微信读书这样排版,看过的人都很难忘!
Posted 腾讯云开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微信读书这样排版,看过的人都很难忘!相关的知识,希望对你有一定的参考价值。
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
在 微信读书 App 中,排版引擎负责解析 EPUB 或 TXT 格式的书籍源文件,将排版后的书籍内容如文字、图像、注解等元素渲染至屏幕上,是最常用、最复杂的组件之一。
而开发同学对排版引擎的日常修改,可能影响了海量书籍的排版结果。对排版引擎代码变更的测试,往往耗时多、难度大、容易漏测。本文介绍了为解决测试的难题,如何逐步将人工测试步骤自动化,最终构建了一套微信读书排版引擎自动化测试流程,以确保微信读书排版引擎的质量。
一.背景
1.排版引擎日常修改
为了获得极致的阅读体验,产品同学经常会提出细致的排版需求,交给开发同学修改。而排版引擎的修改,往往牵一发动全身,可能导致书城上万本书籍排版结果受影响。
举个例子,有个需求是增加正文段落的 margin:

再举个极端的例子,有个需求要把章节标题往右移动1个像素:

那么,如何确保微信读书的排版质量?最开始,我们用人工测试的方法来确保质量。
2.人工测试方法
当开发按需求修改排版引擎、自测后,会把代码提交到 svn,然后交给测试同学进行测试。
测试同学使用持续集成工具编译打包,得到排版引擎修改后的 App 安装包;然后在两台设备安装排版引擎修改前、后两个版本的 App,同时打开需要测试的书籍,翻页,对比,通过肉眼观察排版差异是否符合预期。
人工测试方法比较耗时,需要打开每本书,一页一页地翻页、对比,而且无法覆盖很多书籍,存在漏测的风险。
另外,通过人眼检查两台设备上的排版结果有没有差异,是很困难的任务,一是容易疲惫导致判断失误,二是对细致的排版变更(如第二个例子)很难判断是否符合预期。
为什么需要自动化测试?
前面提到,人工测试费时耗力,且容易漏测。
此外,排版需求的特点是细节多、变更快,且修改影响范围大,全网书籍上万本,无法一一验证。一旦出错,直接影响口碑。这些因素都增加了人工测试的工作量和压力。
除了精细化的排版需求会对排版引擎代码做修改,在日常的维护中,也会重构排版引擎、修改排版引擎相关但不影响排版结果的代码。每次重构、修改后,也会交给测试同学验证此次修改对排版结果没有影响。由于人工测试比较耗时、无法一一验证,每次重构排版引擎代码压力很大,轻易不敢改动。
还有一种情况,是在开发其他需求、修复缺陷时,意外地导致排版结果受影响。这种错误一旦发布到现网,后果很严重。
所以,把人工测试流程自动化十分有必要。自动化以后,可以大大减少人工测试的时间,同时方便开发同学自测。开发同学对排版引擎也可以大胆重构、持续改进代码质量。最终,达到确保排版引擎质量的目的。
二.如何自动化测试?
首先,我们要分析一下,在人工测试中,主要有哪些步骤?每个步骤是否能自动化?
在人工测试中,对每次变更的测试,有步骤如下:
- 需要把变更前、变更后的 App 包安装到两台设备
- 打开 App,登录,把要测试的书购买、加入到书架
- 打开要测试的书,设置排版偏好,翻页,用眼睛查看屏幕上的排版结果,对比屏幕中的排版结果是否有差异
- 如果有差异,根据需求判断差异是否符合预期
其中步骤 1、2 利用自动化测试工具是比较容易完成的。步骤 3 借助算法能够使其自动化,会在后面详细展开。步骤 4 自动化的难度比较大,可能需要借助非常高阶的人工智能完成,我们把这个步骤交给测试和开发同学。
那么,如何完成步骤 3 的自动化,让机器做人类的事情呢?我们把它再细分成三个步骤:
1. 获取排版结果的数据表示
首先,需要找到一种机器能读懂的数据表示,这种数据表示要既能够表示排版的结果、反映代码的修改,也能够通过算法来对比,对比的结果要便于可视化的展示,方便开发、测试同学判断差异是否符合预期。
我们的选择有:
- NSAttributedString,是从 EPUB、TXT 处理后得到的中间数据,包括文字和排版样式。这种数据结构比较抽象,没有一种很好的差异计算方法、和差异结果可视化方法。
- 阅读器屏幕截图,位图格式,借助各种成熟的数字图像处理算法,容易计算差异
考虑到 2 容易计算差异,可视化输出效果较好,我们选取阅读器屏幕截图作为数据表示。
2. 对比图像差异
选择了图像作为排版结果的数据表示,那么如何对比图像差异呢?
首先,我们要选取图像特征,然后才能对比图片差异。图像的特征,从视觉认知概念上,有低、中、高级特征:
- 低级特征:如像素域、频率域、ImageHash
- 中级特征:如 sobel 边缘特征
- 高级特征:抽象视觉概念,比如从 CNN 算法训练得到的标签,如车、枪、球
这里我们希望每个像素的差异都能检测到,所以选取像灰度化处理过的图像矩阵作为特征。
有了特征后,我们需要定义差异,就是两个灰度图像矩阵的距离函数,如:
- L0,表示两个灰度图像矩阵之间,不一致的像素点的个数
- L1,曼哈顿距离或棋盘距离,不一致像素点差值的绝对值之和
- L2,不一致像素点差值的平方和
我们关心有多少像素点不一致,所以我们这里取 L0距离,即两个图像有多少个像素点不一样,作为差异衡量的指标。
当距离大于10时,我们认为这一页的排版结果有差异,把它可视化输出,给开发或者测试同学作为参考。
3. 可视化输出
检测到差异后,我们把两个图像矩阵灰度化后相减,得到一个新的矩阵,把它归一化得到差异图像,如右图所示:

三.通过 scheme 生成排版结果
人工测试步骤 2、3 的书籍购买、加入书架、打开书籍、翻页、截图等任务,可以利用 Instrument UI Automation 自动测试脚本来模拟人工点击来完成任务。
但是考虑到 Automation 模拟翻页、截图速度慢,且 UI 变更频繁导致 Automation 脚本后续维护麻烦等问题,所以我们通过提供一个测试 scheme 接口来完成这个任务。
在 App 设置彩蛋的『执行 Scheme 页面』中,输入 scheme 并执行后,App 会在后台对指定书籍购买、加入书架、排版、生成排版结果截图,并把结果保存在本地磁盘。用户也可以选择 AirDrop 到 Mac 上。

运行scheme
scheme 格式如下:
weread://typeset?books=三体,乔布斯传,失控,1984,乌兰拖拉机简史&indent=1&fontSize=2&font=2&theme=3&folder=f1223
输出排版结果到目录/Libary/[vid]/[folder]/[bookId].zip
@param books 需要排版的书单
@param indent 0首行不缩进 1首行缩进,默认0
@param fontSize 1,2,3,4,5,6,7 字体大小,默认4
@param font 字体 1系统字体 2 3 4 为对应选项字体,默认1
@param bgcolor 背景颜色 1白 2黄 3绿色 4夜间,默认1
@param folder 输出文件夹名,默认"cropImage"
通过这个 scheme,在真机或者模拟器都可以随时得到排版结果,而且速度比模拟翻页要快10x。
四.自动化测试流程
下面,将介绍我们完整的排版引擎自动化测试流程。
1. 生成排版结果
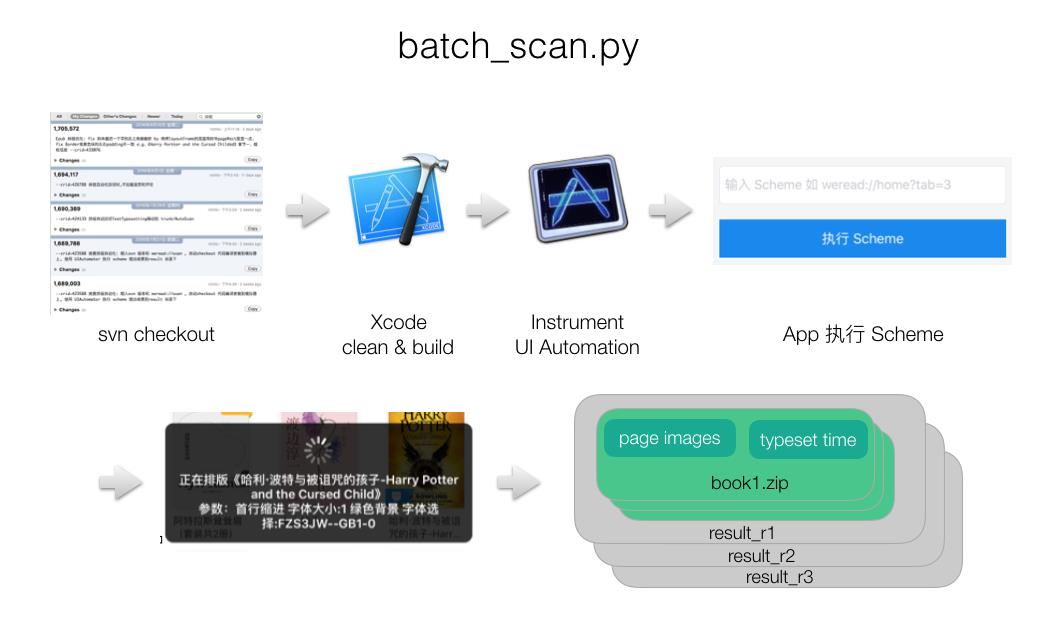
首先,用户需要确定参数:待生成排版结果的 svn 版本范围 r1~rn、书单、阅读偏好设置(字体、缩进、主题模式)。把这些参数传给脚本batch_scan.py,然后自动化流程开始,脚本会执行以下步骤:
- 在指定 svn 版本范围内,找出排版引擎有变更的版本,checkout
- 对每个 checkout 的版本,用 xcodebuild 编译项目,安装到模拟器
- 通过 Instrument 的 UI Automation 脚本,打开模拟器,运行微信读书App,进入到测试彩蛋页面:执行 scheme,生成排版结果
- 把结果从模拟器移动到指定的目录下
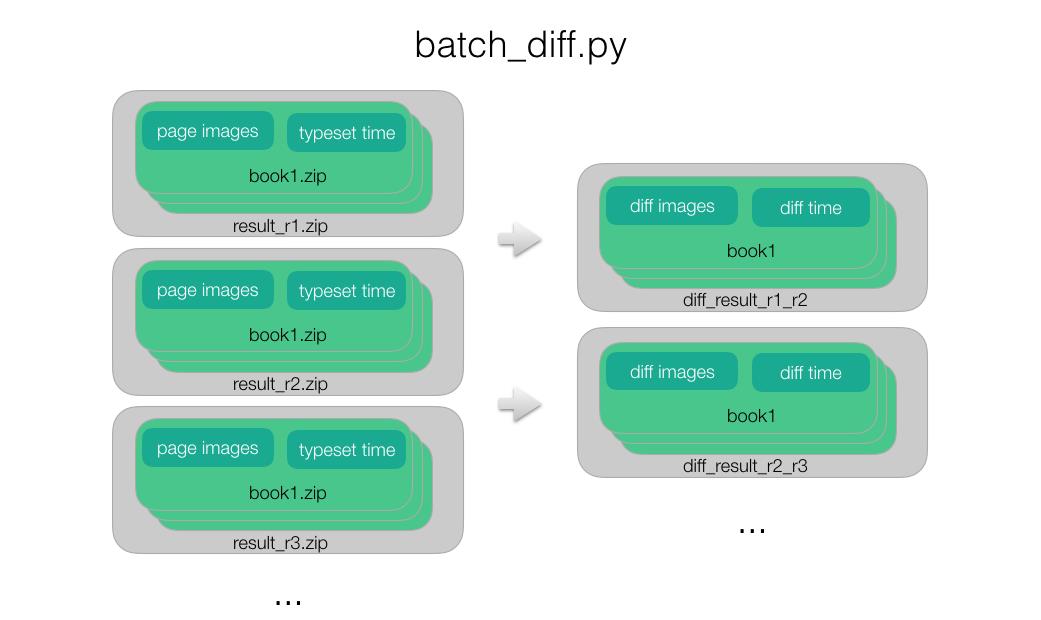
2. 生成排版结果差异
得到排版结果后,执行脚本 batch_diff.py,对相近的版本,每本书的每一页通过 diffimg.py 对比,如果有差异,则输出可视化的差异结果。
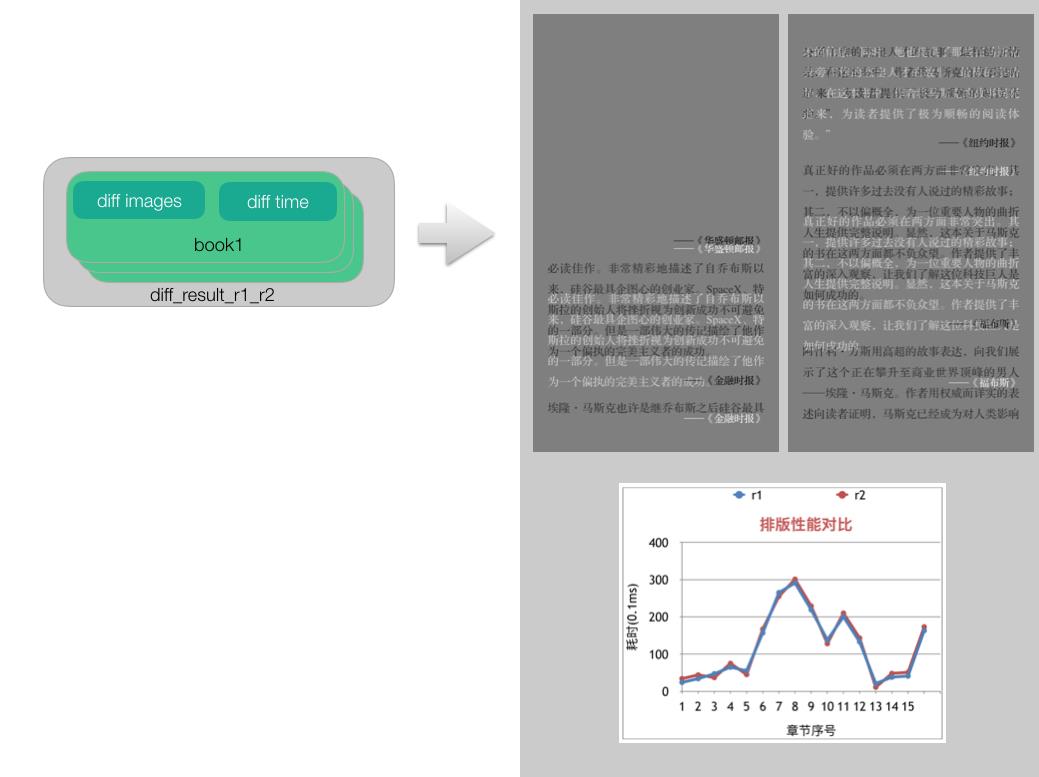
3. 人工检查差异
自动化流程结束后,我们得到排版结果差异,需要人工去检查差异是否符合预期。
我们以文件夹的形式组织展示差异的可视化结果:版本 r1(修改前)与 r2(修改后),对书籍 book1 排版差异可视化结果,保存在文件夹 diff_result_r1_r2/book1 中。
可视化结果图像中,深色字体是 r1 (修改前)的排版结果,浅色字体是 r2 (修改后)的排版结果。
另外,排版性能变化也纳入了监控。
五.自动化测试的优势
自动化流程的建立,使排版引擎的测试时间缩短了 95%,测试期间无需人工干预,对比数据如图:
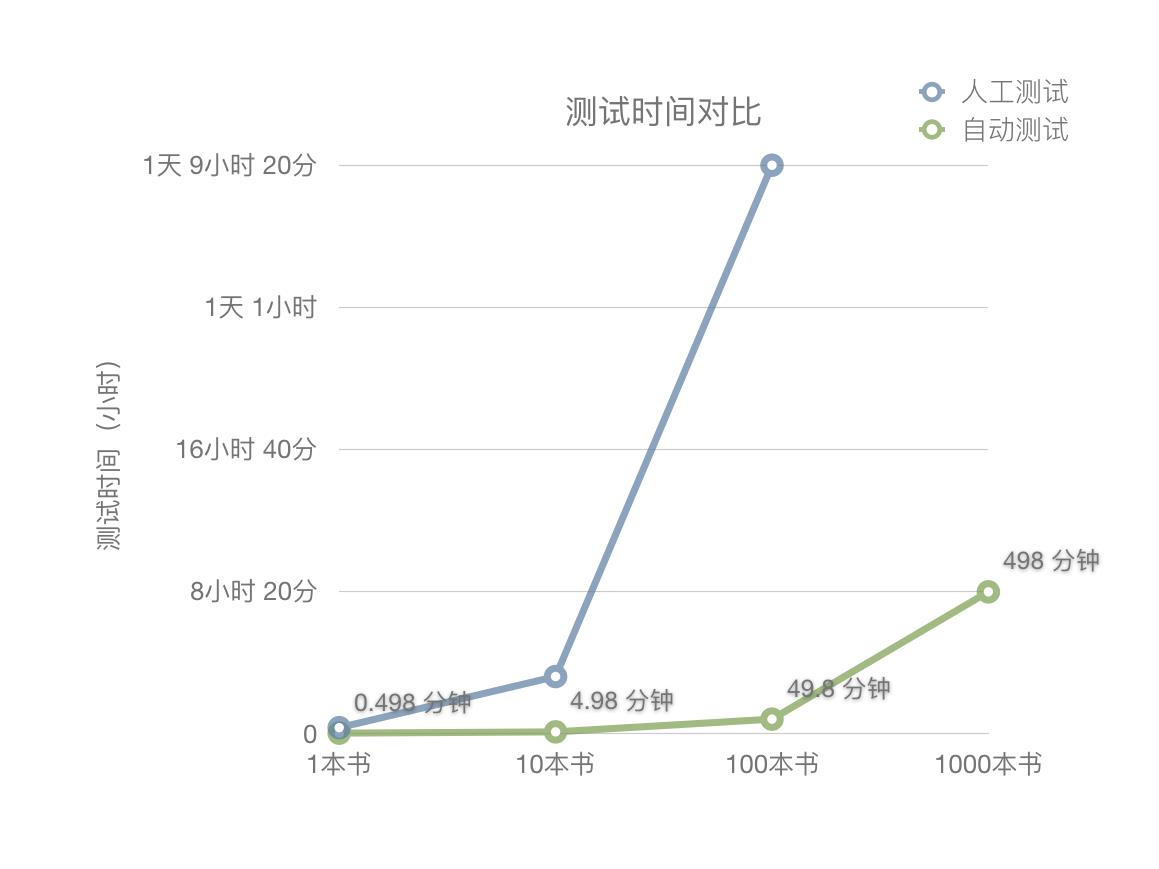
例如,人工测试一本 550页的 《哈利波特与被诅咒的孩子》需要约 20 分钟,而自动化测试脚本扫描、对比差异只需 22 秒(不含编译时间);人工测试 10 本书籍,用时约 3 小时,而自动化测试用时约 4.9 分钟;人工测试 100 本书籍需 33 小时,而自动化测试用时约 50 分钟。
除了大大减少人工测试的时间,开发同学借助自动化测试工具,能大胆重构代码,通过自动化测试来确保重构不影响排版结果,拥抱快速变更的需求。
随着自动化测试覆盖的变更版本、测试的书籍数量越来越多,带来的收益越大。
借助自动化测试流程,对于任何代码修改而导致样本书籍、每一页、每个像素点的排版结果变更,都能够纳入我们的监控,最终达到确保微信读书排版引擎质量的目的。
六.未来工作
目前,自动化测试工具已经投入使用。未来会持续优化、增加特性,以满足测试、开发同学的需求。
未来工作包括但不限于
邮件通知:执行脚本得到结果后,如果两个版本之间的排版结果有差异,通过邮件通知相关同学;另外,排版的性能对比结果也可以生成一份报告,通过邮件通报。
运行速度优化:目前对 20 本书生成排版结果,耗时约 10 分钟,对比耗时约 2 分钟。可以进一步优化运行速度,争取覆盖更多样本书籍
支持微信读书安卓版
尝试应用在其他模块:对运行预期结果相对固定、测试代价大的功能模块,可以通过支持测试 scheme,输出运行结果截图,以插件的形式接入这一套自动化测试流程。
七.总结
本文介绍了微信读书排版引擎的日常修改时,人工测试所面临的问题,以及为什么需要自动化测试的原因。
然后本文分析了人工测试的流程,以及这些流程改造成自动化的可能性。
最后,介绍了我们整套自动化测试流程,以及应用自动化测试以后所来的好处,最终达到确保微信读书排版引擎质量的目的。
问答
REST API的自动化测试如何实现?
相关阅读
AI 精彩视频剪辑:战术竞技类游戏直播
尝试改进微信读书个性化推荐:一个基于 CTR 预估的方法
【腾讯TMQ】基于模型的自动化测试工具:GraphWalker
【每日课程推荐】机器学习实战!快速入门在线广告业务及CTR相应知识
此文已由作者授权腾讯云+社区发布,更多原文请点击
搜索关注公众号「云加社区」,第一时间获取技术干货,关注后回复1024 送你一份技术课程大礼包!
海量技术实践经验,尽在云加社区!
以上是关于微信读书这样排版,看过的人都很难忘!的主要内容,如果未能解决你的问题,请参考以下文章