手把手教你如何自制目标检测框架(从理论到实现)
Posted Huterox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教你如何自制目标检测框架(从理论到实现)相关的知识,希望对你有一定的参考价值。
文章目录
前言
好久没有冒泡了,是时候来波大的了,也是由于特殊需求,不得不重启关于目标检测的一些内容。既然如此,那么刚好把以前要做的yolo目标检测相关的代码进行复现,并且好好把这个目标检测说清楚一点儿。
此外本文基于Pytorch进行编写,有空后期tensorflow也可以试试。
在阅读这篇博文之前,如果读者真的是还没有接触过这个目标检测的话,我建议可以先看看这几篇文章再来:
在代码部分还参考了原先这篇博文的设计:
嘿~全流程带你基于Pytorch手撸图片分类“框架“–HuClassify
那么本文两个目标:
一. 理论
- 搞清楚什么是目标检测
- 目标检测的重难点
- 相关目标检测算法思想
- 如何设计一个目标检测算法
二. 编码
- voc数据集的细节
- 目标检测网络
- 目标分类网络
- 相关算法
其中的理论部分像我说不会太深入只是快速入门,编码部分的话倒是有很多相关算法的实现。那么编码的话在目标检测部分的网络,我们也是直接使用yolo的网络,当然这里还是会做改动的。这篇博文的更多的一个目的其实还是说搭建一个简单的目标检测平台,这样感兴趣的朋友可以自己DIY,对我本人的话也是有DIY的需求。
那么废话不多说,马上发车了!
目标检测
要说到目标检测的话,那么我们就不得不先说到图片分类了。
因为图片分类在我们的目标检测当中是非常重要的但是二者的区别也是存在的,不过他们之间却有很多相似的地方。
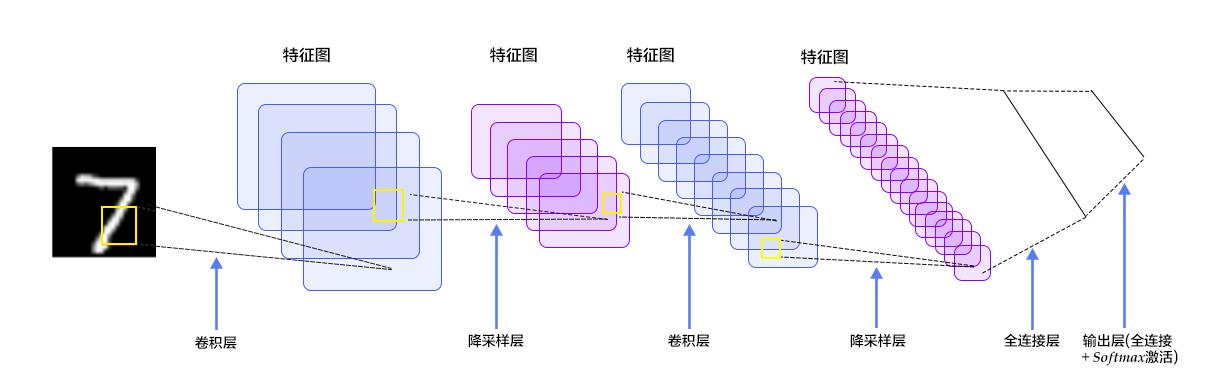
图片分类
图片分类是一个非常经典的问题,给定一张图片然后对这个图片进行分类,它的任务非常简单,并且设计一个这样的网络也非常简单。
你只需要使用一定量的卷积,最后和一定量的全连接网络输出一组大小和类别的最后一个维度一样的tensor就行了,然后使用交叉熵作为你的损失函数。
比如最简单的分类网络:LeNet
class LeNet(nn.Module):
def __init__(self,classes):
super().__init__()
self.feature = Sequential(
nn.Conv2d(3,6,kernel_size=5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.Conv2d(6,16,5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,stride=2)
)
self.classifiar = nn.Sequential(
nn.Linear(16*5*5,120), # B
nn.ReLU(),
nn.Linear(120,84),
nn.ReLU(),
nn.Linear(84,classes)
)
def forward(self,x):
x = self.feature(x)
x = x.view(x.size()[0],-1)
x = self.classifiar(x)
return x
def initialize_weights(self):
#参数初始化,随便给点权重,这样的话会加快一点速度(训练)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight.data, 0, 0.1)
m.bias.data.zero_()
我们只需要输入一张图片就阔以得到这张图片的类别。
但是这还是远远不够的。
目标检测
目标检测则是在图片分类的基础上,我们还需要知道我们对应的一个物体的位置,比如下面这张图:

我们知道这是一只猫,但是在图片场景当中并不是只有一只猫,猫只是图片当中的一个很明显的特征,如果做图片分类的话,你说这个是猫可以,但是我说这是个草貌似也可以。所以现在的任务是我不仅仅要知道这个图片有猫,我还要知道这个猫在图片的位置。

单目标检测
现在我们假设,我们的图片只有一个物体,就如上面的图片一样。那么如果我们需要想办法让神经网络得到这样一个框的,当然在此基础上,我们还需要得到对应的概率,也就是,如果图片只有一个目标的话,我们只需要在原来的基础上想办法多生成一组对应的框的坐标就可以了。也就是说,我们以上面的LeNet网络为例子。我们可以这样干。
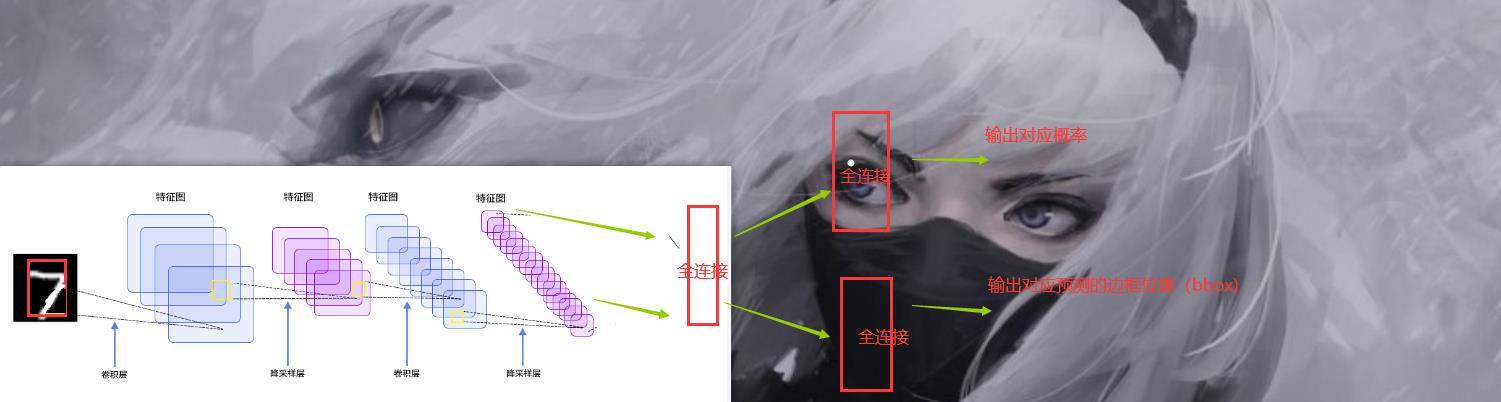
我们只要把原来的那个直接输出概率的那一个全连接层拆掉,然后再来几个全连接层之后分别预测就完了。
至于损失函数,这也好办,一个是交叉熵得到Loss1 还有一个是求方差,求对应的框的点和标注的框的误差就完了得到Loss2 之后Loss=Loss1+Loss2
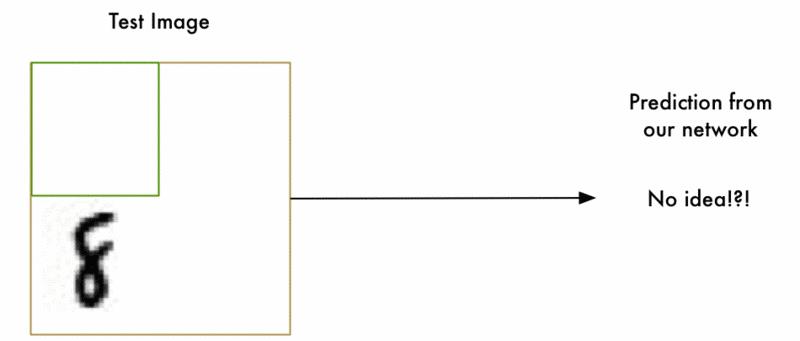
多目标检测
然而理想是很丰满的,但是现实很残酷。现在的图片当中往往都是有多个目标的,而且哪怕是同一个目标,在一张图片当中也可能有多个,那问题不就尴尬了,比如下面的图片:

所以我们需要解决这个问题。
问题分析
首先我们来想想,我们现在面临的问题,首先对于一张图片,对送进神经网络的图片来说(假设数据集不是我们 自己搞的)我们是不知道当前这个图片它是有几个目标的,所以如果是按照咱们先前那个对LeNet的改动的话,我们是压根就不知道要生成几个框,做几个概率的预测的。假设我们知道了,或者说我们一股脑直接生成一堆框,那么我们需要如何筛选这些有用的框出来?并且我们怎么区别这些框对应的类别是啥?最后我们的损失函数又要怎么设计?
那么如果我们能够找到一种方式能够搞定上面的问题,那么多目标检测应该就能够实现了,换句话说能够通用的目标检测算法就ok了。
滑动窗口
前面分析了我们如果想要实现那个多目标检测,我们需要解决的问题。那么第一个问题,如何生成框。回到一开始的方式,我们是直接输入了一张图片,然后,对这张图片生成一个框,然后做预测等操作,那么既然如此,那么我就直接这样,我把一张图片直接分成一个个区域,相当于截图一样,一个一个区域截图,然后分别送进神经网络。然后你懂的,我们套用刚刚提出的方法。
也就是下面这样
我可以生成不同的滑动窗口,然后疯狂搞。
理论上只要电脑不冒烟,我就可以一直搞。只要效率显然…
所以还需要优化一下。
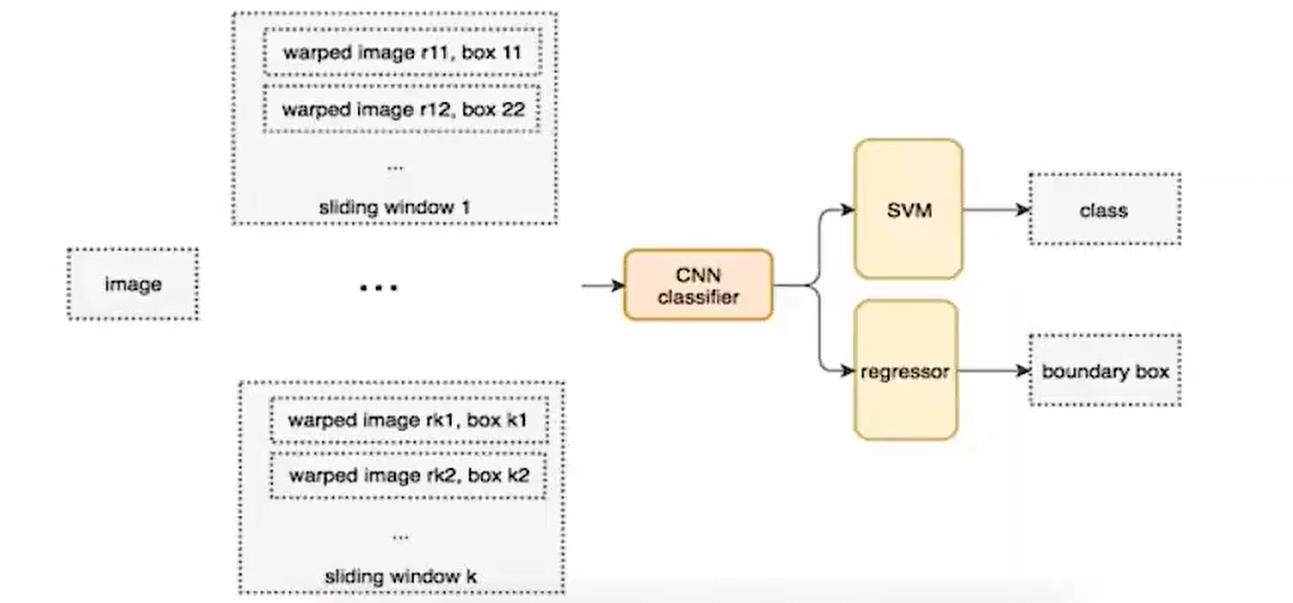
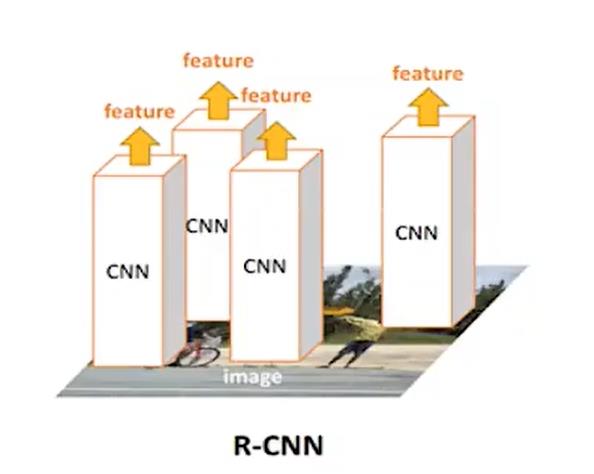
RCNN
那么这个时候,你可能会想了,刚刚的问题难度在于我们很难去得到这些框,因为做分类对我们来说还是非常简单的事情,但是做检测,偏偏有个预测框很难弄。如果我们可以直接得到一堆候选框,然后对每一个框所属的类别进行预测之后再采用某一种方法去筛选出合适的框不久变得简单了嘛。
那么这个时候RCNN出现了,在2014年的时候,那个时候我应该还是个小学生。它的流程是这样的:
- 对于一张图片,找出默认2000个候选区域
- 2000个侯选区域做大小变换,输入AlexNet当中,得到特征向量 [2000,4096]
- 经过20个类别的SVM分类器,对于2000个候选区域做判断,得 到[2000,20]得分矩阵
- 2000个候选区域做NMS,取出不好的,重度高的一些候选 区域,得到剩下分数高,结果好的相
- 修正候选框,bbox的回归微调
那么现在既然提到了RCNN,那么我们现在就不得不先提到两个概念了,第一是IOU,第二是NMS算法也就是那个筛选算法。
不过在这里我先说一些IOU,因为NMS在代码阶段会详细介绍,我们需要手动实现这个算法,当然IOU也需要,但是它非常简单。
就是这个东西
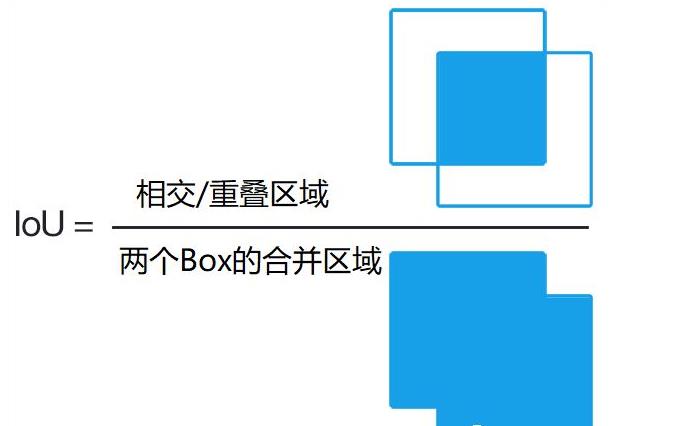
我们可以用这个玩意来衡量这两个生成的框是不是重合了,重合了多少,如果重合太多的话,是不是说他们两个框都在预测同一个物体,那么我们就可不可以把概率低的给干掉。而这个的话其实也是NMS的思想,具体还是看下文。
那么这里解决了可以自动生成框的问题,但是这里的分类器用的还是SVM,并且这个SVM肯定也是需要先训练好的,不然很难完成分类呀。而且在训练SVM的时候,我们是把经过了一个神经网络的数据给SVM的,那么意味还需要对AlexNet做处理,需要缓存很多中间数据然后训练。
而且每一个框都要进入神经网络,2000个要进去似乎也没有比暴力好到那儿去。
SPPNet
前面说了RCNN,其实最大的一个改进相对于滑动窗口来说,似乎就是多了一个方式去生成候选框。实际上后面那些SVM我们也未尝不可以和AlexNet直接合并成一个大网络然后对2000个候选框做分类,而不是分开来。
但是最大的问题并不是这个,问题在于我们还是需要进入2000次卷积。
那么有没有办法可以减少卷积咧,有SPPNet!
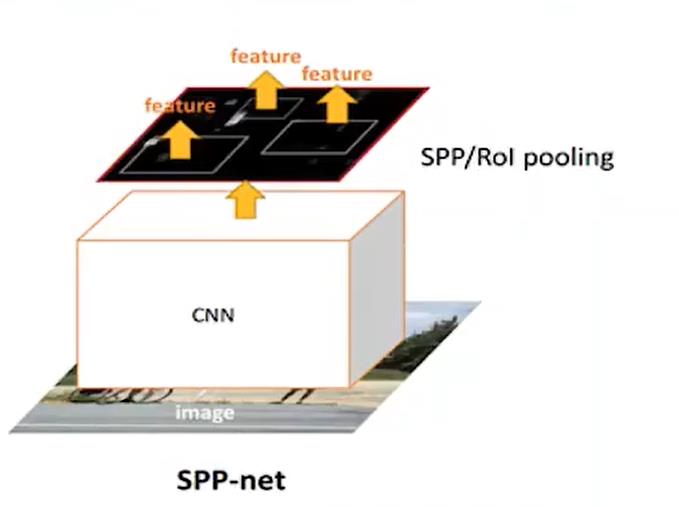
首先候选框还是咱们RCNN那种方式提取出来的,但是它直接把一张图片输入进一个卷积里面。
然后得到一个特征向量,之后这个特征向量里面包含了原来的候选框的信息,他们之间存在这样的映射关系:
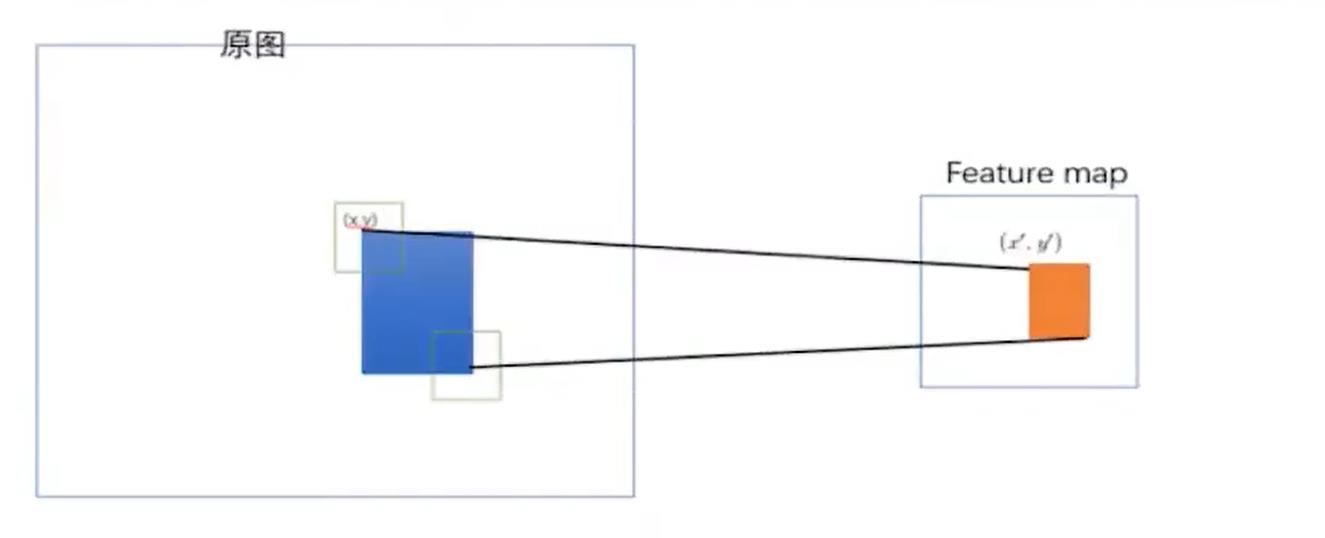
这个映射关系的不是咱们的重点,这里就忽略了,感兴趣的可以自己去了解,不够这个拿到feature map 绝对是目标检测史上最重要的一点之一!不过在这里还没有太大体现。
那么后面的操作其实就和RCNN类似了,只是中间又加了一些池化等等操作
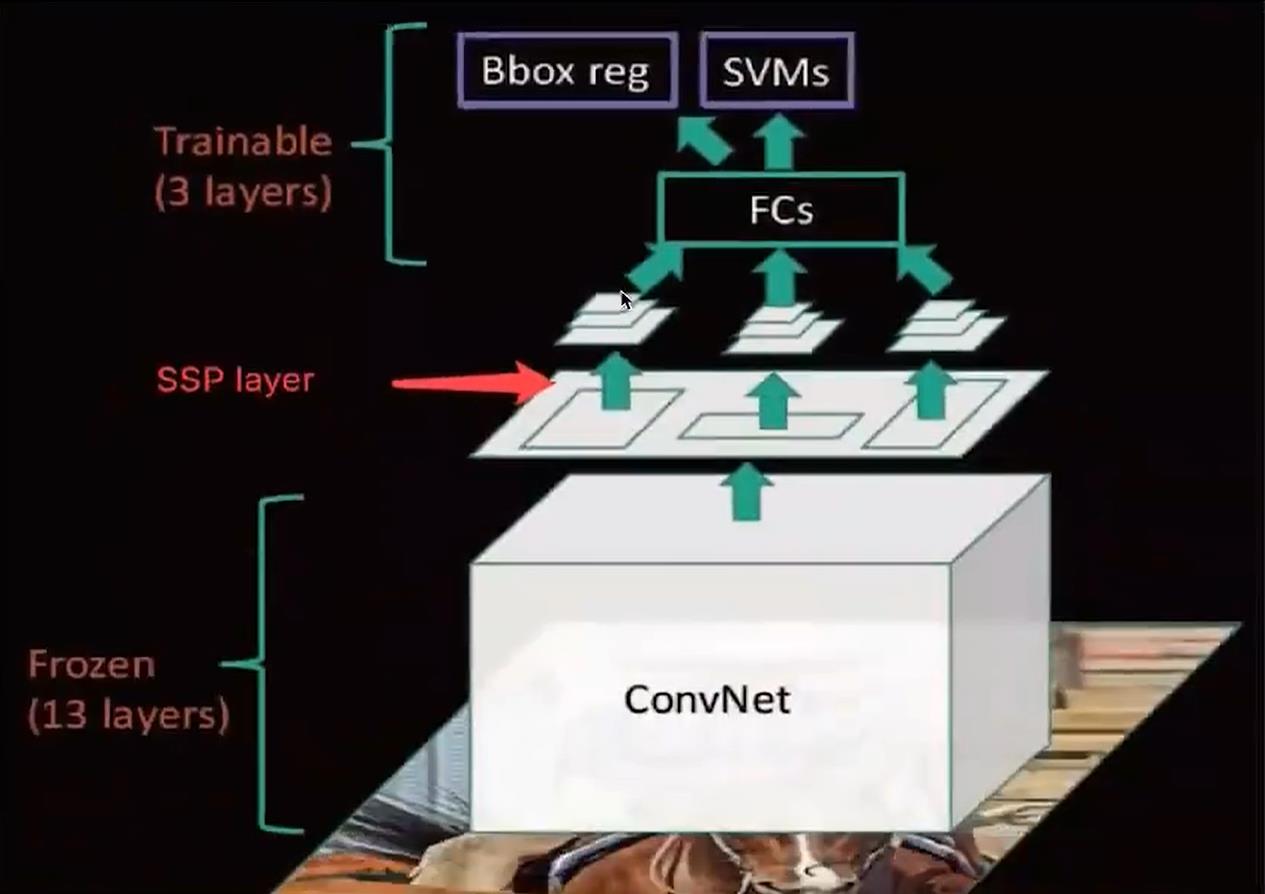
至于缺点:
1. 训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
2. 分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器,SPPNet)反向传播效率 低
Fast-RCNN
当我把标题单独放在外面的时候,我想你应该知道了这玩意的重要性。
来我们直接看到整个图:
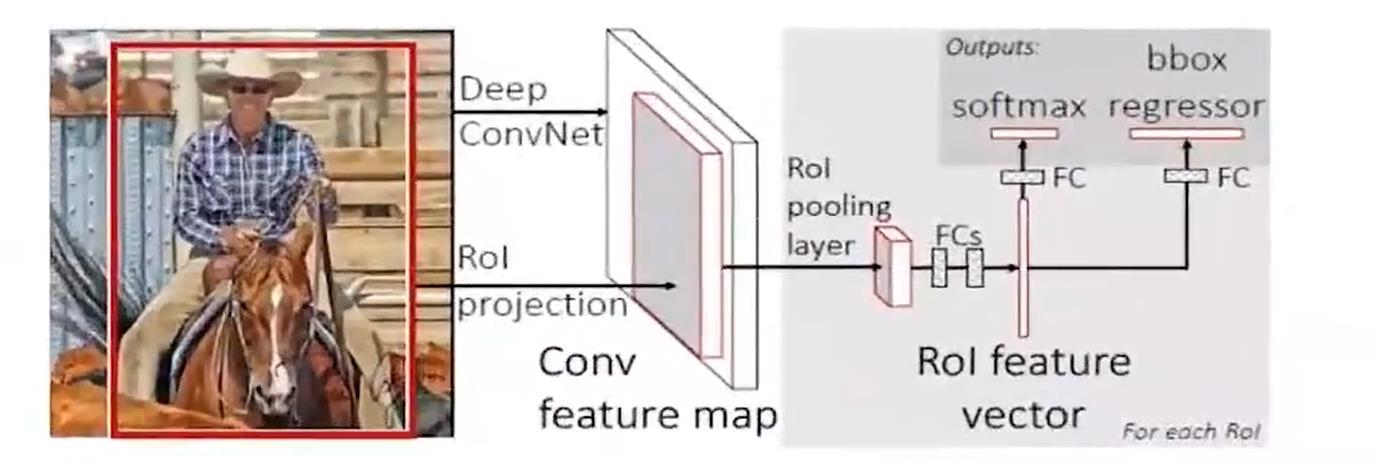
前面的部分其实和SPPNet很像,也就是一个卷积,但是后面全部变成 net,这个好像有点像咱们一开始瞎扯提到的方式了,也就是在后半部分。不过有点可惜的是总体上FastRCNN 的改进其实是把SPPNet后面的东西改了,前面的候选框其实还是使用RCNN的那一套机制,也就是SS算法。
不够尽管如此,fast rcnn 总算是和咱们现在的目标检测算法的样子有点像了,因为我们终于废弃了SVM,终于让我们的神经网络去做更多的事情了。
并且提到了咱们的多任务损失,而且不用把网络拆来了训练了,而是可以做到端到端了。
并且速度有了很大的提升
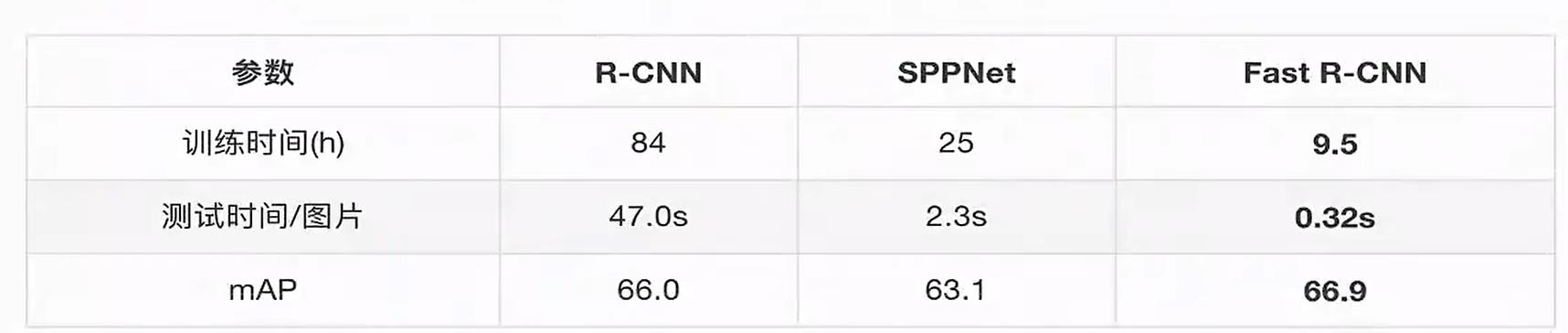
之后它的网络图是这样的:
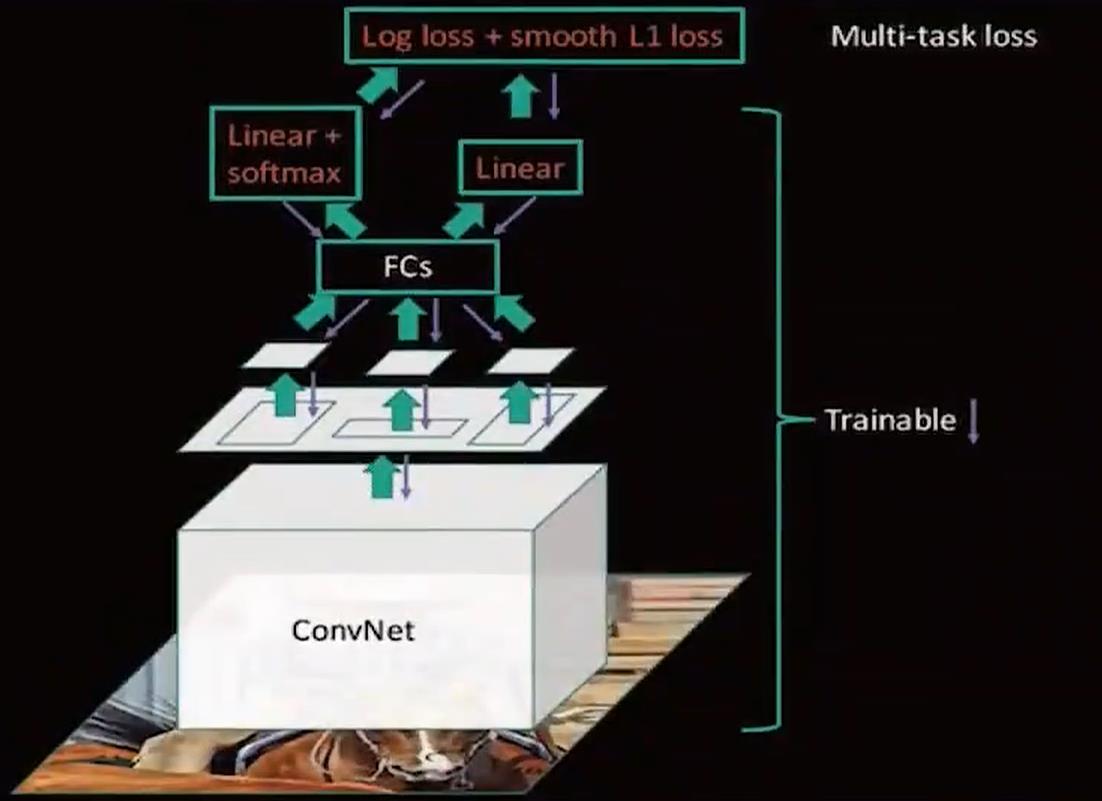
那么虽然已经很快了,那么还有办法嘛?原来RCNN 可是2000个候选区域啊。能不能缩减!有没有办法?
(这里面还有很多细节没有提到,需要读者自行搜索,不过不影响本文观看)
答案是有!
Faster RCNN
前面我们的FastRCNN 已经让神经网络做了很多事情了,那么为什么不能把候选框的提取也做了,让神经网络做到更多的事情?并且还有哪些东西是可以加强改进的?feature map 能不能利用起来?
嘿!还真能。
我们直接在feature map上面做提取,在上面生成候选区域,然后再执行后续操作,后续操作和咱们fast rcnn是一样的,我们只需要对这些候选框和分类器处理。于是我们的网络结构就变成了这样
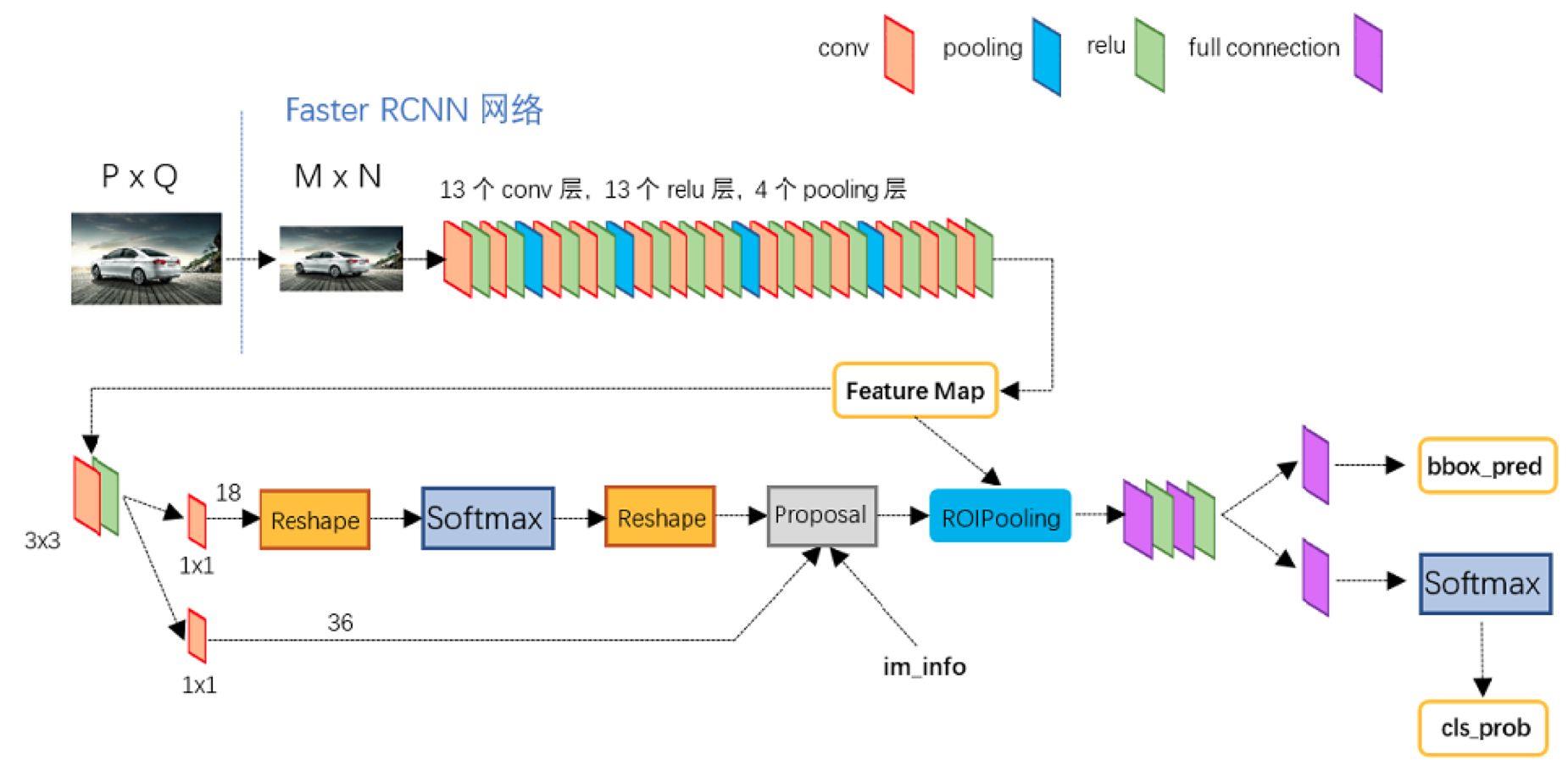
在feature后面提取的网络叫做RPN
RPN 工作流程
说到这个玩意咱们就必须提一下,因为这个东西的工作流程绝对是非常重要的,这意味着我们可以做出更大的改进在后面!
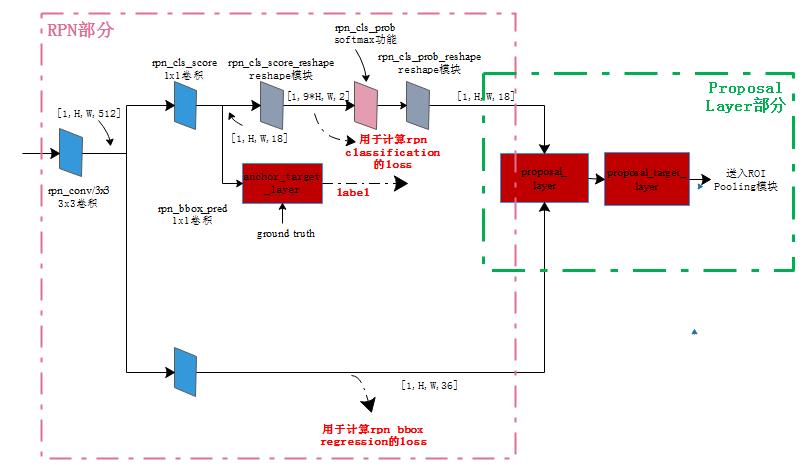
我们知道它的工作地方实在feature map上面
那么他如何工作呢。
这里引入一个名称叫做anchor 其实也就是bbox,那个预测框。
他是这样的,在那个feature map 的基础上,每一个网格,都会生成9个框,假设那个特征是20x20 的那么他有9个就是20x20x9 如果要具体表示的话,xmin,ymin,xmax,ymax(左上角,右下角)那就是20x20x36的张量
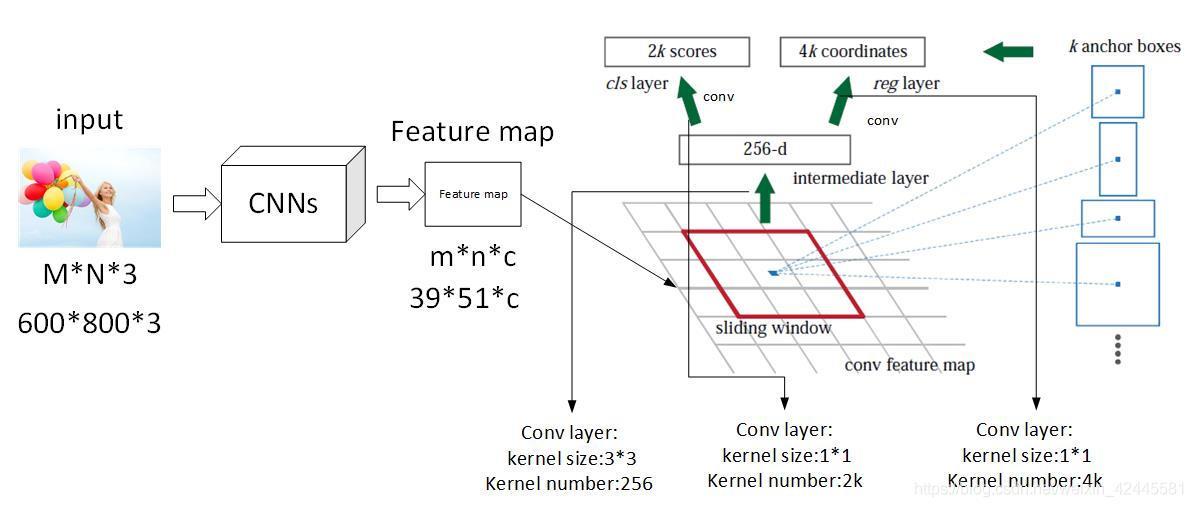
那么这里为什么是9个呢,因为是这样的,原作者设计了三种比例三种大小的样式,因为图片当中物体的大小是不一样的。
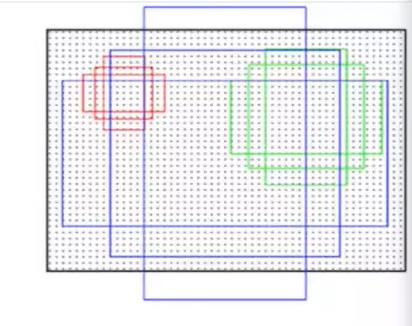
那么刚好对应的就是9个组合。之后的部分我就不细说了。
Yolo
那么到这里,你可能又有疑问了,那个RPN一样的网络能不能放在featur map 前面呢?如果我一开始就指定好图片的网格,然后不同的网格去生成候选框会怎么样?
没错大名鼎鼎的yolo出来了:(这里是v1)
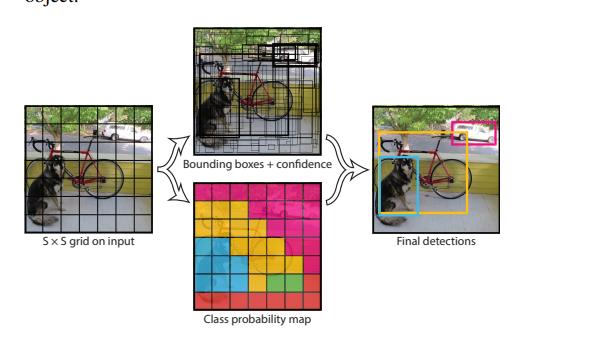
我先直接这样认为分成7x7的格子然后每个格子产生候选框,这里是2个候选框。
之后得到7x7x30的张量.
这里解释一下30里面包含了啥。
这里面存储了 两大类信息。
第一个 是 边框信息,起点,宽高,可信度。
第二个是 类别的条件概率,这里主要是20个类。
之后我们通过NMS对这些候选框进行筛选。
然后进入损失函数,这部分我们后面说,它的损失函数是这样的

我们接下来要自制的目标检测框架其实也是基于yolov1的。
小结
那么对于理论部分我们就先到这里,这里面的话还是有很多细节是没有说到的,例如Fast rcnn 里面,我们NMS处理以后,我们的那些剩下的框虽然是知道了所属的分类,但是我们回归的时候我们是和那些手动标注的框进行回归?这部分我没有说,由于篇幅问题,这部分也是需要读者自行探索,其实读者也可以大胆猜测一下和IOU有没有关系咧?此外还有其他的优秀算法没有介绍到,比如SSD等等。
当然前面的大部分内容只是做了解即可,因为更加完整的将在代码部分进行。
编码
接下来我们将针对yolov1 算法进行实现然后将其封装进去咱们自己搭建的平台。
那么对我们的编码实现里面最主要的其实有三个大点:
- 图片数据怎么处理,怎么对图片进行预处理
- IOU, NMS 算法的具体实现
- 损失函数的设计
首先是咱们的第一点,对图片是否需要,如何进行预处理。
神经网络实现
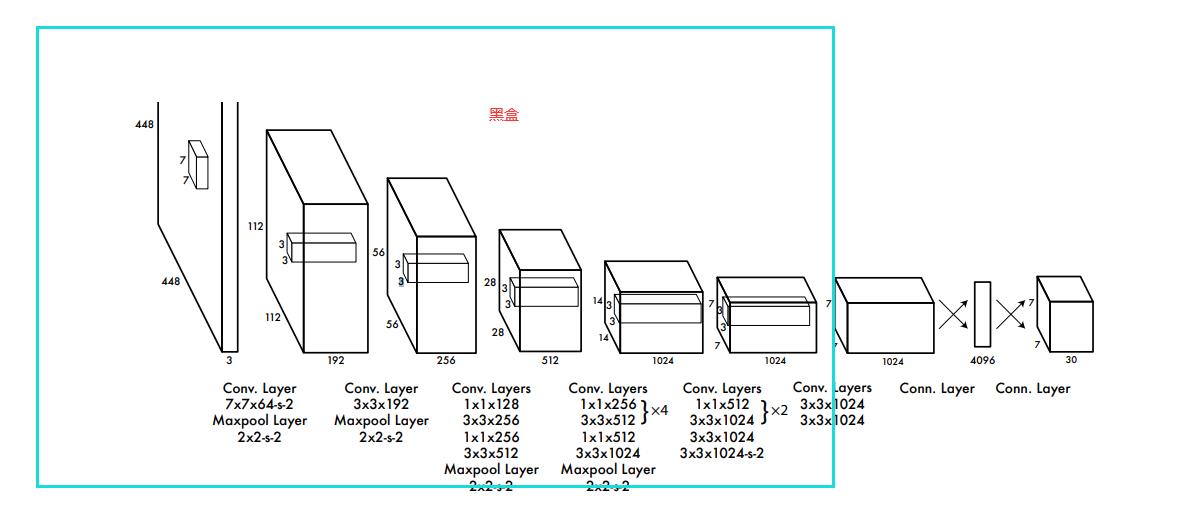
我们这边的话是打算直接集成yolov1的神经网络结构。
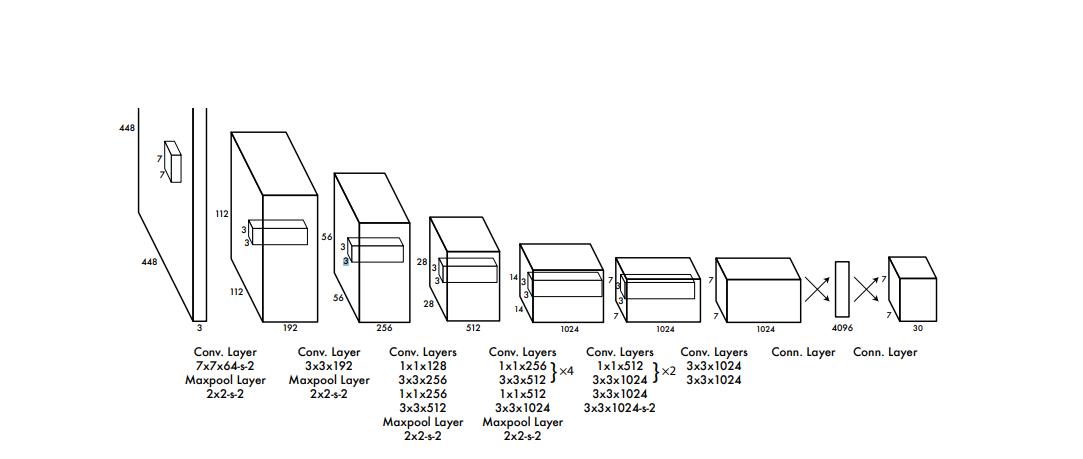
所以的话我们需要先编写神经网络。但是呢,为了更好地提高网络识别的精度和训练效率,我们这边还要考虑预训练一个神经网络模型。
所以为了实现这个效果我们需要对这个网络做一点点的改动,提取出一个骨干网络出来。
其中BackBone就是我们的核心网络,也就是其中的10几个卷积,后面两个一个是特征提取网络一个是我们用于目标识别的网络。我们预训练是训练特征提取网络,这个网络是依托与骨干网络的。他们之间的关系是这样的:

特征提取网络其实就是在骨干网络的基础上用于分类,这样一来就得到了权重,当我们训练目标检测网络的时候,我们可以把先前预训练的特征网络当中的骨干网络的权重提取出来作为初始化权重,这也就是迁移学习。
骨干网络
import torch.nn as nn
import torch
from collections import OrderedDict
class Convention(nn.Module):
def __init__(self,in_channels,out_channels,conv_size,conv_stride,padding,need_bn = True):
"""
这边对Conv2d进行一个封装,参数一致
但是多加了LeakReLU,和归一化,原因不多说了
:param in_channels:
:param out_channels:
:param conv_size:
:param conv_stride:
:param padding:
:param need_bn:
"""
super(Convention,self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, conv_size, conv_stride, padding, bias=False if need_bn else True)
self.leaky_relu = nn.LeakyReLU()
self.need_bn = need_bn
if need_bn:
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
return self.bn(self.leaky_relu(self.conv(x))) if self.need_bn else self.leaky_relu(self.conv(x))
def weight_init(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
class BackboneNet(nn.Module):
"""
骨干网络,因为那个论文中也提到了预训练的概念
那么这个预训练其实是说训练这个骨干网络,而这个
网络的话其实是7x7x30的前半部分
那个yolo是24卷积+2个全连接得到7x7x1024之后flatten4096
最后变成7x7x30,然后就是NMS,预训练需要先训练一个
分类的网络,所以这部分是不一样的
"""
def __init__(self):
super(BackboneNet,self).__init__()
"""
用于特征提取的16个卷积
"""
self.Conv_Feature = nn.Sequential(
Convention(3, 64, 7, 2, 3),
nn.MaxPool2d(2, 2),
Convention(64, 192, 3, 1, 1),
nn.MaxPool2d(2, 2),
Convention(192, 128, 1, 1, 0),
Convention(128, 256, 3, 1, 1),
Convention(256, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
nn.MaxPool2d(2, 2),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 256, 1, 1, 0),
Convention(256, 512, 3, 1, 1),
Convention(512, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
nn.MaxPool2d(2, 2),
)
self.Conv_Semanteme = nn.Sequential(
Convention(1024, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
Convention(1024, 512, 1, 1, 0),
Convention(512, 1024, 3, 1, 1),
)
这里可以看到这个网络啥也没有,就是一个最基本的骨架。
特征提取网络(预训练)
import torch
import torch.nn as nn
from Models.Backbone import BackboneNet, Convention
class YOLOFeature(BackboneNet):
def __init__(self,classes_num = 20):
"""
原文说的就是20个所以咱们也就来个20
:param classes_num:
"""
super(YOLOFeature,self).__init__()
self.classes_num = classes_num
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.linear = nn.Linear(1024, self.classes_num)
def forward(self, x):
x = self.Conv_Feature(x)
x = self.Conv_Semanteme(x)
x = self.avg_pool(x)
x = x.permute(0, 2, 3, 1)
x = torch.flatten(x, start_dim=1, end_dim=3)
x = self.linear(x)
return x
"""
初始化权重
"""
def initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight.data)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.kaiming_normal_(m.weight.data)
m.bias.data.zero_()
elif isinstance(m, Convention):
m.weight_init()
目标检测网络
最后是咱们的目标检测网络。
import torch.nn as nn
import torch
from Models.Backbone import BackboneNet, Convention
class YOLO(BackboneNet):
def __init__(self, B=2, classes_num=20):
super(YOLO, self).__init__()
self.B = B
self.classes_num = classes_num
self.Conv_Back = nn.Sequential(
Convention(1024, 1024, 3, 1, 1, need_bn=False),
Convention(1024, 1024, 3, 2, 1, need_bn=False),
Convention(1024, 1024, 3, 1, 1, need_bn=False),
Convention(1024, 1024, 3, 1, 1, need_bn=False),
)
self.Fc = nn.Sequential(
nn.Linear(7 * 7 * 1024, 4096),
nn.LeakyReLU(inplace=True, negative_slope=1e-1),
nn.Linear(4096, 7 * 7