PyTorch笔记 - Attention Is All You Need
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch笔记 - Attention Is All You Need相关的知识,希望对你有一定的参考价值。
Transformer难点细节实现,6点:Word Embedding、Position Embedding、Encoder Self-Attention Mask、Intra-Attention Mask、Decoder Self-Attention Mask、Multi-Head Self-Attention
Encoder Self-Attention Mask
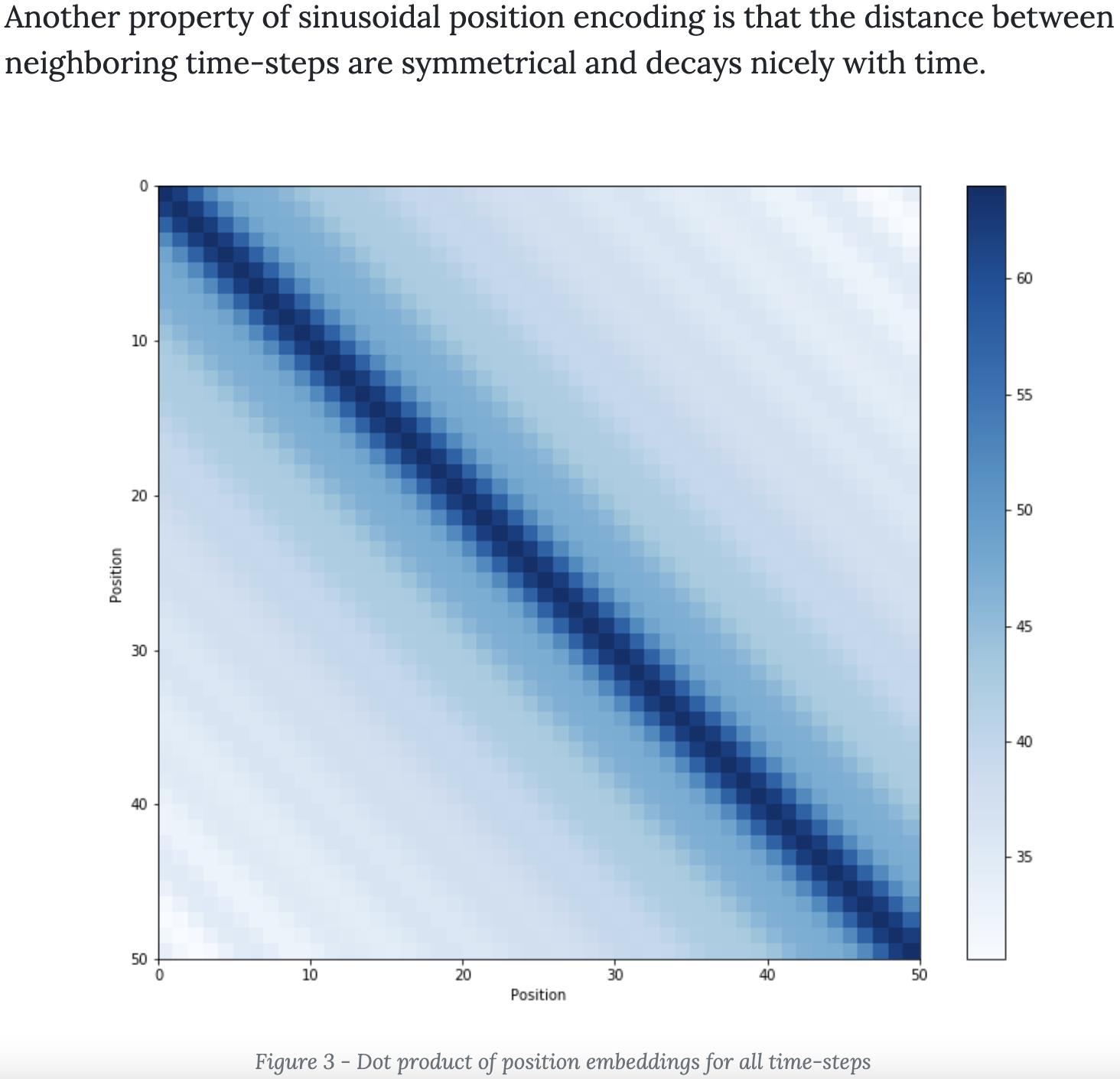
参考:Transformer Architecture: The Positional Encoding



Intra-Attention Mask
# 2022.8.2
# Step 5,构造Intra-Attention Mask,用于Decoder
# Q @ K^T shape [batch_size, tgt_seq_len, src_seq_len]
valid_encoder_pos = torch.stack([F.pad(torch.ones(L), (0, max(src_len) - L)) for L in src_len])
valid_encoder_pos = torch.unsqueeze(valid_encoder_pos, dim=2)
print(f'[Info] valid_encoder_pos.shape: valid_encoder_pos.shape')
print(f'[Info] valid_encoder_pos: valid_encoder_pos') # 有效位置是1,无效位置是0,根据batch的最大长度
valid_decoder_pos = torch.stack([F.pad(torch.ones(L), (0, max(tgt_len) - L)) for L in tgt_len])
valid_decoder_pos = torch.unsqueeze(valid_decoder_pos, dim=2)
print(f'[Info] valid_encoder_pos.shape: valid_decoder_pos.shape')
print(f'[Info] valid_encoder_pos: valid_decoder_pos') # 有效位置是1,无效位置是0,根据batch的最大长度
# 源序列和目标序列的相关性,相关是1,不相关是0,bmm就是batch的矩阵相乘
# decoder * encoder^T,Decoder是Q,Encoder是K、V
valid_cross_pos_matrix = torch.bmm(valid_decoder_pos, valid_encoder_pos.transpose(1, 2))
print(f'[Info] valid_cross_pos_matrix.shape: valid_cross_pos_matrix.shape')
print(f'[Info] valid_cross_pos_matrix: valid_cross_pos_matrix')
invalid_cross_pos_matrx = 1 - valid_cross_pos_matrix
mask_cross_attention = invalid_cross_pos_matrx.to(torch.bool)
print(f"mask_cross_attention: \\nmask_cross_attention")
Decoder是Q,Encoder是K、V
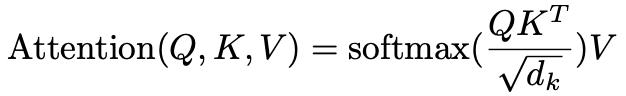
Decoder Self-Attention Mask
# Step 6:构造Decoder Self-Attention Mask
# tri代表三角形,l是low,u是up,上三角和下三角
# Transformer用在流式,都会使用因果的列表
# pad:左、右、上、下
valid_decoder_tri_matrix = [F.pad(torch.tril(torch.ones((L, L))), (0, max(tgt_len)-L, 0, max(tgt_len)-L)) for L in tgt_len]
valid_decoder_tri_matrix = torch.stack(valid_decoder_tri_matrix, dim=0)
print(f"[Info] valid_decoder_tri_matrix: \\nvalid_decoder_tri_matrix")
print(f"[Info] valid_decoder_tri_matrix.shape: \\nvalid_decoder_tri_matrix.shape")
invalid_decoder_tri_matrix = 1 - valid_decoder_tri_matrix
invalid_decoder_tri_matrix = invalid_decoder_tri_matrix.to(torch.bool)
print(f"[Info] invalid_decoder_tri_matrix: \\ninvalid_decoder_tri_matrix")
# 测试
score = torch.randn(batch_size, max(tgt_len), max(tgt_len))
masked_score = score.masked_fill(invalid_decoder_tri_matrix, -1e9)
prob = F.softmax(masked_score, -1)
print(f"tgt_len: tgt_len")
print(f"prob: \\nprob")
Multi-Head Self-Attention
scaled self-attention:
# Step7 构建scaled self-attention
def scaled_dot_product_attention(Q, K, V, attn_mask):
# shape of Q, K, V: (batch_size*num_head, seq_len, model_dim/num_head)
score = torch.bmm(Q, K.transpose(-2, -1)) / torch.sqrt(model_dim)
masked_score = score.masked_fill(attn_mask, -1e9)
prob = F.softmax(masked_score, -1)
context = torch.bmm(prob, V)
return context
Transformer源码:torch.nn.modules.transformer.py
forward输入:
tgt_mask:Decoder Self-Attention Maskmemory_mask:Intra-Attention Mask
核心逻辑:F.multi_head_attention_forward
以上是关于PyTorch笔记 - Attention Is All You Need的主要内容,如果未能解决你的问题,请参考以下文章