from sc
where class in('english','math')
C、select sno,
case when class='english' then score else 0 end ,
case when class='math' then score else 0 end
from sc
where class in('english','math')
D、select sno,
sum(if(class='english',score,0)) as english,
sum( if(class='math',score,0) ) as math
from sc
where class in('english','math')
group by sno
错误答案C:没达到行转列的目的
select sno,
case when class='english' then score else 0 end ,
case when class='math' then score else 0 end
from sc
where class in('english','math')
结果:一个学生最终会出现两条记录(英语和数学),每条记录都是满足当前class条件的那门课程成绩正常,其余课程成绩为0
张三 80 0
张三 0 79
王五 60 0
王五 0 88
修改为:
select sno,
sum(case when class='english' then score else 0 end ) as english,
sum(case when class='math' then score else 0 end) as math
from sc
where class in('english','math')
group by sno;
正确答案D:
select sno,
sum(if(class='english',score,0)) as english,
sum( if(class='math',score,0) ) as math
from sc
where class in('english','math')
group by sno
如果科目为English为真,English成绩+score,否则+0!!!
结果:
张三 80 79
王五 60 88
27、关于K-means聚类算法说法正确的是(A、B、C)
A、对大数据集有较高的效率并且具有可伸缩性。
B、是一种无监督学习方法。
C、k值无法自动获取,初始聚类中心随机选择。
D、初始聚类中心的选择对聚类结果影响不大。
28、列算法常用于聚类的问题是(A)
A、k-means
B 、逻辑回归模型
C、决策树模型
D、随机森林模型
29、网点755WM有两个单元区域A和B,单元区域A有5名员工,单元区域B有8名员工,历史上单元区域A和B的投诉率分别是0.1%,0.15%,现在755WM有一个投诉,问投诉发生在单元区域A的概率是多少(A )
A、0.29
B、0.39
C、0.13
D、0.5
解析:记事件A为发生在区域A,事件B为发生在区域B,则P(A)=5/13,P(B)=8/13,事件C为网点755WM被投诉。历史上单元区域A和B的投诉率分别是0.1%、0.15%,因此P(C|A)=0.1%,P(C|B)=0.15%,再根据全概率公式,有P©=P(C|A)P(A)+P(C|B)P(B),因此P©=5/130.1%+8/130.15%。再根据贝叶斯公式有
P
(
A
∣
C
)
=
P
(
C
∣
A
)
P
(
A
)
P
(
C
)
=
5
/
13
×
0.1
%
5
/
13
×
0.1
%
+
8
/
13
×
0.15
%
≈
0.29
P(A|C) =\\fracP(C|A)P(A)P(C) = \\frac5/13×0.1\\%5/13×0.1\\%+8/13×0.15\\% \\approx 0.29
P(A∣C)=P(C)P(C∣A)P(A)=5/13×0.1%+8/13×0.15%5/13×0.1%≈0.29
,因此选A。
30、在 Hive 中一个查询语句执行后显示的结果为:
20180812 50;20180813 32;20180814 NULL,则最有可能的查询语句是(B)
A、SELECT inc_day,count(task_no) FROM 任务表 WHERE inc_day<=20180814
B、SELECT inc_day,count(task_no) FROM 任务表 WHERE inc_day<=20180814 GROUP BY inc_day
C、SELECT inc_day,count(task_no) FROM 任务表 WHERE inc_day<=20180814 ORDER BY inc_day
D、SELECT inc_day,count(task_no) FROM 任务表 HAVING inc_day<=20180814 GROUP BY inc_day
解析:select中出现item1、聚合函数count处理的item2,就要搭配group by item1
2 问答题
1、在oracle数据库中,有一张表waybill_constype记录了客户使用快递的信息。
(consign_day int comment “揽收日期” ,waybill_no varchar(30) “运单号“,class varchar(10) “托寄物类型”,userid varchar(20) comment “会员号”),请统计各个会员在4月份揽收的文件、娱乐、食品的件量以及主要托寄物类型(托寄物类型件量最多的就是主要托寄物类型)
waybill_constype中waybill_no是运单号,class是托寄物类型()
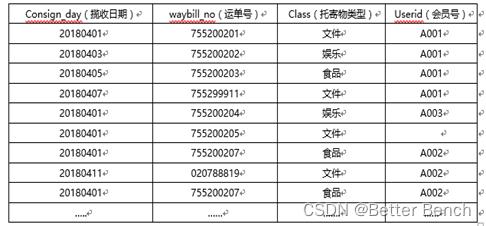
select userid,sum(case when class='文件' then 1 else 0 end) as filessum,sum(case when class=' 娱乐' then 1 else 0 end) as eSum,
sum(case when class=' 食品' then 1 else 0 end) as foodSum,
max(filessum,sSum,foodSum) as '主要物托寄类型' from waybill_constype where month(consign_day)=4 group by userid
2、在mysql中,有任务中转表task_arrive_transfer(task_no varchar(20) comment “任务号”,arrive_time datetime comment “到达中转站时间”,transfer_fee int “中转费用” ),任务操作表task_operate(task_no varchar(20) “任务号”,start_time datetime “任务开始时间”,end_time datetime “任务结束时间”, emp_no varchar(20) comment “工号”)。历史原因,任务中转表中进入了一些脏数据,若任务的到达中转场时间在每个任务开始前或者任务结束后,则为脏数据;一般来说,任务的执行流程是开始----到达中转站(到达次数>=0)----结束;请计算出在任务开始执行时间是8月份的任务中,每个任务的中转总费用。

select a.task_no,
SUM(a.transfer_fee) as money_sum
from task_arrive_transfer a,task_operate b
where a.task_no=b.task_no
and SUBSTRING(start_time,7,1)=8
and a.arrive_time between b.start_time and c.end_time
group by a.task_no
以上是关于数据挖掘顺丰公司数据挖掘笔试题的主要内容,如果未能解决你的问题,请参考以下文章